Estudio de Caso: Confusores No Observados, ROAS y Pruebas de Incremento#
La importancia de la calibración en los modelos de mezcla de medios#
Al trabajar con Modelos de Mezcla de Medios (MMM), la calibración con pruebas de elevación no es solo un paso técnico, sino que es esencial para hacer que estos modelos sean fiables y accionables. Las pruebas de elevación sirven como un chequeo de la realidad, anclando las predicciones del modelo en resultados del mundo real. Este proceso es particularmente importante porque los MMM a menudo dependen de datos que son tanto ruidosos como limitados en alcance, lo que dificulta realizar predicciones precisas.
Por qué los MMM deben ser modelos causales#
El verdadero poder de los MMM radica en su capacidad para guiar decisiones basadas en posibles cambios en la estrategia de marketing. Por ejemplo, un comercializador podría preguntar: «¿Qué impacto tendría la reducción del presupuesto para el canal X en un 50% en las ventas totales?» Para responder a tales preguntas, los MMM deben desarrollarse como modelos causales—modelos que pueden predecir los efectos de intervenciones específicas.
Crear un modelo causal implica construir un grafo acíclico dirigido (DAG) bien definido. Un DAG es una representación visual de las relaciones entre diferentes variables en el modelo, ayudando a garantizar que se incluyan las covariables correctas (o variables de control). No se trata solo de incluir cada dato disponible; se trata de seleccionar variables que realmente contribuyan a entender las relaciones causales en sus actividades de marketing.
El desafío de los confundidores no observados#
Incluso con un DAG bien construido, los confundidores no observados pueden representar un problema significativo. Estas son variables que influyen tanto en el tratamiento (por ejemplo, el gasto en un canal de marketing particular) como en el resultado (por ejemplo, las ventas), pero que no están incluidas en el modelo. Su omisión puede llevar a estimaciones sesgadas, lo que a su vez puede resultar en una mala toma de decisiones. Desafortunadamente, los confundidores no observados son casi inevitables en cualquier escenario del mundo real.
Una innovación reciente: calibración de MMMs con priors bayesianos y pruebas de lift#
En teoría, métodos como las variables instrumentales pueden ayudar a abordar el problema de los confundidores no observados. Una variable instrumental es una variable que está correlacionada con el tratamiento pero no con el resultado, excepto a través del tratamiento. Sin embargo, encontrar buenos instrumentos es notoriamente difícil, lo que hace que esta solución sea menos práctica.
Una solución alternativa y más práctica es calibrar el MMM utilizando pruebas de lift. Las pruebas de lift son experimentos que miden el efecto incremental de una intervención de marketing, como un aumento temporal en el gasto publicitario en un canal específico. Al calibrar el modelo con los resultados de estas pruebas, podemos reducir el sesgo introducido por confusores no observados. Los métodos bayesianos son particularmente adecuados para este enfoque porque nos permiten incorporar conocimiento previo—información que tenemos antes de analizar los datos—en el modelo. Esto puede mejorar significativamente la precisión del modelo, incluso antes de comenzar a procesar los números.
Un artículo reciente, Calibración del Modelo de Mezcla de Medios con Priors Bayesianos de Zhang et al. (2024), propone un enfoque novedoso para calibrar los MMM. En lugar de utilizar los coeficientes beta (o de regresión) tradicionales para cada canal, los autores sugieren parametrizar el modelo en términos de retorno sobre la inversión publicitaria (ROAS).
El concepto es sencillo: expresar los coeficientes beta en términos de ROAS y luego sustituirlos en una ecuación estándar de MMM. Este método simplifica el proceso de calibración y puede mitigar parcialmente los sesgos derivados de confusores no observados y del ruido en los datos.
Aplicación Práctica: Implementación del Método en PyMC#
En la entrada del blog Modelo de Mezcla de Medios y Calibración Experimental: Un Estudio de Simulación, Juan Orduz proporciona una implementación completa de este método utilizando PyMC. Este trabajo demuestra cómo este enfoque de calibración puede generar estimaciones más precisas, incluso al tratar con confusores no observados. Sin embargo, a pesar de sus fortalezas, este método tiene una limitación: no mejora automáticamente cuando se añaden pruebas de lift adicionales. Los autores del artículo sugieren agregar los resultados de múltiples pruebas de lift tomando un promedio ponderado de las estimaciones de ROAS de cada experimento.
Un Nuevo Enfoque: Refinando los MMMs con Funciones de Verosimilitud Personalizadas#
Aunque el método propuesto por Zhang et al. es efectivo, podría ser más eficiente al aprovechar los resultados de las pruebas de elevación. Realizar estos experimentos requiere una planificación y recursos significativos, por lo que es importante maximizar su valor.
Para abordar esto, proponemos un enfoque alternativo. En lugar de reparametrizar directamente el modelo en términos de ROAS, sugerimos agregar funciones de verosimilitud adicionales basadas en las curvas de saturación de los canales de marketing. Las curvas de saturación describen cómo la efectividad de un canal de marketing disminuye a medida que aumenta el gasto. Al calibrar el modelo a través de estas curvas utilizando los resultados de las pruebas de lift, podemos refinar continuamente nuestras estimaciones a medida que se realizan más experimentos. Este enfoque nos permite hacer un mejor uso de los datos de las pruebas de lift, lo que conduce a MMMs más precisos y confiables con el tiempo.
Demostrando el Enfoque: Resultados e Implementación#
En nuestro cuaderno, replicamos los resultados del artículo del blog Modelo de Mezcla de Medios y Calibración Experimental: Un Estudio de Simulación utilizando el marco PyMC-Marketing. Este marco nos permite incorporar pruebas de aumento a través de funciones de verosimilitud personalizadas, proporcionando una calibración más matizada del MMM. Al refinar continuamente nuestras estimaciones a medida que nuevos datos se vuelven disponibles, este enfoque ofrece una solución dinámica y robusta a los desafíos planteados por los factores de confusión no observados en la modelización de la mezcla de marketing.
Para aquellos interesados en profundizar, les animamos a explorar una descripción detallada del método en nuestro cuaderno Calibración de Prueba de Elevación, donde explicamos el proceso paso a paso.
Preparar el cuaderno#
import arviz as az
import graphviz as gr
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from pymc_extras.prior import Prior
from pymc_marketing.hsgp_kwargs import HSGPKwargs
from pymc_marketing.mmm import GeometricAdstock, LogisticSaturation
from pymc_marketing.mmm.multidimensional import MMM
from pymc_marketing.paths import data_dir
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "retina"
/Users/juanitorduz/Documents/pymc-marketing/pymc_marketing/mmm/multidimensional.py:216: FutureWarning: This functionality is experimental and subject to change. If you encounter any issues or have suggestions, please raise them at: https://github.com/pymc-labs/pymc-marketing/issues/new
warnings.warn(warning_msg, FutureWarning, stacklevel=1)
/Users/juanitorduz/Documents/pymc-marketing/pymc_marketing/mmm/time_slice_cross_validation.py:32: UserWarning: The pymc_marketing.mmm.builders module is experimental and its API may change without warning.
from pymc_marketing.mmm.builders.yaml import build_mmm_from_yaml
seed: int = sum(map(ord, "mmm_roas_notebook"))
rng: np.random.Generator = np.random.default_rng(seed=seed)
Leer Datos#
Leemos los datos, que están disponibles en el data de nuestro repositorio.
data_path = data_dir / "mmm_roas_data.csv"
raw_df = pd.read_csv(data_path, parse_dates=["date"])
raw_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 131 entries, 0 to 130
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 131 non-null datetime64[ns]
1 dayofyear 131 non-null int64
2 quarter 131 non-null object
3 trend 131 non-null float64
4 cs 131 non-null float64
5 cc 131 non-null float64
6 seasonality 131 non-null float64
7 z 131 non-null float64
8 x1 131 non-null float64
9 x2 131 non-null float64
10 epsilon 131 non-null float64
11 x1_adstock 131 non-null float64
12 x2_adstock 131 non-null float64
13 x1_adstock_saturated 131 non-null float64
14 x2_adstock_saturated 131 non-null float64
15 x1_effect 131 non-null float64
16 x2_effect 131 non-null float64
17 y 131 non-null float64
18 y01 131 non-null float64
19 y02 131 non-null float64
dtypes: datetime64[ns](1), float64(17), int64(1), object(1)
memory usage: 20.6+ KB
Hay muchas columnas en el conjunto de datos. A continuación, explicaremos lo siguiente. Por ahora, lo importante es que, para fines de modelado, solo utilizaremos las columnas date, x1, x2 (canales) y y (objetivo).
model_df = raw_df.copy().filter(["date", "x1", "x2", "y"])
Proceso de Generación de Datos#
En el artículo del blog original, los autores generan los datos utilizando el siguiente DAG.

Estamos interesados en el efecto de los canales x1 y x2 en la variable y. Tenemos covariables adicionales como la estacionalidad anual y un componente de tendencia no lineal. Además, hay un confusor no observado z que afecta tanto a los canales como a la variable objetivo. Esta variable introduce un sesgo en las estimaciones si no la tenemos en cuenta. Sin embargo, para este problema vamos a suponer que no tenemos acceso a la variable z (por lo tanto, no observada).
En el raw_df tenemos todas las columnas necesarias en el proceso de generación de datos para obtener la variable objetivo y. Por ejemplo, la columna x1_adstock_saturated es el resultado de aplicar la función de adstock y luego la saturación al canal x1.
La variable objetivo y se genera como
y = amplitude * (trend + seasonality + z + x1_effect + x2_effect + epsilon)
donde epsilon es un ruido gaussiano y amplitude se establece en \(100\).
Las variables y01 y y02 son la variable objetivo y sin el efecto de los canales x1 y x2, respectivamente. Por lo tanto
y01 = {amplitude} * (trend + seasonality + z + x2_effect + epsilon)
y02 = {amplitude} * (trend + seasonality + z + x1_effect + epsilon)
Para obtener detalles sobre el proceso de generación de datos, consulte la entrada del blog.
A partir de las variables y01 y y02, podemos calcular el ROAS verdadero para los canales x1 y x2 durante todo el período (por simplicidad, ignoramos el efecto de arrastre).
true_roas_x1 = (raw_df["y"] - raw_df["y01"]).sum() / raw_df["x1"].sum()
true_roas_x2 = (raw_df["y"] - raw_df["y02"]).sum() / raw_df["x2"].sum()
print(f"True ROAS for x1: {true_roas_x1:.2f}")
print(f"True ROAS for x2: {true_roas_x2:.2f}")
True ROAS for x1: 93.39
True ROAS for x2: 171.41
Nos gustaría recuperar el verdadero ROAS para los canales x1 y x2 utilizando un modelo de mezcla de medios.
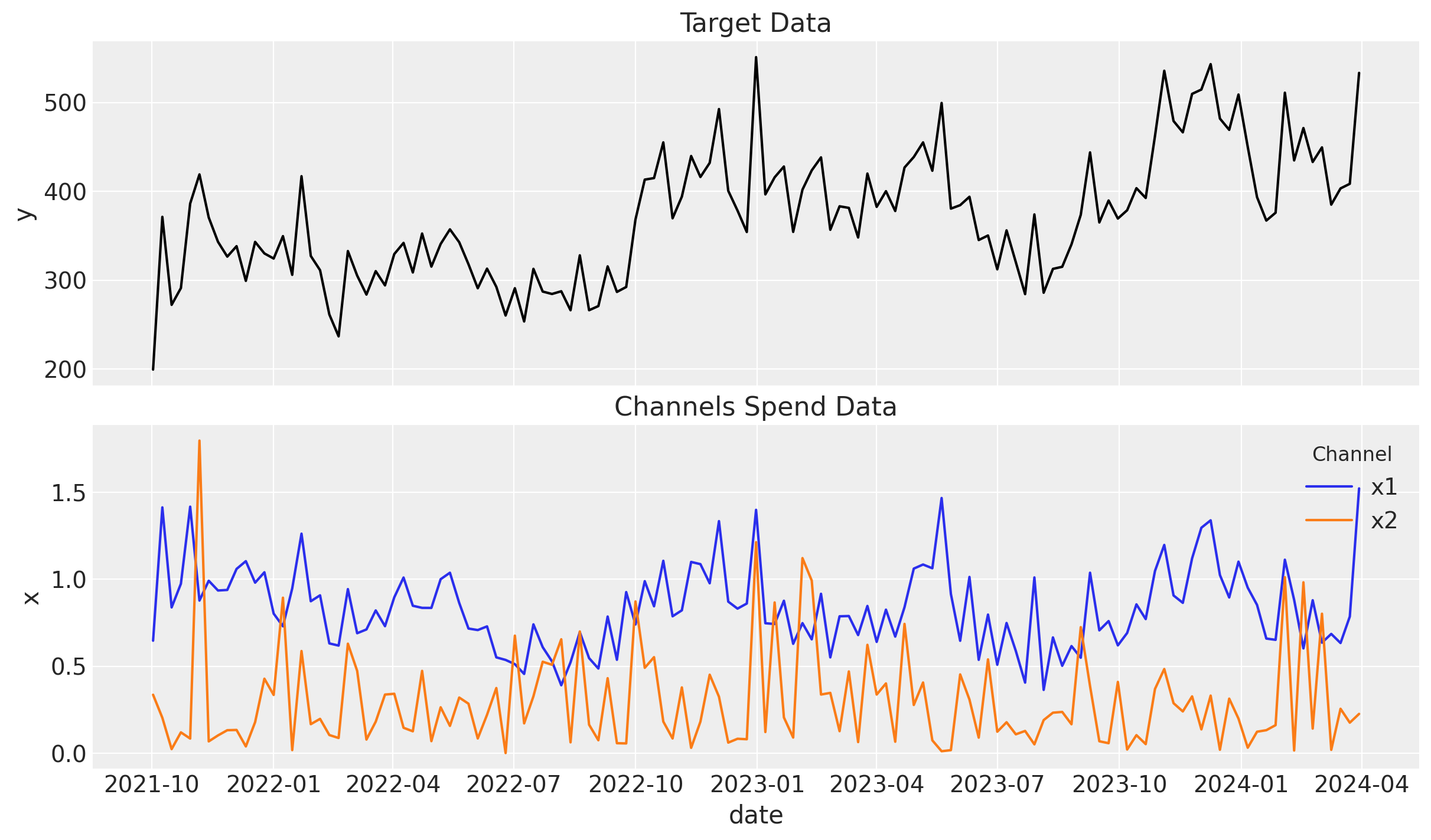
Before jumping into the model, let’s plot the target data and the channels data to understand it better.
fig, ax = plt.subplots(
nrows=2,
ncols=1,
sharex=True,
sharey=False,
layout="constrained",
)
sns.lineplot(
x="date",
y="y",
data=model_df,
color="black",
ax=ax[0],
)
ax[0].set_title("Target Data")
model_df.melt(
id_vars=["date"], value_vars=["x1", "x2"], var_name="channel", value_name="x"
).pipe(
(sns.lineplot, "data"),
x="date",
y="x",
hue="channel",
ax=ax[1],
)
ax[1].legend(title="Channel", title_fontsize=12)
ax[1].set_title("Channels Spend Data");
Modelo Base#
Para comenzar, ajustamos un modelo de mezcla de medios, sin incluir el confusor no observado z, utilizando un adstock saturado y saturación logística mediante la API de PyMC-Marketing. Para más detalles sobre el modelo, consulte el cuaderno {ref}mmm_example`. Como discutimos en ese cuaderno, sin ninguna información de prueba de elevación, un buen punto de partida es pasar la participación de costos al prior de los coeficientes del canal beta.
cost_share = model_df[["x1", "x2"]].sum() / model_df[["x1", "x2"]].sum().sum()
Podemos especificar la configuración del modelo de la siguiente manera (consulte el cuaderno Configuración del modelo para más detalles):
model_config = {
"intercept": Prior("Normal", mu=200, sigma=20),
"likelihood": Prior("Normal", sigma=Prior("HalfNormal", sigma=2)),
"gamma_fourier": Prior("Normal", mu=0, sigma=2, dims="fourier_mode"),
"intercept_tvp_config": HSGPKwargs(
m=100, L=None, eta_lam=1.0, ls_mu=5.0, ls_sigma=10.0, cov_func=None
),
"adstock_alpha": Prior("Beta", alpha=2, beta=3, dims="channel"),
"saturation_lam": Prior("Gamma", alpha=2, beta=2, dims="channel"),
"saturation_beta": Prior("HalfNormal", sigma=cost_share.to_numpy(), dims="channel"),
}
Observe que vamos a utilizar un proceso gaussiano para modelar el componente de tendencia no lineal (ver MMM con parámetros que varían en el tiempo (TVP)).
¡Ajustemos el modelo!
%%time
mmm = MMM(
adstock=GeometricAdstock(l_max=4),
saturation=LogisticSaturation(),
date_column="date",
channel_columns=["x1", "x2"],
target_column="y",
time_varying_intercept=True,
time_varying_media=False,
yearly_seasonality=5,
model_config=model_config,
)
y = model_df["y"]
X = model_df.drop(columns=["y"])
fit_kwargs = {
"tune": 1_500,
"chains": 4,
"draws": 1_000,
"nuts_sampler": "nutpie",
"target_accept": 0.95,
"random_seed": rng,
}
mmm.build_model(X, y)
mmm.add_original_scale_contribution_variable(
var=[
"channel_contribution",
"fourier_contribution",
"intercept_contribution",
]
)
_ = mmm.fit(X, y, **fit_kwargs)
_ = mmm.sample_posterior_predictive(
X, extend_idata=True, combined=True, random_seed=rng
)
Sampler Progress
Total Chains: 4
Active Chains: 0
Finished Chains: 4
Sampling for 14 seconds
Estimated Time to Completion: now
| Progress | Draws | Divergences | Step Size | Gradients/Draw |
|---|---|---|---|---|
| 2500 | 0 | 0.09 | 63 | |
| 2500 | 0 | 0.08 | 63 | |
| 2500 | 0 | 0.07 | 63 | |
| 2500 | 0 | 0.08 | 63 |
Sampling: [y]
CPU times: user 1min 2s, sys: 1.01 s, total: 1min 3s
Wall time: 24 s
Verifiquemos que no tengamos transiciones divergentes.
# Number of diverging samples
mmm.idata["sample_stats"]["diverging"].sum().item()

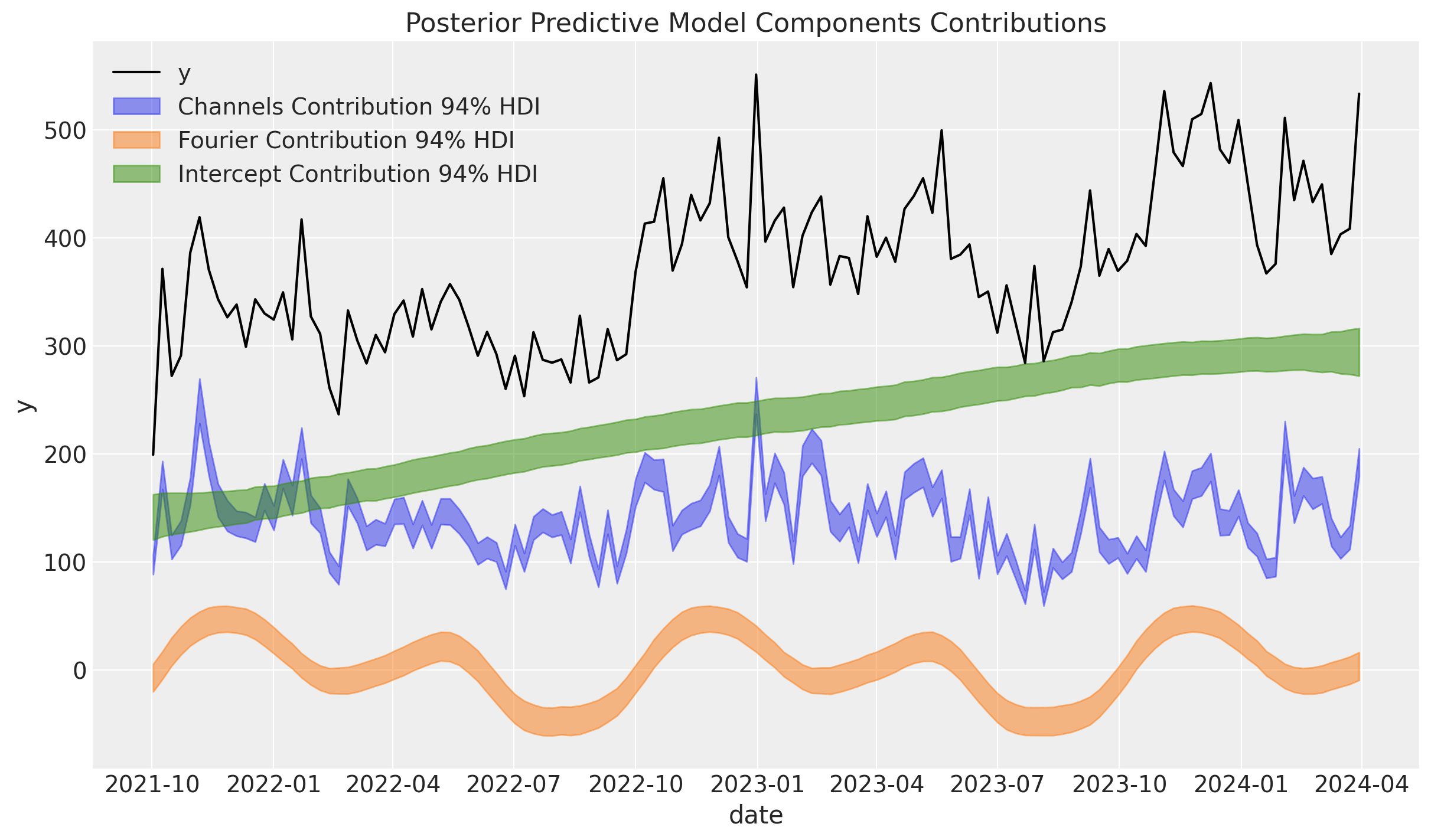
A continuación, examinamos las contribuciones de los componentes del modelo:
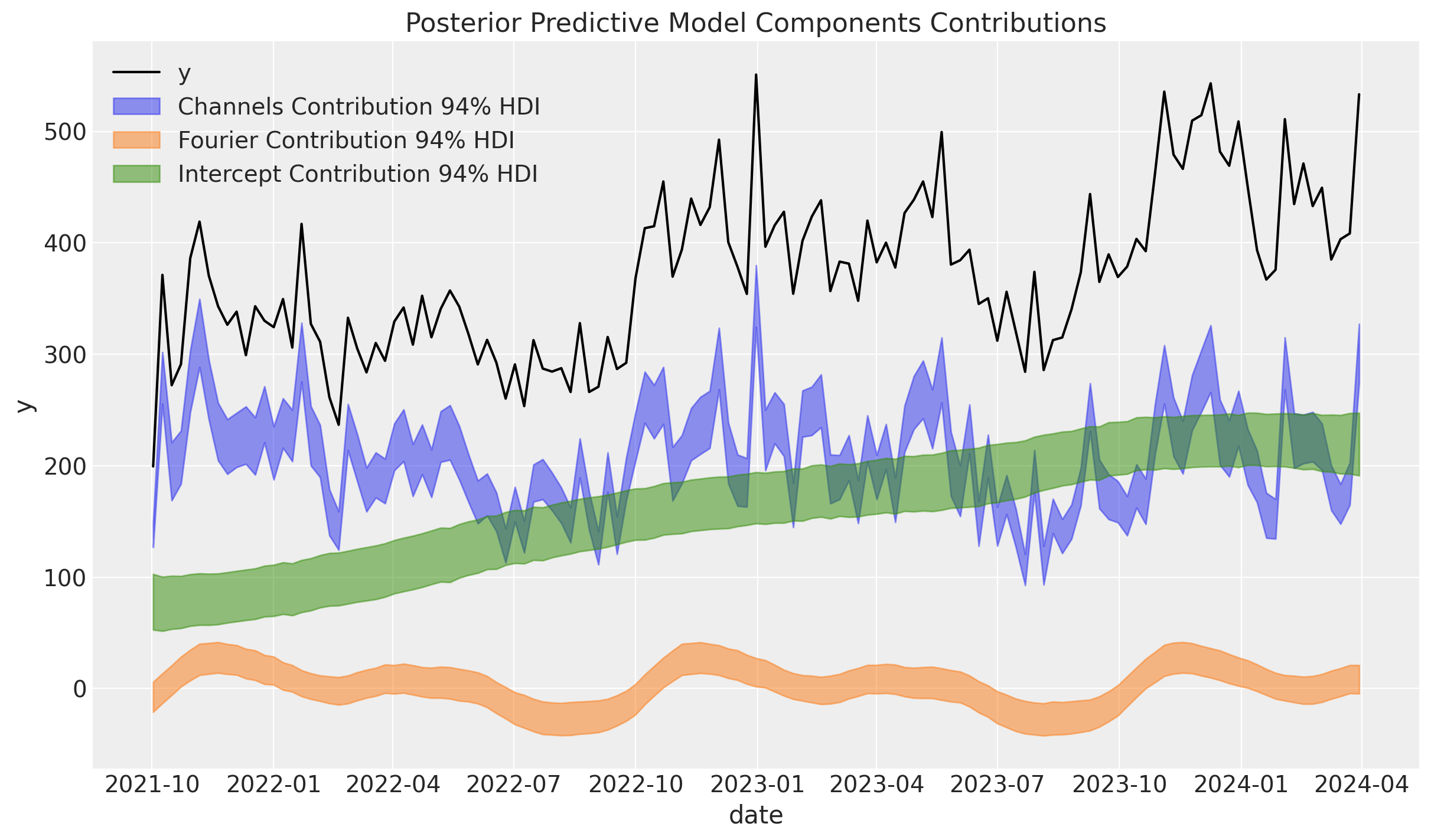
Los resultados son muy similares a los resultados de la publicación original del blog. En particular, observe que pudimos capturar la tendencia no lineal.
A continuación, analizamos las contribuciones del canal en relación con los efectos reales (que conocemos a partir del proceso de generación de datos).
channels_contribution_original_scale = mmm.idata["posterior"][
"channel_contribution_original_scale"
]
channels_contribution_original_scale_hdi = az.hdi(
ary=channels_contribution_original_scale
)
fig, ax = plt.subplots(
nrows=2, figsize=(15, 8), ncols=1, sharex=True, sharey=False, layout="constrained"
)
amplitude = 100
for i, x in enumerate(["x1", "x2"]):
# HDI estimated contribution in the original scale
ax[i].fill_between(
x=model_df["date"],
y1=channels_contribution_original_scale_hdi[
"channel_contribution_original_scale"
].sel(channel=x, hdi="lower"),
y2=channels_contribution_original_scale_hdi[
"channel_contribution_original_scale"
].sel(channel=x, hdi="higher"),
color=f"C{i}",
label=rf"{x} $94\%$ HDI contribution",
alpha=0.4,
)
sns.lineplot(
x="date",
y=f"{x}_effect",
data=raw_df.assign(**{f"{x}_effect": lambda df: amplitude * df[f"{x}_effect"]}), # noqa B023
color=f"C{i}",
label=f"{x} effect",
ax=ax[i],
)
ax[i].legend(loc="center left", bbox_to_anchor=(1, 0.5))
ax[i].set(title=f"Channel {x}")
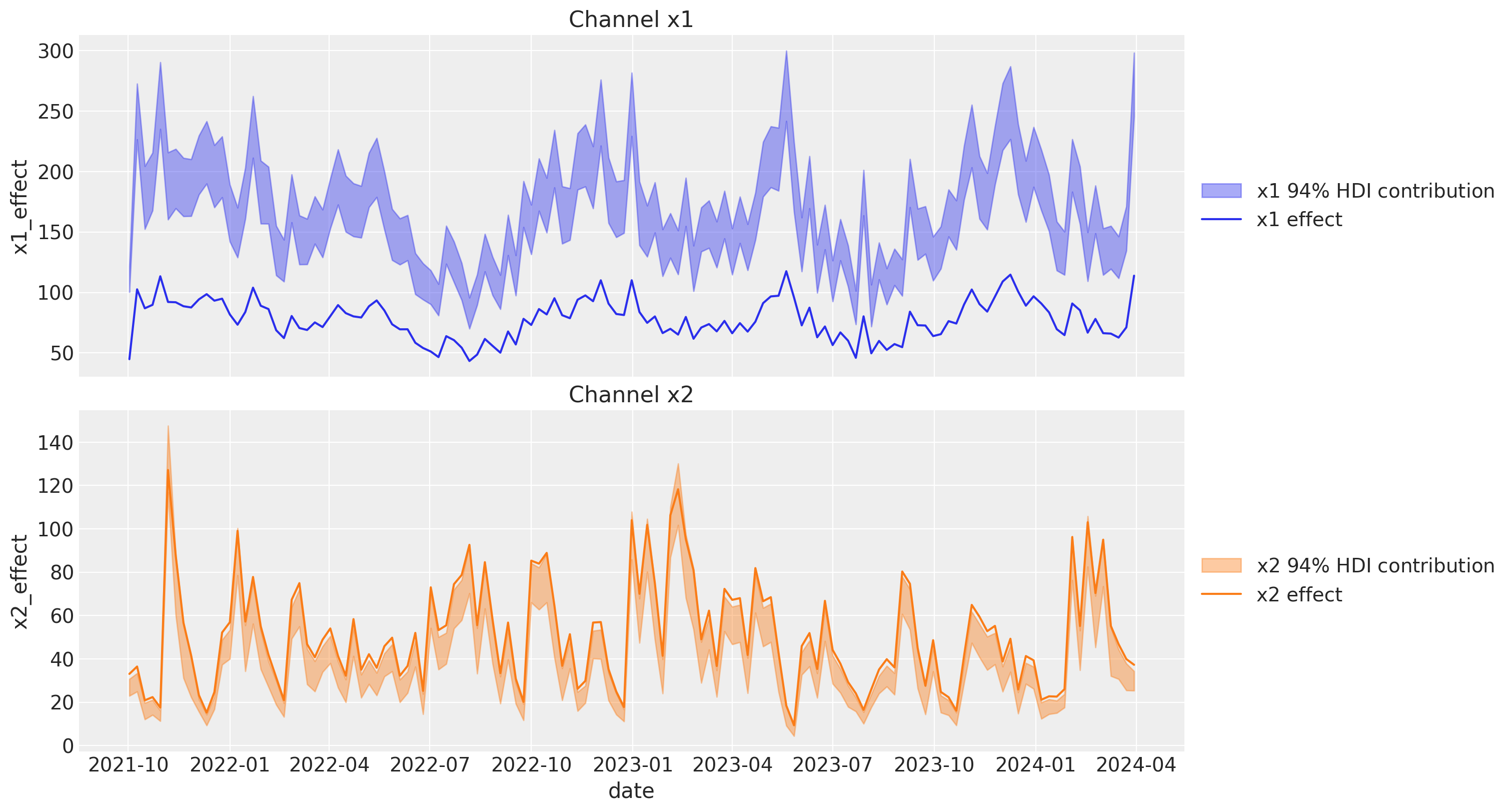
Vemos que la contribución de x1 es muy diferente del efecto verdadero. Esto se debe a la ausencia del confusor no observado z. Para x2, la contribución es muy similar al efecto verdadero.
Finalmente, podemos calcular el ROAS para los canales x1 y x2 (nuevamente, ignorando el pequeño efecto de arrastre).
roas_posterior = (
channels_contribution_original_scale.sum(dim="date")
/ model_df[["x1", "x2"]].sum().to_numpy()[np.newaxis, np.newaxis, :]
)
fig, ax = plt.subplots(
nrows=2, ncols=1, figsize=(12, 7), sharex=True, sharey=False, layout="constrained"
)
az.plot_posterior(roas_posterior, ref_val=[true_roas_x1, true_roas_x2], ax=ax)
ax[0].set_title("x1")
ax[1].set_title("x2")
fig.suptitle("ROAS Posterior Distribution", fontsize=16, y=1.05);
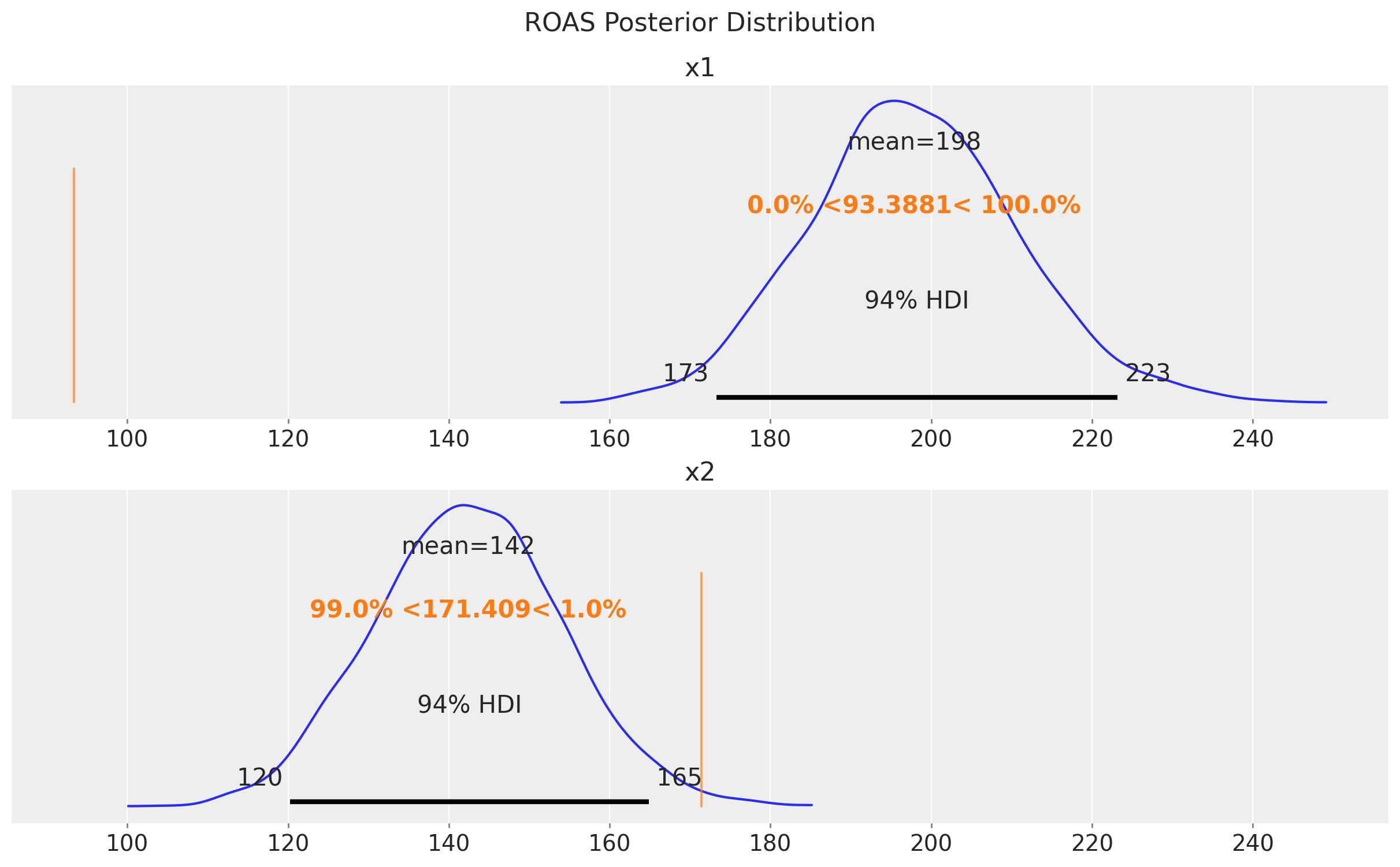
Vemos que el ROAS para x1 es muy diferente del valor verdadero. Esto refleja el sesgo inducido por el confusor no observado z. Los modelos sugieren que x1 es más efectivo que x2, ¡pero sabemos por el proceso de generación de datos que x2 es más efectivo!
Modelo de Prueba de Elevación#
Ahora ajustamos un modelo con algunas pruebas de elevación. Usaremos la misma configuración del modelo que antes, pero liberamos los priors de los coeficientes del canal beta, ya que estos están incluidos en la parametrización de la función de saturación. En general, esperamos que los priors de las pruebas de elevación o las verosimilitudes personalizadas asociadas sean mejores que el prior de la participación en los costos.
model_config = {
"intercept": Prior("Normal", mu=200, sigma=20),
"likelihood": Prior("Normal", sigma=Prior("HalfNormal", sigma=2)),
"gamma_fourier": Prior("Normal", mu=0, sigma=2, dims="fourier_mode"),
"intercept_tvp_config": HSGPKwargs(
m=50, L=None, eta_lam=1.0, ls_mu=5.0, ls_sigma=10.0, cov_func=None
),
"adstock_alpha": Prior("Beta", alpha=2, beta=3, dims="channel"),
"saturation_lam": Prior("Gamma", alpha=2, beta=2, dims="channel"),
"saturation_beta": Prior("HalfNormal", sigma=1.5, dims="channel"),
}
mmm_lift = MMM(
adstock=GeometricAdstock(l_max=4),
saturation=LogisticSaturation(),
date_column="date",
channel_columns=["x1", "x2"],
target_column="y",
time_varying_intercept=True,
time_varying_media=False,
yearly_seasonality=5,
model_config=model_config,
)
# we need to build the model before adding the lift test measurements
mmm_lift.build_model(X, y)
Pruebas de Elevación
En un estudio de elevación, se cambia temporalmente el presupuesto de un canal durante un período fijo de tiempo, y luego se utiliza algún método (por ejemplo, CausalPy) para inferir sobre el cambio en las ventas directamente causado por el ajuste.
Una prueba de elevación se caracteriza por:
channel: el canal que fue probadox: gasto del canal de pre-pruebadelta_x: cambio realizado en xdelta_y: cambio inferido en las ventas debido a delta_xsigma: desviación estándar de delta_y
Un experimento caracterizado de esta manera puede ser visto como dos puntos en la curva de saturación para el canal.
A continuación, supongamos que hemos realizado dos pruebas de elevación para los canales x1 y x2. La tabla de resultados se ve así:
df_lift_test = pd.DataFrame(
data={
"channel": ["x1", "x2", "x1", "x2"],
"x": [0.25, 0.1, 0.8, 0.25],
"delta_x": [0.25, 0.1, 0.8, 0.25],
"delta_y": [
true_roas_x1 * 0.25,
true_roas_x2 * 0.1,
true_roas_x1 * 0.8,
true_roas_x2 * 0.25,
],
"sigma": [3, 3, 3, 3],
}
)
df_lift_test
| channel | x | delta_x | delta_y | sigma | |
|---|---|---|---|---|---|
| 0 | x1 | 0.25 | 0.25 | 23.347033 | 3 |
| 1 | x2 | 0.10 | 0.10 | 17.140880 | 3 |
| 2 | x1 | 0.80 | 0.80 | 74.710505 | 3 |
| 3 | x2 | 0.25 | 0.25 | 42.852201 | 3 |
Comparación con la publicación original del blog
Tenga en cuenta que hemos añadido el ROAS verdadero para los canales x1 y x2 implícitos en la tabla df_lift_test. Los añadimos multiplicando el delta_y, ya que esto es lo que habríamos observado si hubiéramos realizado la prueba de lift (o valores similares).
En la simulación Media Mix Model and Experimental Calibration: A Simulation Study, el autor incluyó estos valores «verdaderos» en la prior para el ROAS.
Ahora, ajustamos el modelo con las mediciones de la prueba de elevación.
mmm_lift.add_lift_test_measurements(df_lift_test=df_lift_test)
mmm_lift.add_original_scale_contribution_variable(
var=[
"channel_contribution",
"fourier_contribution",
"intercept_contribution",
]
)
_ = mmm_lift.fit(X, y, **fit_kwargs)
_ = mmm_lift.sample_posterior_predictive(
X, extend_idata=True, combined=True, random_seed=rng
)
Sampler Progress
Total Chains: 4
Active Chains: 0
Finished Chains: 4
Sampling for now
Estimated Time to Completion: now
| Progress | Draws | Divergences | Step Size | Gradients/Draw |
|---|---|---|---|---|
| 2500 | 0 | 0.09 | 63 | |
| 2500 | 0 | 0.08 | 63 | |
| 2500 | 0 | 0.08 | 63 | |
| 2500 | 0 | 0.08 | 63 |
Sampling: [lift_measurements, y]
Nuevamente, verificamos que no tenemos transiciones divergentes.
# Number of diverging samples
mmm_lift.idata["sample_stats"]["diverging"].sum().item()
Vamos a trazar las contribuciones de los componentes como lo hicimos antes.
Como antes, hemos recuperado el componente de tendencia no lineal y la estacionalidad anual.
Ahora, calculemos las contribuciones del canal a las verdaderas.
channels_contribution_original_scale = mmm_lift.idata["posterior"][
"channel_contribution_original_scale"
]
channels_contribution_original_scale_hdi = az.hdi(
ary=channels_contribution_original_scale, hdi_prob=0.8
)
fig, ax = plt.subplots(
nrows=2, figsize=(15, 8), ncols=1, sharex=True, sharey=False, layout="constrained"
)
amplitude = 100
for i, x in enumerate(["x1", "x2"]):
# HDI estimated contribution in the original scale
ax[i].fill_between(
x=model_df["date"],
y1=channels_contribution_original_scale_hdi[
"channel_contribution_original_scale"
].sel(channel=x, hdi="lower"),
y2=channels_contribution_original_scale_hdi[
"channel_contribution_original_scale"
].sel(channel=x, hdi="higher"),
color=f"C{i}",
label=rf"{x} $94\%$ HDI contribution",
alpha=0.4,
)
sns.lineplot(
x="date",
y=f"{x}_effect",
data=raw_df.assign(**{f"{x}_effect": lambda df: amplitude * df[f"{x}_effect"]}), # noqa B023
color=f"C{i}",
label=f"{x} effect",
ax=ax[i],
)
ax[i].legend(loc="center left", bbox_to_anchor=(1, 0.5))
ax[i].set(title=f"Channel {x}")
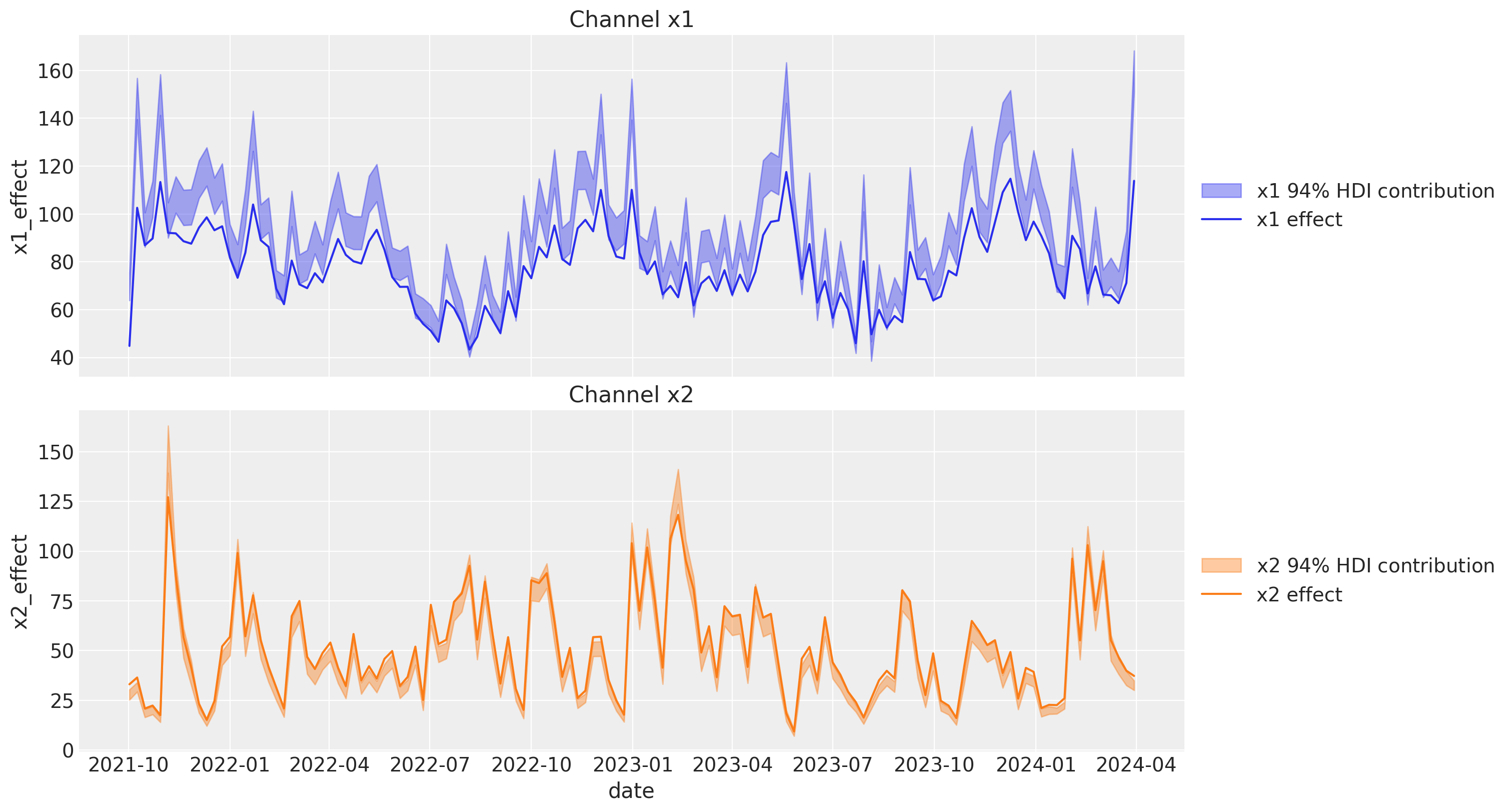
Las contribuciones se ven mucho mejor y están muy cerca de las del artículo original del blog. Por lo tanto, estos dos enfoques son muy similares. Sin embargo, tenga en cuenta que el enfoque de PyMC-Marketing es más flexible, ya que permite enriquecer las estimaciones con más pruebas y diferentes gastos en medios para tener una mejor comprensión del efecto de saturación.
Finalmente, calculemos el ROAS para los canales x1 y x2.
roas_posterior = (
channels_contribution_original_scale.sum(dim="date")
/ model_df[["x1", "x2"]].sum().to_numpy()[np.newaxis, np.newaxis, :]
)
fig, ax = plt.subplots(
nrows=2, ncols=1, figsize=(12, 7), sharex=True, sharey=False, layout="constrained"
)
az.plot_posterior(roas_posterior, ref_val=[true_roas_x1, true_roas_x2], ax=ax)
ax[0].set_title("x1")
ax[1].set_title("x2")
fig.suptitle("ROAS Posterior Distribution", fontsize=16, y=1.05);
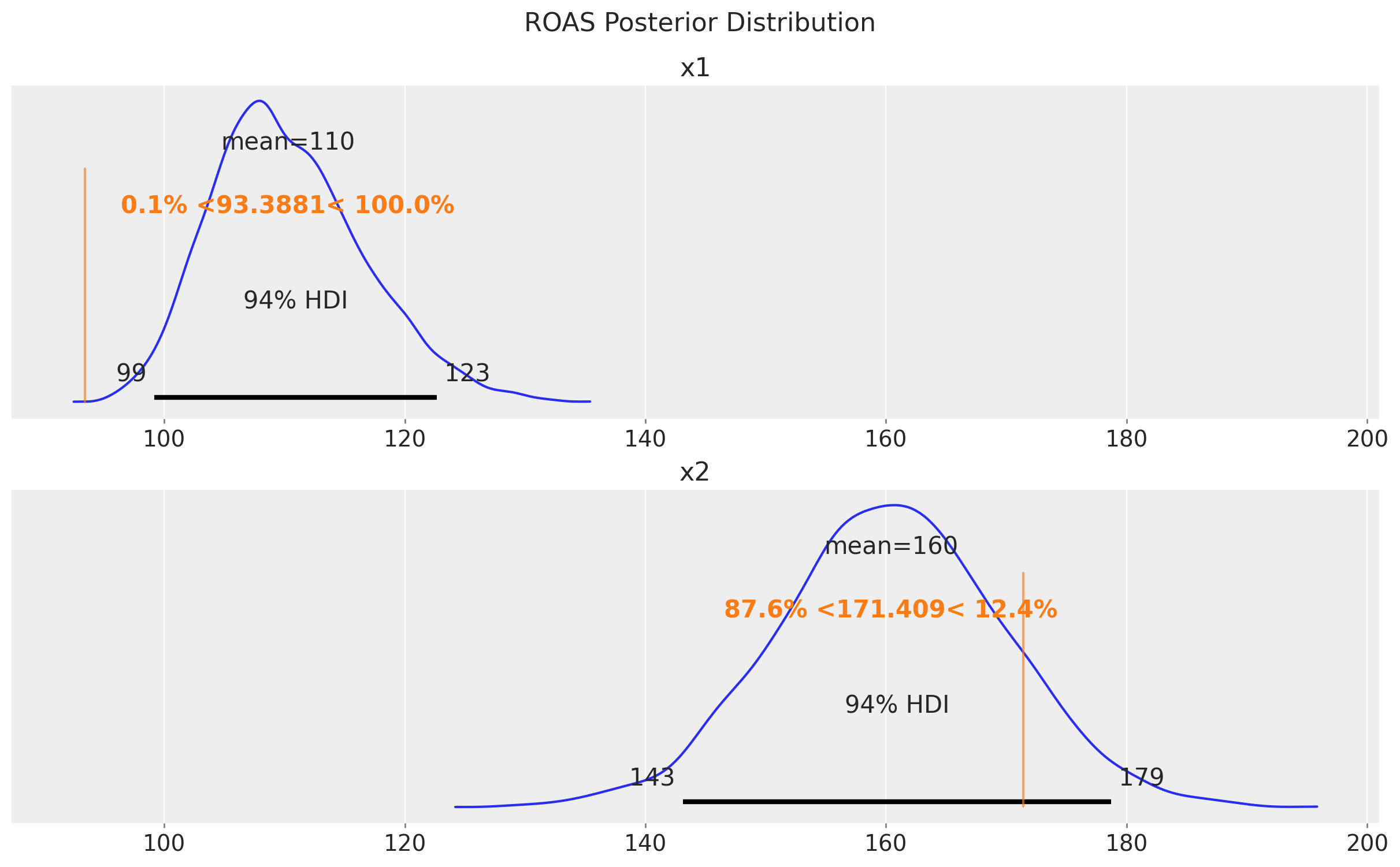
Las estimaciones están muy, muy cerca del verdadero ROAS. Obtenemos del modelo que x2 es más efectivo que x1, lo cual está alineado con los resultados de la prueba de aumento.
Conclusión#
En este cuaderno, hemos visto un ejemplo concreto de cómo los modelos de mezcla de medios pueden proporcionar estimaciones de sesgo cuando tenemos confusores no observados en la especificación del modelo. Idealmente, agregaríamos el confusor, pero en ausencia de eso, necesitamos proporcionar un ancla de realidad al modelo para obtener estimaciones significativas. Hemos demostrado que el enfoque de PyMC-Marketing de agregar mediciones de pruebas de elevación al modelo es muy similar al propuesto en el artículo Calibración del Modelo de Mezcla de Medios con Priors Bayesianos y en la publicación del blog Modelo de Mezcla de Medios y Calibración Experimental: Un Estudio de Simulación. Sin embargo, el enfoque de PyMC-Marketing es más flexible, ya que permite enriquecer las estimaciones con más pruebas de elevación y diferentes gastos en medios para comprender mejor el efecto de saturación. También hemos visto por qué es esencial incluir las mediciones de pruebas de elevación en el modelo para tener en cuenta los confusores no observados y comprender mejor el efecto de saturación.
%load_ext watermark
%watermark -n -u -v -iv -w -p pymc_marketing,pytensor,numpyro
Last updated: Mon, 12 Jan 2026
Python implementation: CPython
Python version : 3.13.11
IPython version : 9.9.0
pymc_marketing: 0.17.1
pytensor : 2.36.3
numpyro : 0.19.0
arviz : 0.23.0
graphviz : 0.21
matplotlib : 3.10.8
numpy : 2.3.5
pandas : 2.3.3
pymc_extras : 0.7.0
pymc_marketing: 0.17.1
seaborn : 0.13.2
Watermark: 2.6.0