Implementación del modelo Gamma-gamma en PyMC por el desarrollador#
Referencia: Fader, P. S., & Hardie, B. G. (2013). El modelo Gamma-Gamma del valor monetario. Febrero, 2, 1-9.
http://www.brucehardie.com/notes/025/gamma_gamma.pdf
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import pytensor.tensor as pt
import seaborn as sns
from pymc_marketing import clv
Simular datos#
rng = np.random.default_rng(42)
# Hyperparameters
p_true = 6.
q_true = 4.
v_true = 15.
# Number of subjects
N = 500
# Subject level parameters
nu_true = pm.draw(pm.Gamma.dist(q_true, v_true, size=N), random_seed=rng)
# Number of observations per subject
x = rng.poisson(lam=2, size=N) + 1
idx = np.repeat(np.arange(0, N), x)
# Observations
z = pm.draw(pm.Gamma.dist(p_true, nu_true[idx]), random_seed=rng)
print(sum(x))
assert len(nu_true[idx]) == sum(x)
1503
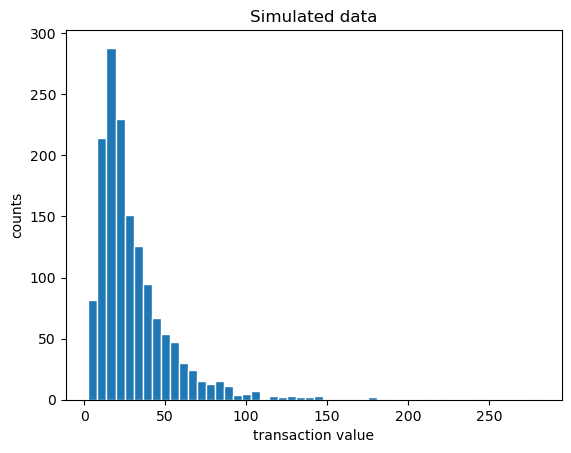
plt.hist(z, bins=50, ec="w")
plt.xlabel("transaction value")
plt.ylabel("counts")
plt.title("Simulated data");
df = pd.DataFrame(data={"individual_transaction_value": z, "customer_id": idx})
z_mean = df.groupby("customer_id").mean()["individual_transaction_value"].values
z_mean[:10]
array([ 17.5597973 , 41.05272046, 15.90609488, 83.95307047,
20.36896009, 23.8572992 , 46.09000842, 47.49876237,
131.16095313, 16.42659393])
Implementación de PyMC#
Podemos utilizar la implementación preconstruida de PyMMMC del modelo Gamma-Gamma, que también ofrece métodos de graficado y predicción atractivos.
Usando transacciones individuales 𝑧#
model = clv.GammaGammaModelIndividual(data = df)
model
Gamma-Gamma Model (Individual Transactions)
p ~ HalfFlat()
q ~ HalfFlat()
v ~ HalfFlat()
nu ~ Gamma(q, f(v))
spend ~ Gamma(p, f(nu))
model.build_model()
model.graphviz()

model.fit(random_seed=rng)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [p, q, v, nu]
100.00% [8000/8000 00:15<00:00 Sampling 4 chains, 0 divergences]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 16 seconds.
arviz.InferenceData
-
<xarray.Dataset> Dimensions: (chain: 4, draw: 1000, customer_id: 500) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 * customer_id (customer_id) int64 0 1 2 3 4 5 6 ... 494 495 496 497 498 499 Data variables: p (chain, draw) float64 6.043 6.218 6.028 ... 5.783 5.617 5.341 q (chain, draw) float64 3.977 4.26 3.962 ... 4.277 4.209 3.401 v (chain, draw) float64 14.94 15.73 15.36 ... 18.15 18.12 14.57 nu (chain, draw, customer_id) float64 0.204 0.1759 ... 0.1358 Attributes: created_at: 2022-12-15T08:50:41.657496 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.0 sampling_time: 15.84934139251709 tuning_steps: 1000 -
<xarray.Dataset> Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 ... 994 995 996 997 998 999 Data variables: (12/17) n_steps (chain, draw) float64 15.0 15.0 15.0 ... 15.0 15.0 max_energy_error (chain, draw) float64 0.6677 -0.3882 ... -1.41 1.565 lp (chain, draw) float64 -5.977e+03 ... -6.014e+03 process_time_diff (chain, draw) float64 0.005394 0.004418 ... 0.006559 tree_depth (chain, draw) int64 4 4 4 4 4 4 4 4 ... 4 4 4 4 4 4 4 index_in_trajectory (chain, draw) int64 8 -9 -6 3 -6 ... 9 -3 -7 11 -13 ... ... energy (chain, draw) float64 6.208e+03 ... 6.283e+03 perf_counter_start (chain, draw) float64 2.382e+03 ... 2.387e+03 reached_max_treedepth (chain, draw) bool False False False ... False False acceptance_rate (chain, draw) float64 0.6662 0.9528 ... 0.9918 0.559 step_size_bar (chain, draw) float64 0.2451 0.2451 ... 0.2524 0.2524 step_size (chain, draw) float64 0.2618 0.2618 ... 0.2271 0.2271 Attributes: created_at: 2022-12-15T08:50:41.673955 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.0 sampling_time: 15.84934139251709 tuning_steps: 1000 -
<xarray.Dataset> Dimensions: (obs: 1503) Coordinates: * obs (obs) int64 0 1 2 3 4 5 6 7 ... 1496 1497 1498 1499 1500 1501 1502 Data variables: spend (obs) float64 14.17 11.38 20.49 24.21 ... 33.88 31.51 49.41 30.51 Attributes: created_at: 2022-12-15T08:50:41.680915 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.0
az.plot_posterior(model.fit_result, var_names=["p", "q", "v"], ref_val=[p_true, q_true, v_true]);
expected_spend = model.expected_customer_spend(
customer_id=idx,
individual_transaction_value=z,
).stack(sample=("draw", "chain"))
Sampling: [nu]
100.00% [4000/4000 00:00<00:00]
# Choose 10 lowest, median and 10 highest spending clients
selected_idxs = np.argsort(nu_true)[::-1][[10, 250, -10]]
selected_idxs
array([267, 407, 359])
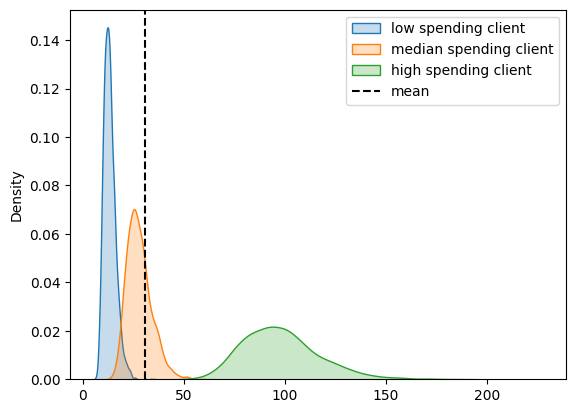
sns.kdeplot(expected_spend.sel(customer_id=selected_idxs[0]), fill=True, label="low spending client")
sns.kdeplot(expected_spend.sel(customer_id=selected_idxs[1]), fill=True, label="median spending client")
sns.kdeplot(expected_spend.sel(customer_id=selected_idxs[2]), fill=True, label="high spending client")
plt.axvline(expected_spend.mean(), color="k", ls="--", label="mean")
plt.legend();
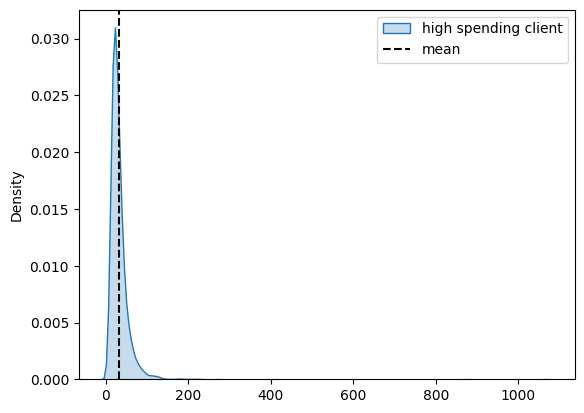
new_spend = model.expected_new_customer_spend().stack(sample=("chain", "draw"))
Sampling: [nu]
100.00% [4000/4000 00:00<00:00]
sns.kdeplot(new_spend.isel(new_customer_id=0), fill=True, label="high spending client")
plt.axvline(new_spend.mean(), color="k", ls="--", label="mean")
plt.legend();
Usando transacciones promedio por usuario \(\overline{z}\)#
model = clv.GammaGammaModel(
customer_id=idx,
mean_transaction_value=z_mean,
frequency=x,
)
model
Gamma-Gamma Model (Mean Transactions)
p ~ HalfFlat()
q ~ HalfFlat()
v ~ HalfFlat()
likelihood ~ Potential(f(q, p, v))
model.fit(random_seed=rng)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [p, q, v]
100.00% [8000/8000 00:19<00:00 Sampling 4 chains, 0 divergences]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 20 seconds.
arviz.InferenceData
-
<xarray.Dataset> Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 7 8 ... 992 993 994 995 996 997 998 999 Data variables: p (chain, draw) float64 8.287 6.904 11.12 11.37 ... 5.595 7.243 5.328 q (chain, draw) float64 3.116 3.177 3.585 3.381 ... 3.931 3.953 3.654 v (chain, draw) float64 8.172 10.5 7.579 6.657 ... 16.45 12.56 15.75 Attributes: created_at: 2022-12-15T08:51:18.981662 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.0 sampling_time: 19.611279487609863 tuning_steps: 1000 -
<xarray.Dataset> Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 ... 994 995 996 997 998 999 Data variables: (12/17) n_steps (chain, draw) float64 63.0 63.0 31.0 ... 63.0 31.0 max_energy_error (chain, draw) float64 6.796 0.5487 ... 0.8002 lp (chain, draw) float64 -2.067e+03 ... -2.063e+03 process_time_diff (chain, draw) float64 0.01295 0.01572 ... 0.006056 tree_depth (chain, draw) int64 6 6 5 5 6 6 4 5 ... 6 4 1 5 5 6 5 index_in_trajectory (chain, draw) int64 16 6 -13 6 -25 ... -1 3 10 -19 -8 ... ... energy (chain, draw) float64 2.071e+03 ... 2.067e+03 perf_counter_start (chain, draw) float64 2.414e+03 ... 2.425e+03 reached_max_treedepth (chain, draw) bool False False False ... False False acceptance_rate (chain, draw) float64 0.241 0.9067 ... 0.991 0.737 step_size_bar (chain, draw) float64 0.06783 0.06783 ... 0.07536 step_size (chain, draw) float64 0.08445 0.08445 ... 0.06033 Attributes: created_at: 2022-12-15T08:51:18.999668 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.0 sampling_time: 19.611279487609863 tuning_steps: 1000
az.plot_posterior(model.fit_result, var_names=["p", "q", "v"], ref_val=[p_true, q_true, v_true]);

expected_spend = model.expected_customer_spend(
customer_id=idx,
mean_transaction_value=z_mean,
frequency=x,
).stack(sample=("draw", "chain"))
Sampling: [nu]
100.00% [4000/4000 00:01<00:00]
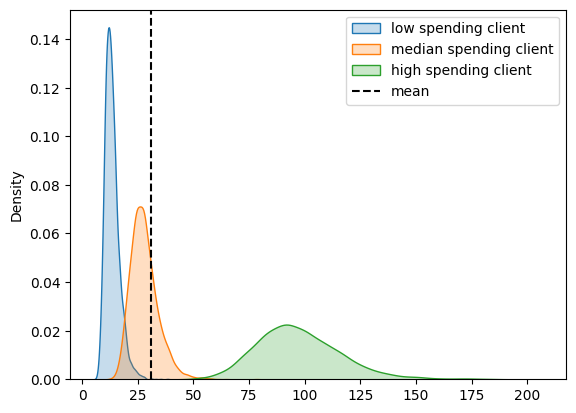
sns.kdeplot(expected_spend.sel(customer_id=selected_idxs[0]), fill=True, label="low spending client")
sns.kdeplot(expected_spend.sel(customer_id=selected_idxs[1]), fill=True, label="median spending client")
sns.kdeplot(expected_spend.sel(customer_id=selected_idxs[2]), fill=True, label="high spending client")
plt.axvline(expected_spend.mean(), color="k", ls="--", label="mean")
plt.legend();
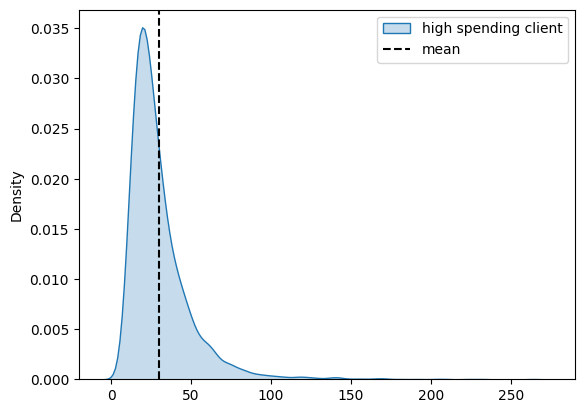
new_spend = model.expected_new_customer_spend().stack(sample=("chain", "draw"))
Sampling: [nu]
100.00% [4000/4000 00:00<00:00]
sns.kdeplot(new_spend.isel(new_customer_id=0), fill=True, label="high spending client")
plt.axvline(new_spend.mean(), color="k", ls="--", label="mean")
plt.legend();
Implementaciones manuales de PyMC#
Mostramos cómo se puede implementar el modelo Gamma-Gamma manualmente utilizando PyMC. Esto aclara cómo se puede modificar o extender el modelo para incluir más información previa o estructura adicional.
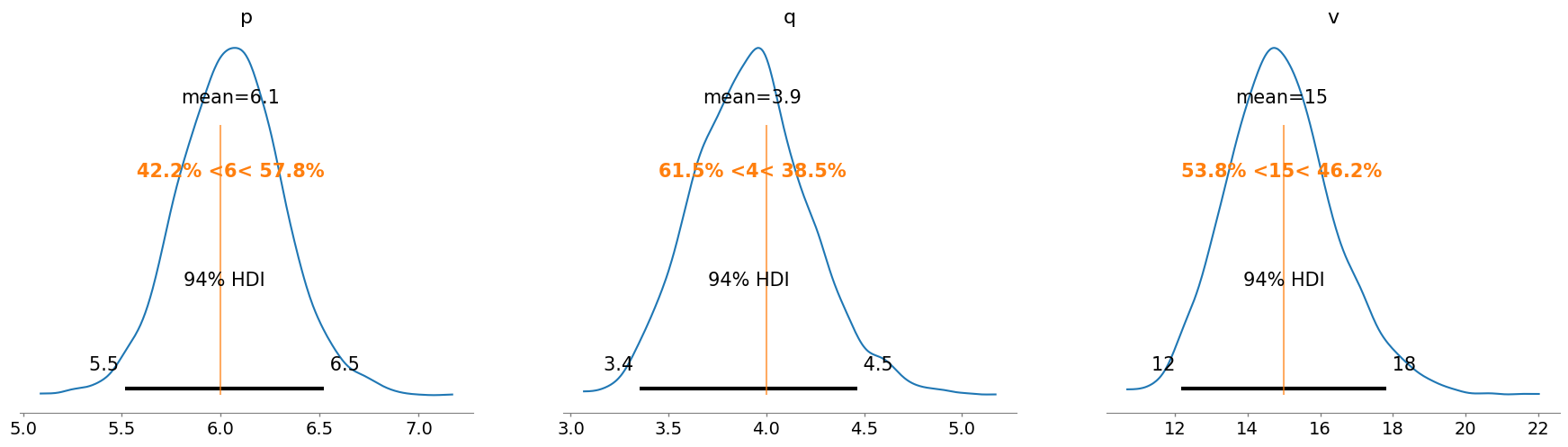
Modelo Gamma-Gamma condicionado a transacciones individuales \(z\)#
with pm.Model() as m1:
p = pm.HalfFlat("p")
q = pm.HalfFlat("q")
v = pm.HalfFlat("v")
nu = pm.Gamma("nu", q, v, size=N)
pm.Gamma("z", p, nu[idx], observed=z)
pm.Deterministic("mean_spend", p / nu)
trace1 = pm.sample(random_seed=rng)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [p, q, v, nu]
100.00% [8000/8000 00:20<00:00 Sampling 4 chains, 0 divergences]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 21 seconds.
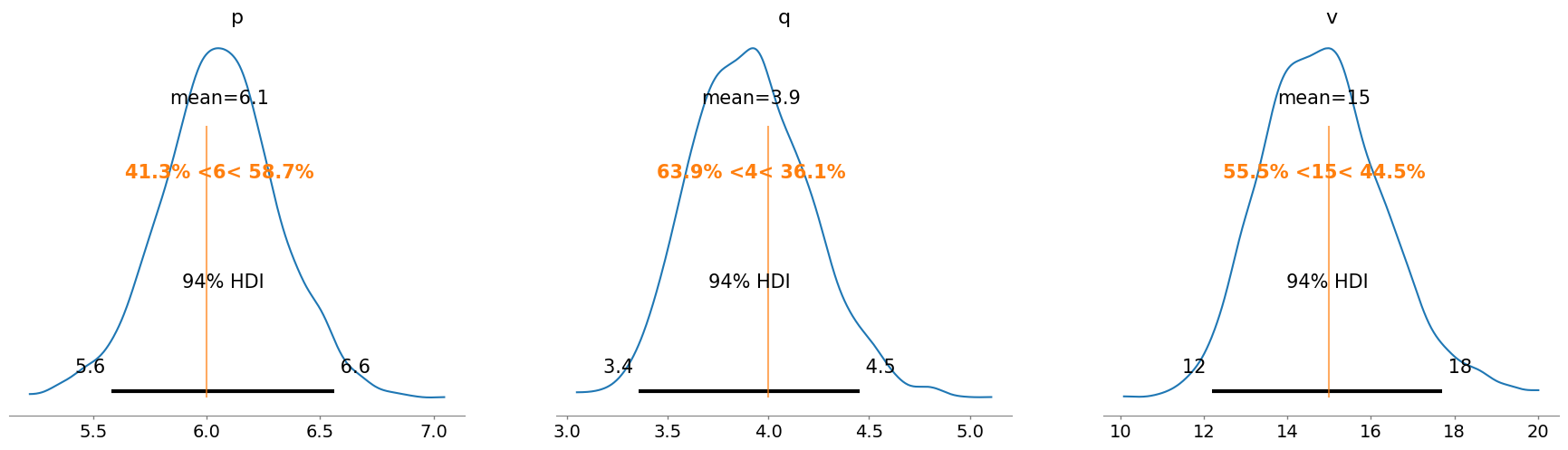
az.summary(trace1, var_names=["p", "q", "v"])
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| p | 6.055 | 0.260 | 5.578 | 6.564 | 0.020 | 0.014 | 178.0 | 382.0 | 1.02 |
| q | 3.914 | 0.295 | 3.358 | 4.453 | 0.007 | 0.005 | 1877.0 | 1959.0 | 1.00 |
| v | 14.879 | 1.486 | 12.194 | 17.717 | 0.071 | 0.050 | 438.0 | 1131.0 | 1.01 |
az.plot_posterior(trace1, var_names=["p", "q", "v"], ref_val=[p_true, q_true, v_true]);
Modelo gamma-gamma condicionado a las transacciones promedio por usuario \(\overline{z}\)#
Esto no puede muestrear porque el modelo contiene «casi» dos parámetros independientes por observación. Para más detalles, consulta este tema de Discourse
with pm.Model() as m2:
p = pm.HalfFlat("p")
q = pm.HalfFlat("q")
v = pm.HalfFlat("v")
nu = pm.Gamma("nu", q, v, size=N)
# We use the convolution properties of the gamma distribution to model
# the mean of multiple transaction using the parameters of individual
# transactions
pm.Gamma("z_mean", p*x, nu*x, observed=z_mean)
trace2 = pm.sample(random_seed=rng)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [p, q, v, nu]
100.00% [8000/8000 00:26<00:00 Sampling 4 chains, 0 divergences]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 27 seconds.
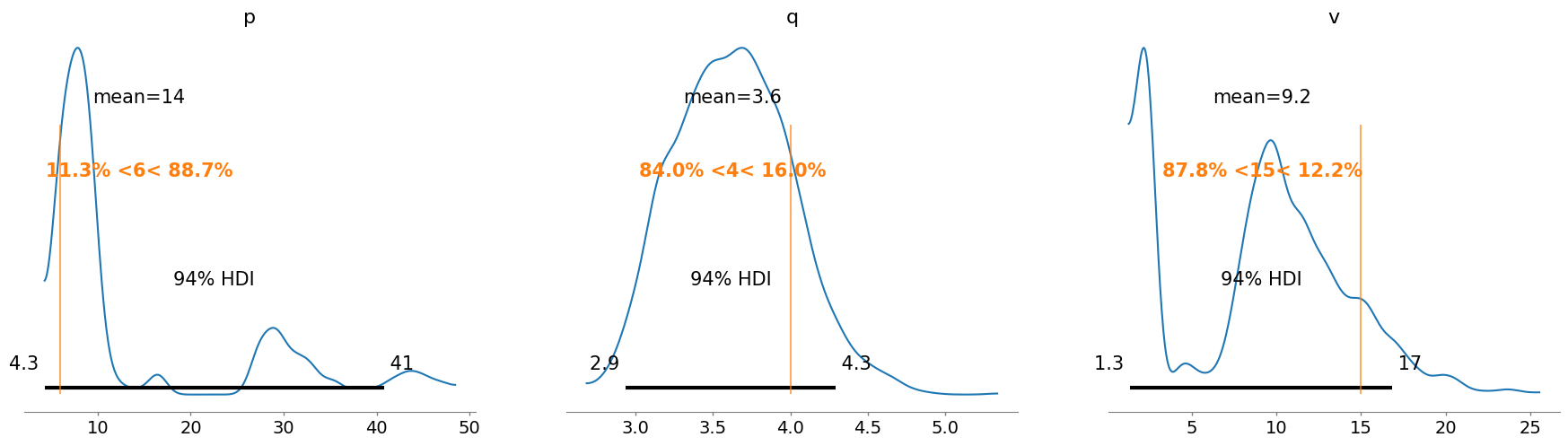
az.summary(trace2, var_names=["p", "q", "v"])
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| p | 14.454 | 11.819 | 4.299 | 40.762 | 5.738 | 4.375 | 5.0 | 11.0 | 2.17 |
| q | 3.629 | 0.376 | 2.939 | 4.294 | 0.129 | 0.094 | 8.0 | 41.0 | 1.41 |
| v | 9.154 | 5.062 | 1.340 | 16.853 | 2.264 | 1.705 | 5.0 | 11.0 | 2.09 |
az.plot_posterior(trace2, var_names=["p", "q", "v"], ref_val=[p_true, q_true, v_true]);
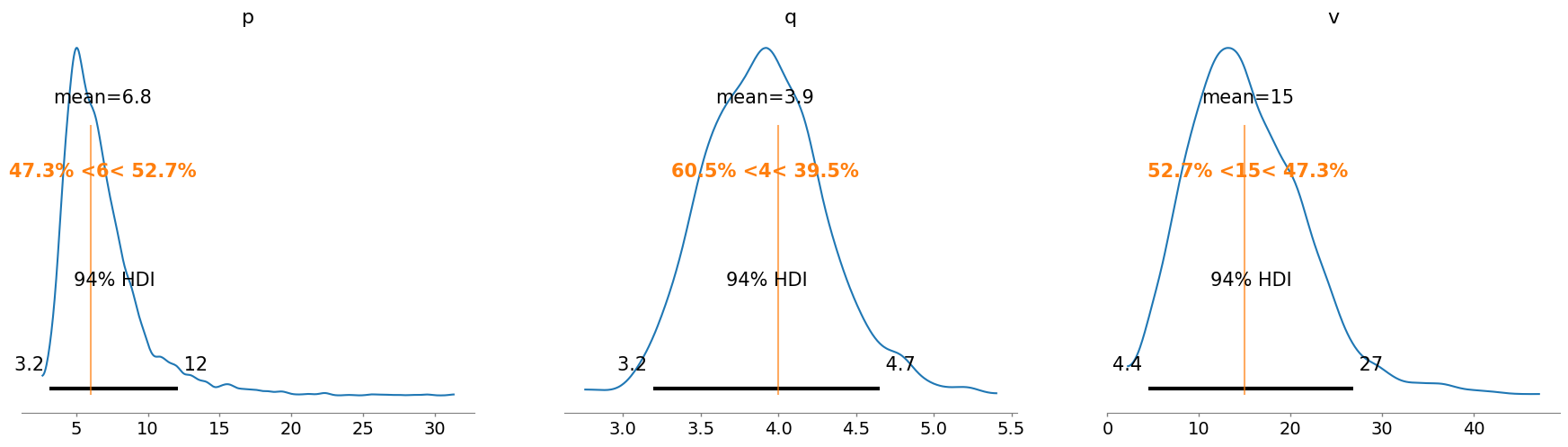
Modelo Gamma-Gamma condicionado en la transacción promedio por usuario con \(\nu\) marginalizado#
with pm.Model() as m3:
p = pm.HalfFlat("p")
q = pm.HalfFlat("q")
v = pm.HalfFlat("v")
# Likelihood of z_mean, marginalizing over nu
likelihood = pm.Potential(
"likelihood",
(
pt.gammaln(p * x + q)
- pt.gammaln(p * x)
- pt.gammaln(q)
+ q * pt.log(v)
+ (p * x - 1) * pt.log(z_mean)
+ (p * x) * pt.log(x)
- (p * x + q) * pt.log(x * z_mean + v)
),
)
# Closed form solution posterior individual nu
nu = pm.Deterministic("nu", pm.Gamma.dist(p * x + q, v + x * z_mean))
pm.Deterministic("mean_spend", p / nu)
trace3 = pm.sample(random_seed=rng)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [p, q, v]
100.00% [8000/8000 00:32<00:00 Sampling 4 chains, 0 divergences]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 33 seconds.
az.summary(trace3, var_names=["p", "q", "v"])
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| p | 6.845 | 2.937 | 3.153 | 12.110 | 0.110 | 0.080 | 865.0 | 812.0 | 1.0 |
| q | 3.915 | 0.390 | 3.194 | 4.654 | 0.012 | 0.009 | 974.0 | 1118.0 | 1.0 |
| v | 15.375 | 6.510 | 4.445 | 26.879 | 0.221 | 0.156 | 816.0 | 738.0 | 1.0 |
az.plot_posterior(trace3, var_names=["p", "q", "v"], ref_val=[p_true, q_true, v_true]);