Modelo gamma-gamma#
En este cuaderno mostramos cómo ajustar un modelo Gamma-Gamma en PyMC-Marketing. Comparamos los resultados con el paquete lifetimes (que ya no se mantiene y la última actualización significativa fue en julio de 2020). El modelo se presenta en el artículo: Fader, P. S., & Hardie, B. G. (2013). El modelo Gamma-Gamma del valor monetario. Febrero, 2, 1-9.
Preparar el cuaderno#
import arviz as az
import matplotlib.pyplot as plt
import pandas as pd
from lifetimes import GammaGammaFitter
from pymc_marketing import clv
# Plotting configuration
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [10, 6]
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "retina"
Cargar Datos#
Comenzamos cargando el conjunto de datos CDNOW.
data_path = "https://raw.githubusercontent.com/pymc-labs/pymc-marketing/main/data/clv_quickstart.csv"
summary_with_money_value = pd.read_csv(data_path)
summary_with_money_value["customer_id"] = summary_with_money_value.index
summary_with_money_value.head()
| frequency | recency | T | monetary_value | customer_id | |
|---|---|---|---|---|---|
| 0 | 2 | 30.43 | 38.86 | 22.35 | 0 |
| 1 | 1 | 1.71 | 38.86 | 11.77 | 1 |
| 2 | 0 | 0.00 | 38.86 | 0.00 | 2 |
| 3 | 0 | 0.00 | 38.86 | 0.00 | 3 |
| 4 | 0 | 0.00 | 38.86 | 0.00 | 4 |
Para el modelo Gamma-Gamma, necesitamos filtrar a los clientes que han realizado solo una compra.
returning_customers_summary = summary_with_money_value.query("frequency > 0")
returning_customers_summary.head()
| frequency | recency | T | monetary_value | customer_id | |
|---|---|---|---|---|---|
| 0 | 2 | 30.43 | 38.86 | 22.35 | 0 |
| 1 | 1 | 1.71 | 38.86 | 11.77 | 1 |
| 5 | 7 | 29.43 | 38.86 | 73.74 | 5 |
| 6 | 1 | 5.00 | 38.86 | 11.77 | 6 |
| 8 | 2 | 35.71 | 38.86 | 25.55 | 8 |
Especificación del modelo#
Aquí describimos brevemente las suposiciones y la parametrización del modelo Gamma-Gamma del artículo mencionado.
El modelo de gasto por transacción se basa en las siguientes tres suposiciones generales:
El valor monetario de una transacción dada por un cliente varía aleatoriamente en torno a su valor promedio de transacción.
Los valores promedio de transacción varían entre los clientes, pero no varían con el tiempo para ningún individuo en particular.
La distribución de los valores promedio de transacción entre los clientes es independiente del proceso de transacción.
Para un cliente con x transacciones, sea \(z_1, z_2, \ldots, z_x\) el valor de cada transacción. El valor promedio de transacción observado del cliente por
Ahora describamos la parametrización:
Asumimos que \(z_i \sim \text{Gamma}(p, ν)\), con \(E(Z_i| p, ν) = \xi = p/ν\).
– Dadas las propiedades de convolución de la gamma, se deduce que el gasto total en x transacciones se distribuye como \(\text{Gamma}(px, ν)\).
– Dada la propiedad de escalado de la distribución gamma, se deduce que \(\bar{z} \sim \text{Gamma}(px, νx)\).
Asumimos \(ν \sim \text{Gamma}(q, \gamma)\).
Estamos interesados en estimar los parámetros \(p\), \(q\) y \(ν\).
Nota
El modelo Gamma-Gamma asume que no existe relación entre el valor monetario y la frecuencia de compra. Podemos verificar esta suposición calculando la correlación entre el gasto promedio y la frecuencia de compras.
returning_customers_summary[["monetary_value", "frequency"]].corr()
| monetary_value | frequency | |
|---|---|---|
| monetary_value | 1.000000 | 0.113884 |
| frequency | 0.113884 | 1.000000 |
El valor de esta correlación es cercano a \(0.11\), lo cual en la práctica se considera lo suficientemente bajo como para proceder con el modelo.
Implementación de Lifetimes#
Primero, ajustamos el modelo utilizando el paquete lifetimes.
ggf = GammaGammaFitter()
ggf.fit(
returning_customers_summary["frequency"],
returning_customers_summary["monetary_value"],
)
<lifetimes.GammaGammaFitter: fitted with 946 subjects, p: 6.25, q: 3.74, v: 15.45>
ggf.summary
| coef | se(coef) | lower 95% bound | upper 95% bound | |
|---|---|---|---|---|
| p | 6.248802 | 1.189687 | 3.917016 | 8.580589 |
| q | 3.744588 | 0.290166 | 3.175864 | 4.313313 |
| v | 15.447748 | 4.159994 | 7.294160 | 23.601336 |
Una vez que el modelo está ajustado, podemos utilizar el siguiente método para calcular la expectativa condicional del beneficio promedio por transacción para un grupo de uno o más clientes.
avg_profit = ggf.conditional_expected_average_profit(
summary_with_money_value["frequency"], summary_with_money_value["monetary_value"]
)
avg_profit.head(10)
0 24.658616
1 18.911480
2 35.171002
3 35.171002
4 35.171002
5 71.462851
6 18.911480
7 35.171002
8 27.282408
9 35.171002
dtype: float64
avg_profit.mean()
35.25295817604993
Implementación de PyMC-Marketing#
Podemos utilizar la implementación preconstruida de PyMC-Marketing del modelo Gamma-Gamma, que también ofrece métodos de representación gráfica y predicción agradables:
Podemos construir el modelo para que podamos ver la especificación del modelo:
model = clv.GammaGammaModel(data=returning_customers_summary)
model.build_model()
model
Gamma-Gamma Model (Mean Transactions)
p ~ HalfFlat()
q ~ HalfFlat()
v ~ HalfFlat()
likelihood ~ Potential(f(q, p, v))
Nota
No es necesario construir el modelo antes de ajustarlo. Podemos ajustar el modelo directamente.
Usando MAP#
Para comenzar, utilicemos un optimizador numérico (L-BFGS-B) de scipy.optimize para encontrar la estimación de máxima a posteriori (MAP) de los parámetros.
idata_map = model.fit(method="map").posterior.to_dataframe()
idata_map
| p | q | v | ||
|---|---|---|---|---|
| chain | draw | |||
| 0 | 0 | 6.248787 | 3.744591 | 15.447813 |
Estos valores son muy cercanos a los obtenidos por el paquete lifetimes.
MCMC#
También podemos utilizar MCMC para muestrear de la distribución posterior de los parámetros. MCMC es un método más robusto que MAP y proporciona estimaciones de incertidumbre para los parámetros.
sampler_kwargs = {
"draws": 2_000,
"target_accept": 0.9,
"chains": 4,
"random_seed": 42,
}
idata_mcmc = model.fit(**sampler_kwargs)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 2 jobs)
NUTS: [p, q, v]
Sampling 4 chains for 1_000 tune and 2_000 draw iterations (4_000 + 8_000 draws total) took 449 seconds.
idata_mcmc
-
<xarray.Dataset> Size: 208kB Dimensions: (chain: 4, draw: 2000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 16kB 0 1 2 3 4 5 6 ... 1994 1995 1996 1997 1998 1999 Data variables: p (chain, draw) float64 64kB 4.713 4.829 7.353 ... 5.578 6.317 5.654 q (chain, draw) float64 64kB 4.289 4.288 3.402 ... 4.176 3.863 3.836 v (chain, draw) float64 64kB 24.09 23.53 11.76 ... 20.22 16.49 17.34 Attributes: created_at: 2024-07-01T15:48:01.851699 arviz_version: 0.17.1 inference_library: pymc inference_library_version: 5.14.0 sampling_time: 448.93818640708923 tuning_steps: 1000 -
<xarray.Dataset> Size: 992kB Dimensions: (chain: 4, draw: 2000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 16kB 0 1 2 3 4 ... 1996 1997 1998 1999 Data variables: (12/17) n_steps (chain, draw) float64 64kB 47.0 11.0 ... 35.0 23.0 acceptance_rate (chain, draw) float64 64kB 0.9899 0.9385 ... 1.0 reached_max_treedepth (chain, draw) bool 8kB False False ... False False lp (chain, draw) float64 64kB -4.051e+03 ... -4.051e+03 process_time_diff (chain, draw) float64 64kB 0.02783 ... 0.03698 diverging (chain, draw) bool 8kB False False ... False False ... ... tree_depth (chain, draw) int64 64kB 6 4 6 6 5 2 ... 3 5 5 2 6 5 energy (chain, draw) float64 64kB 4.052e+03 ... 4.052e+03 perf_counter_start (chain, draw) float64 64kB 7.433e+04 ... 7.471e+04 index_in_trajectory (chain, draw) int64 64kB -19 5 -50 10 ... -27 1 16 -9 step_size_bar (chain, draw) float64 64kB 0.05982 ... 0.06508 perf_counter_diff (chain, draw) float64 64kB 0.04164 0.00677 ... 0.0375 Attributes: created_at: 2024-07-01T15:48:01.937737 arviz_version: 0.17.1 inference_library: pymc inference_library_version: 5.14.0 sampling_time: 448.93818640708923 tuning_steps: 1000 -
<xarray.Dataset> Size: 45kB Dimensions: (index: 946) Coordinates: * index (index) int64 8kB 0 1 5 6 8 10 ... 2347 2348 2349 2353 2355 Data variables: frequency (index) int64 8kB 2 1 7 1 2 5 10 1 3 2 ... 1 2 1 2 7 1 2 5 4 recency (index) float64 8kB 30.43 1.71 29.43 ... 21.86 24.29 26.57 T (index) float64 8kB 38.86 38.86 38.86 ... 27.0 27.0 27.0 monetary_value (index) float64 8kB 22.35 11.77 73.74 ... 18.56 44.93 33.32 customer_id (index) int64 8kB 0 1 5 6 8 10 ... 2347 2348 2349 2353 2355
Podemos ver algunas estadísticas de la distribución posterior de los parámetros.
model.fit_summary()
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| p | 6.403 | 1.303 | 4.217 | 8.710 | 0.032 | 0.023 | 1686.0 | 1783.0 | 1.0 |
| q | 3.781 | 0.290 | 3.238 | 4.338 | 0.007 | 0.005 | 1753.0 | 2187.0 | 1.0 |
| v | 16.051 | 4.243 | 8.050 | 23.907 | 0.107 | 0.076 | 1563.0 | 1746.0 | 1.0 |
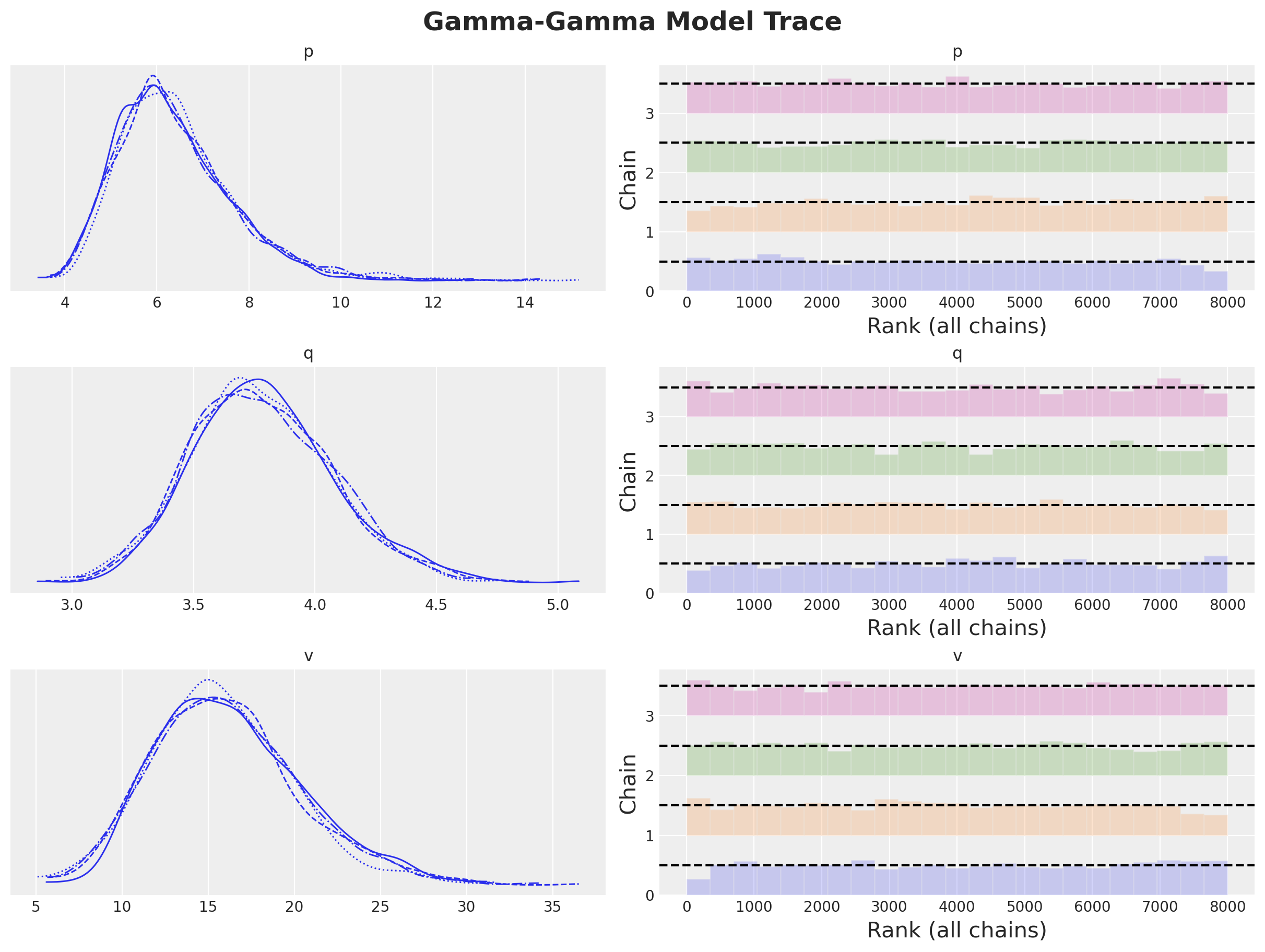
Visualicemos las distribuciones posteriores y el gráfico de rangos:
axes = az.plot_trace(
data=model.idata,
compact=True,
kind="rank_bars",
backend_kwargs={"figsize": (12, 9), "layout": "constrained"},
)
plt.gcf().suptitle("Gamma-Gamma Model Trace", fontsize=18, fontweight="bold");
Podemos comparar los resultados con los obtenidos por el paquete lifetimes y la estimación MAP.
fig, axes = plt.subplots(
nrows=3, ncols=1, figsize=(12, 10), sharex=False, sharey=False, layout="constrained"
)
for i, var_name in enumerate(["p", "q", "v"]):
ax = axes[i]
az.plot_posterior(
idata_mcmc.posterior[var_name].values.flatten(),
color="C0",
point_estimate="mean",
hdi_prob=0.95,
ref_val=ggf.summary["coef"][var_name],
ax=ax,
label="MCMC",
)
ax.axvline(
x=ggf.summary["lower 95% bound"][var_name],
color="C1",
linestyle="--",
label="lifetimes 95% CI",
)
ax.axvline(
x=ggf.summary["upper 95% bound"][var_name],
color="C1",
linestyle="--",
)
ax.axvline(x=idata_map[var_name].item(), color="C2", linestyle="-.", label="MAP")
ax.legend(loc="upper right")
plt.gcf().suptitle("Gamma-Gamma Model Parameters", fontsize=18, fontweight="bold");
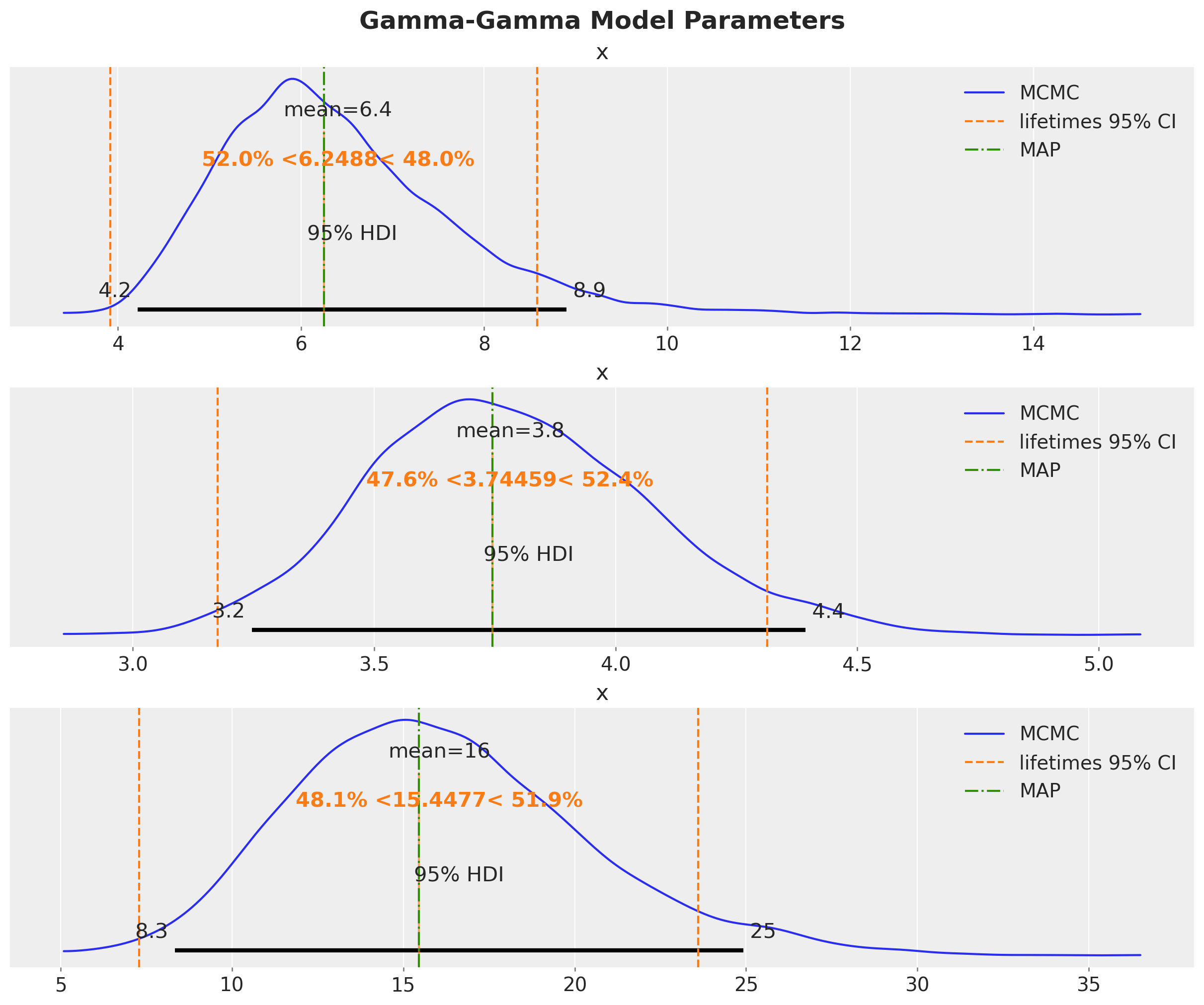
Vemos que las estimaciones de lifetimes y MAP son esencialmente las mismas. Ambas están cerca de la media de la distribución posterior obtenida mediante MCMC.
Gasto Esperado del Cliente#
Una vez que tengamos la distribución posterior de los parámetros, podemos utilizar el método expected_average_profit para calcular la expectativa condicional del beneficio promedio por transacción para un grupo de uno o más clientes.
expected_spend = model.expected_customer_spend(data=summary_with_money_value)
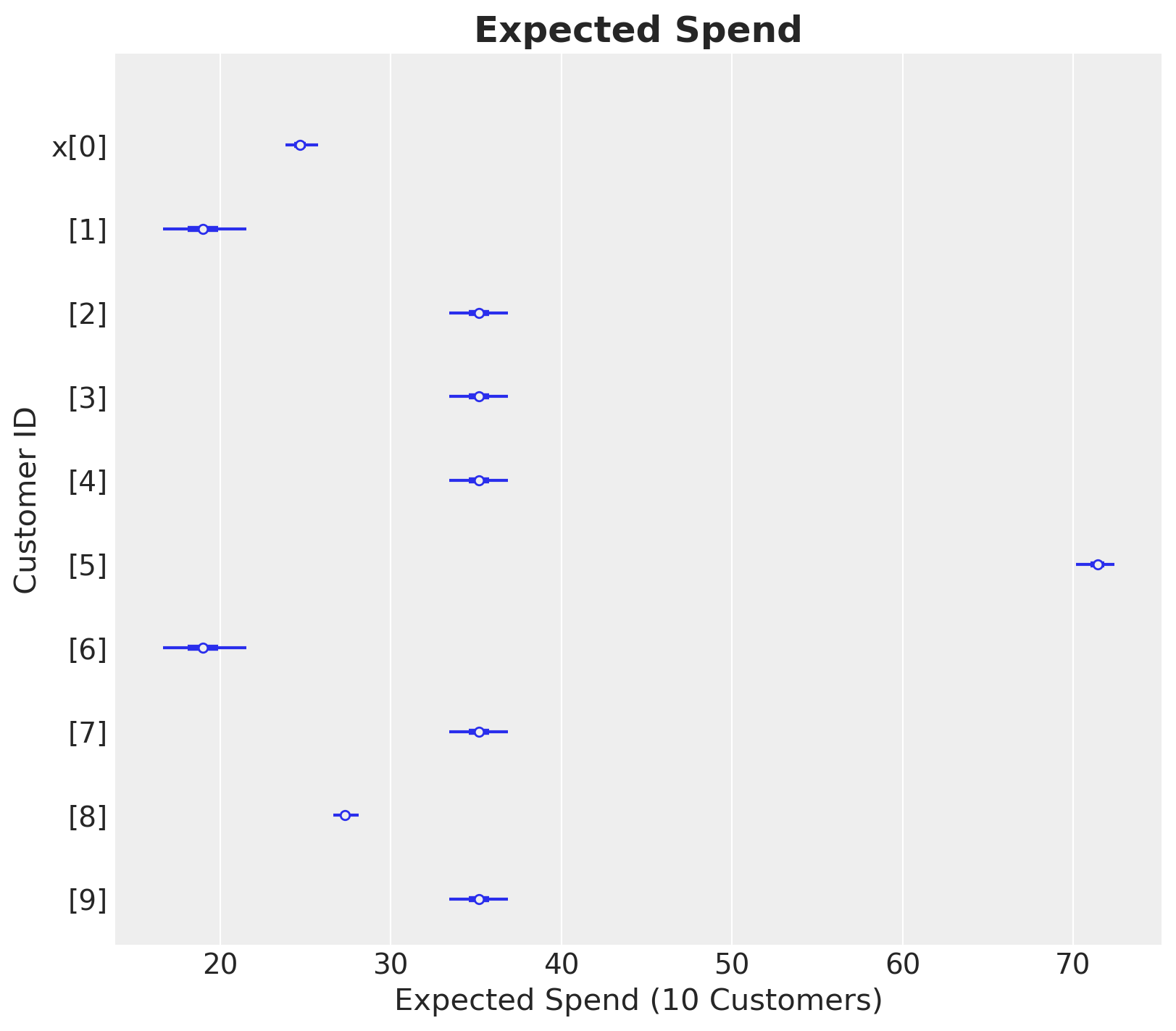
Veamos cómo se ve para un subconjunto de clientes.
az.summary(expected_spend.isel(customer_id=range(10)), kind="stats")
| mean | sd | hdi_3% | hdi_97% | |
|---|---|---|---|---|
| x[0] | 24.706 | 0.512 | 23.839 | 25.762 |
| x[1] | 18.994 | 1.311 | 16.641 | 21.547 |
| x[2] | 35.195 | 0.924 | 33.447 | 36.887 |
| x[3] | 35.195 | 0.924 | 33.447 | 36.887 |
| x[4] | 35.195 | 0.924 | 33.447 | 36.887 |
| x[5] | 71.387 | 0.599 | 70.165 | 72.409 |
| x[6] | 18.994 | 1.311 | 16.641 | 21.547 |
| x[7] | 35.195 | 0.924 | 33.447 | 36.887 |
| x[8] | 27.318 | 0.394 | 26.627 | 28.107 |
| x[9] | 35.195 | 0.924 | 33.447 | 36.887 |
ax, *_ = az.plot_forest(
data=expected_spend.isel(customer_id=(range(10))), combined=True, figsize=(8, 7)
)
ax.set(xlabel="Expected Spend (10 Customers)", ylabel="Customer ID")
ax.set_title("Expected Spend", fontsize=18, fontweight="bold");
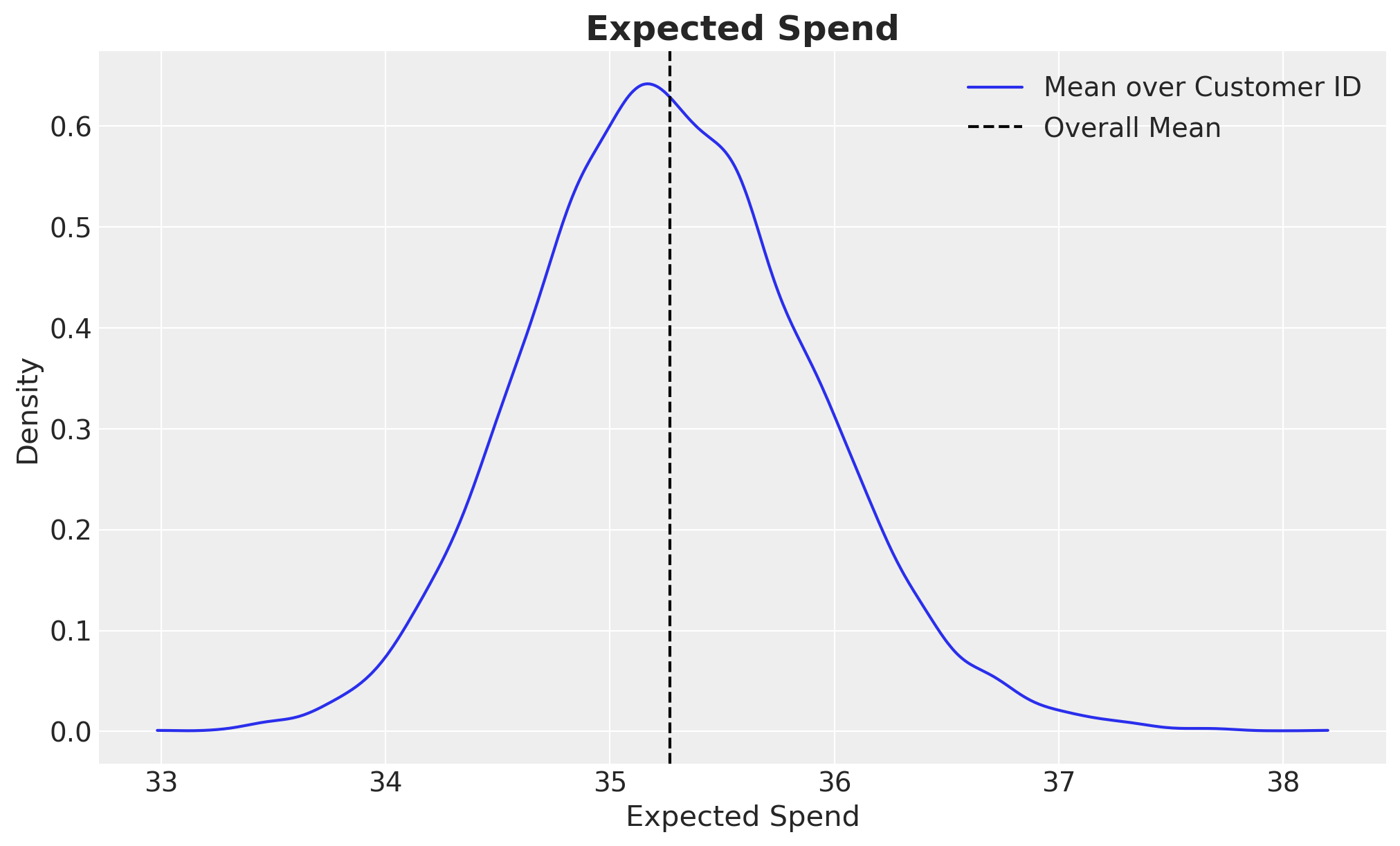
Finalmente, veamos algunas estadísticas y la distribución para todo el conjunto de datos.
az.summary(expected_spend.mean("customer_id"), kind="stats")
| mean | sd | hdi_3% | hdi_97% | |
|---|---|---|---|---|
| x | 35.268 | 0.629 | 34.107 | 36.442 |
fig, ax = plt.subplots()
az.plot_dist(expected_spend.mean("customer_id"), label="Mean over Customer ID", ax=ax)
ax.axvline(x=expected_spend.mean(), color="black", ls="--", label="Overall Mean")
ax.legend(loc="upper right")
ax.set(xlabel="Expected Spend", ylabel="Density")
ax.set_title("Expected Spend", fontsize=18, fontweight="bold");
%load_ext watermark
%watermark -n -u -v -iv -w -p pymc,pytensor
Last updated: Mon Jul 01 2024
Python implementation: CPython
Python version : 3.10.13
IPython version : 8.22.2
pymc : 5.14.0
pytensor: 2.20.0
arviz : 0.17.1
pymc_marketing: 0.6.0
matplotlib : 3.8.3
pandas : 2.2.1
Watermark: 2.4.3