Modelo MBG/NBD#
In this notebook we show how to fit a MBG/NBD model in PyMC-Marketing. The model is presented in the paper: Batislam E. P., Denizel M., Filiztekin A. (2007) Empirical validation and comparison of models for customer base analysis
Preparar el cuaderno#
import arviz as az
import matplotlib.pyplot as plt
import pandas as pd
import xarray as xr
from fastprogress.fastprogress import progress_bar
from pymc_marketing import clv
# Plotting configuration
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "retina"
Leer Datos#
We use the CDNOW dataset.
data_path = "https://raw.githubusercontent.com/pymc-labs/pymc-marketing/main/data/clv_quickstart.csv"
df = pd.read_csv(data_path)
df.head()
| frequency | recency | T | monetary_value | |
|---|---|---|---|---|
| 0 | 2 | 30.43 | 38.86 | 22.35 |
| 1 | 1 | 1.71 | 38.86 | 11.77 |
| 2 | 0 | 0.00 | 38.86 | 0.00 |
| 3 | 0 | 0.00 | 38.86 | 0.00 |
| 4 | 0 | 0.00 | 38.86 | 0.00 |
The following definitions are standard in CLV modeling:
frequencyrepresenta el número de compras repetidas que ha realizado el cliente. Esto significa que es uno menos que el total de compras. En realidad, esto es ligeramente incorrecto. Es el conteo de los períodos de tiempo en los que el cliente realizó una compra. Así que, si se utilizan días como unidades, entonces es el conteo de los días en los que el cliente realizó una compra.
Trepresenta la edad del cliente en las unidades de tiempo elegidas (semanalmente, en el conjunto de datos anterior). Esto es igual a la duración entre la primera compra de un cliente y el final del período bajo estudio.
recencyrepresenta la antigüedad del cliente en el momento en que realizó sus compras más recientes. Esto es igual a la duración entre la primera compra de un cliente y su última compra. (Por lo tanto, si solo ha realizado 1 compra, la recency es 0.)
Truco
Renombramos la columna de índice a customer_id, ya que esto es requerido por el modelo.
data = (
df.reset_index()
.rename(columns={"index": "customer_id"})
.drop(columns="monetary_value")
)
Especificación del modelo#
El modelo MBG/NBD es un modelo probabilístico que describe el comportamiento de compra de un cliente en un entorno no contractual. Se basa en las siguientes suposiciones para cada cliente:
Abandono después de la primera compra#
En contraste con el modelo BG/NBD, en el MBG/NBD un cliente puede abandonar en el tiempo cero con una probabilidad p. Esto da lugar a la siguiente función de verosimilitud a nivel individual:
Compara la expresión anterior con la probabilidad regular de BG/NBD:
Ajuste del modelo#
Estimar tales parámetros es muy fácil en PyMC-Marketing. Instanciamos el modelo de manera similar:
model = clv.ModifiedBetaGeoModel()
Y construya el modelo para ver la configuración del modelo:
model.build_model(data=data)
model
MBG/NBD
alpha ~ Weibull(2, 10)
r ~ Weibull(2, 1)
phi_dropout ~ Uniform(0, 1)
kappa_dropout ~ Pareto(1, 1)
a ~ Deterministic(f(kappa_dropout, phi_dropout))
b ~ Deterministic(f(kappa_dropout, phi_dropout))
recency_frequency ~ ModifiedBetaGeoNBD(a, b, r, alpha, <constant>)
Observe los priors adicionales phi_dropout y kappa_dropout. Estos se añadieron a la configuración predeterminada para mejorar el rendimiento, pero se pueden omitir al especificar una model_config personalizada con a y b.
La estructura del modelo especificado también se puede visualizar:
model.graphviz()

Ahora podemos ajustar el modelo. El muestreador predeterminado en PyMC-Marketing es el Muestreador No-U-Turn (NUTS). Utilizamos las \(4\) cadenas predeterminadas y \(1000\) muestras por cadena.
Nota
No es necesario construir el modelo antes de ajustarlo. Podemos ajustar el modelo directamente.
sample_kwargs = {
"draws": 2_000,
"chains": 4,
"target_accept": 0.9,
"random_seed": 42,
}
idata_mcmc = model.fit(**sample_kwargs)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, r, phi_dropout, kappa_dropout]
Sampling 4 chains for 1_000 tune and 2_000 draw iterations (4_000 + 8_000 draws total) took 10 seconds.
idata_mcmc
-
<xarray.Dataset> Size: 400kB Dimensions: (chain: 4, draw: 2000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 16kB 0 1 2 3 4 5 ... 1995 1996 1997 1998 1999 Data variables: alpha (chain, draw) float64 64kB 5.809 7.136 7.447 ... 6.752 6.388 r (chain, draw) float64 64kB 0.4597 0.6567 ... 0.6914 0.6354 phi_dropout (chain, draw) float64 64kB 0.3297 0.4224 ... 0.4218 0.4323 kappa_dropout (chain, draw) float64 64kB 2.99 2.086 1.879 ... 1.585 1.98 a (chain, draw) float64 64kB 0.9859 0.881 ... 0.6685 0.8557 b (chain, draw) float64 64kB 2.005 1.205 1.121 ... 0.9165 1.124 Attributes: created_at: 2025-02-05T16:31:32.193921+00:00 arviz_version: 0.20.0 inference_library: pymc inference_library_version: 5.19.1 sampling_time: 10.055245637893677 tuning_steps: 1000 -
<xarray.Dataset> Size: 992kB Dimensions: (chain: 4, draw: 2000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 16kB 0 1 2 3 4 ... 1996 1997 1998 1999 Data variables: (12/17) step_size (chain, draw) float64 64kB 0.211 0.211 ... 0.2099 tree_depth (chain, draw) int64 64kB 4 5 3 4 5 3 ... 3 3 4 4 3 3 smallest_eigval (chain, draw) float64 64kB nan nan nan ... nan nan perf_counter_start (chain, draw) float64 64kB 7.462e+05 ... 7.462e+05 lp (chain, draw) float64 64kB -9.588e+03 ... -9.589e+03 energy (chain, draw) float64 64kB 9.589e+03 ... 9.594e+03 ... ... acceptance_rate (chain, draw) float64 64kB 0.8855 0.837 ... 0.793 perf_counter_diff (chain, draw) float64 64kB 0.004076 ... 0.001634 step_size_bar (chain, draw) float64 64kB 0.2289 0.2289 ... 0.2192 n_steps (chain, draw) float64 64kB 15.0 31.0 7.0 ... 7.0 7.0 index_in_trajectory (chain, draw) int64 64kB 6 -11 -2 -5 13 ... 7 9 -6 -4 reached_max_treedepth (chain, draw) bool 8kB False False ... False False Attributes: created_at: 2025-02-05T16:31:32.205562+00:00 arviz_version: 0.20.0 inference_library: pymc inference_library_version: 5.19.1 sampling_time: 10.055245637893677 tuning_steps: 1000 -
<xarray.Dataset> Size: 57kB Dimensions: (customer_id: 2357, obs_var: 2) Coordinates: * customer_id (customer_id) int64 19kB 0 1 2 3 ... 2353 2354 2355 2356 * obs_var (obs_var) <U9 72B 'recency' 'frequency' Data variables: recency_frequency (customer_id, obs_var) float64 38kB 30.43 2.0 ... 0.0 0.0 Attributes: created_at: 2025-02-05T16:31:32.210075+00:00 arviz_version: 0.20.0 inference_library: pymc inference_library_version: 5.19.1 -
<xarray.Dataset> Size: 94kB Dimensions: (index: 2357) Coordinates: * index (index) int64 19kB 0 1 2 3 4 5 ... 2352 2353 2354 2355 2356 Data variables: customer_id (index) int64 19kB 0 1 2 3 4 5 ... 2352 2353 2354 2355 2356 frequency (index) int64 19kB 2 1 0 0 0 7 1 0 2 0 ... 7 1 2 0 0 0 5 0 4 0 recency (index) float64 19kB 30.43 1.71 0.0 0.0 ... 24.29 0.0 26.57 0.0 T (index) float64 19kB 38.86 38.86 38.86 38.86 ... 27.0 27.0 27.0
Podemos consultar la tabla resumen:
model.fit_summary()
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 6.544 | 0.733 | 5.223 | 7.894 | 0.016 | 0.011 | 2151.0 | 2838.0 | 1.0 |
| r | 0.571 | 0.088 | 0.417 | 0.732 | 0.002 | 0.001 | 1846.0 | 2481.0 | 1.0 |
| phi_dropout | 0.372 | 0.040 | 0.294 | 0.446 | 0.001 | 0.001 | 1945.0 | 2667.0 | 1.0 |
| kappa_dropout | 2.381 | 0.614 | 1.391 | 3.498 | 0.013 | 0.009 | 2173.0 | 2930.0 | 1.0 |
| a | 0.865 | 0.144 | 0.619 | 1.132 | 0.003 | 0.002 | 3159.0 | 3932.0 | 1.0 |
| b | 1.515 | 0.484 | 0.792 | 2.443 | 0.011 | 0.008 | 2024.0 | 2748.0 | 1.0 |
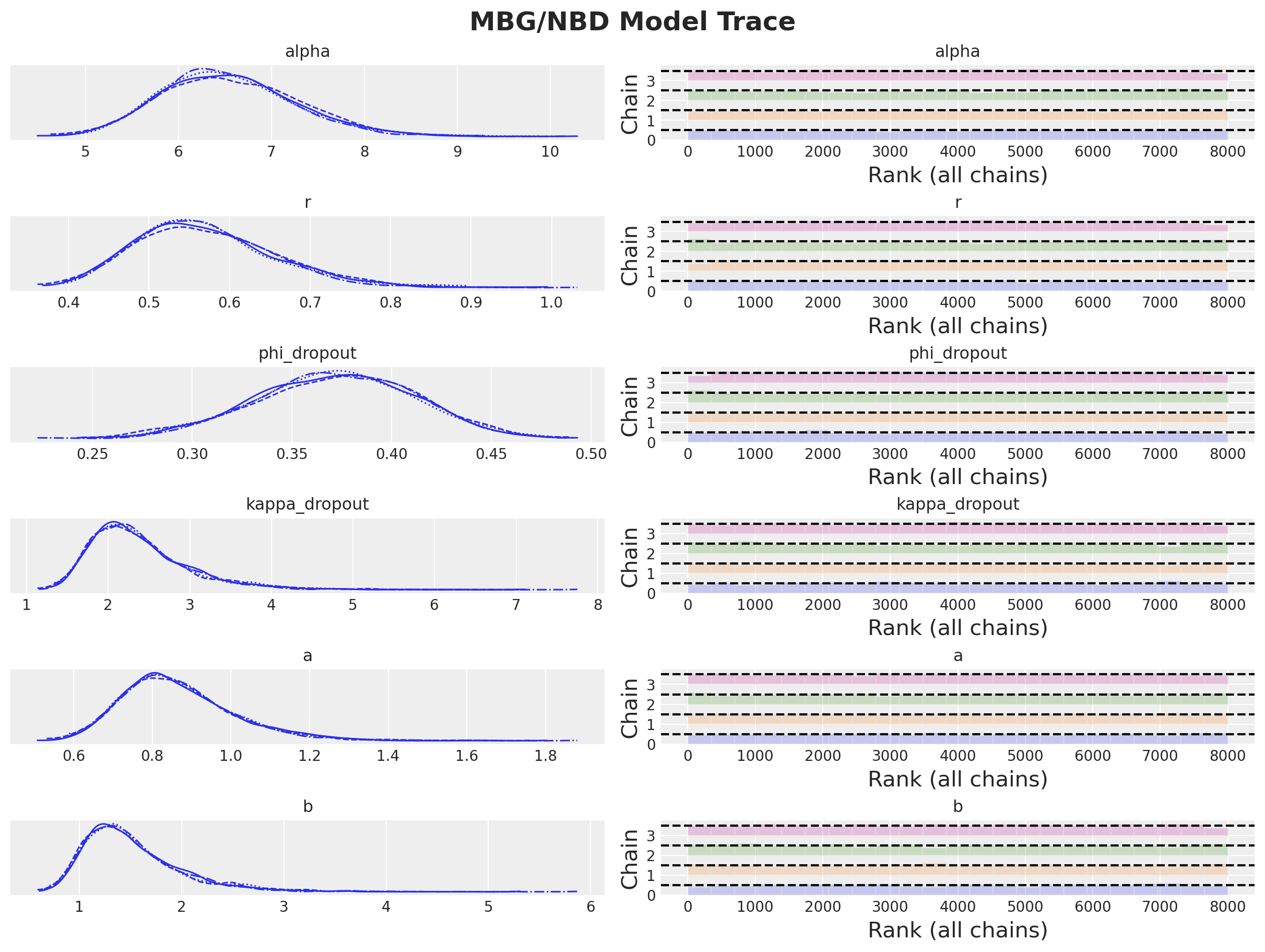
Vemos que los valores de r_hat están cerca de \(1\), lo que indica convergencia.
También podemos trazar distribuciones posteriores de los parámetros y los gráficos de rango:
axes = az.plot_trace(
data=model.idata,
compact=True,
kind="rank_bars",
backend_kwargs={"figsize": (12, 9), "layout": "constrained"},
)
plt.gcf().suptitle("MBG/NBD Model Trace", fontsize=18, fontweight="bold");
Usando el ajuste MAP#
Los modelos de CLV, como BetaGeoModel, pueden proporcionar las estimaciones máximas a posteriori utilizando un optimizador numérico (L-BFGS-B de scipy.optimize) en segundo plano.
model_map = clv.ModifiedBetaGeoModel()
idata_map = model_map.fit(
data=data,
method="map",
)
idata_map
-
<xarray.Dataset> Size: 64B Dimensions: (chain: 1, draw: 1) Coordinates: * chain (chain) int64 8B 0 * draw (draw) int64 8B 0 Data variables: alpha (chain, draw) float64 8B 6.454 r (chain, draw) float64 8B 0.5654 phi_dropout (chain, draw) float64 8B 0.3773 kappa_dropout (chain, draw) float64 8B 2.177 a (chain, draw) float64 8B 0.8215 b (chain, draw) float64 8B 1.356 Attributes: created_at: 2025-02-05T16:31:37.674865+00:00 arviz_version: 0.20.0 inference_library: pymc inference_library_version: 5.19.1 -
<xarray.Dataset> Size: 57kB Dimensions: (customer_id: 2357, obs_var: 2) Coordinates: * customer_id (customer_id) int64 19kB 0 1 2 3 ... 2353 2354 2355 2356 * obs_var (obs_var) <U9 72B 'recency' 'frequency' Data variables: recency_frequency (customer_id, obs_var) float64 38kB 30.43 2.0 ... 0.0 0.0 Attributes: created_at: 2025-02-05T16:31:37.677973+00:00 arviz_version: 0.20.0 inference_library: pymc inference_library_version: 5.19.1 -
<xarray.Dataset> Size: 94kB Dimensions: (index: 2357) Coordinates: * index (index) int64 19kB 0 1 2 3 4 5 ... 2352 2353 2354 2355 2356 Data variables: customer_id (index) int64 19kB 0 1 2 3 4 5 ... 2352 2353 2354 2355 2356 frequency (index) int64 19kB 2 1 0 0 0 7 1 0 2 0 ... 7 1 2 0 0 0 5 0 4 0 recency (index) float64 19kB 30.43 1.71 0.0 0.0 ... 24.29 0.0 26.57 0.0 T (index) float64 19kB 38.86 38.86 38.86 38.86 ... 27.0 27.0 27.0
Esta vez obtenemos estimaciones puntuales para los parámetros.
map_summary = model_map.fit_summary()
map_summary
alpha 6.454
r 0.565
phi_dropout 0.377
kappa_dropout 2.177
a 0.821
b 1.356
Name: value, dtype: float64
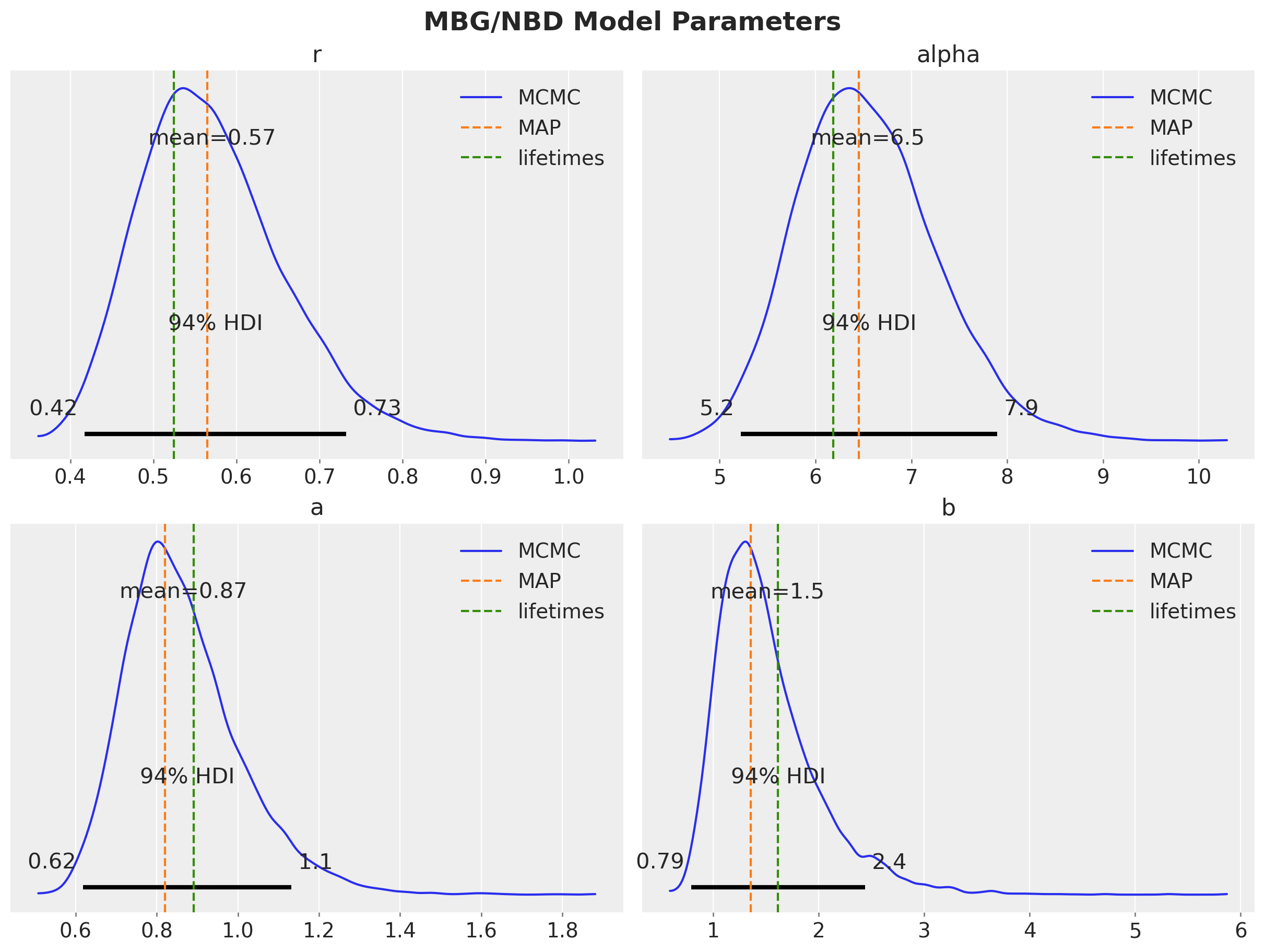
The r and alpha purchase rate parameters are quite similar for both MCMC and MAP fits, but the a and b dropout parameters are better approximated with the default parameters when fitted with MCMC.
fig, axes = plt.subplots(
nrows=2, ncols=2, figsize=(12, 9), sharex=False, sharey=False, layout="constrained"
)
axes = axes.flatten()
for i, var_name in enumerate(["r", "alpha", "a", "b"]):
ax = axes[i]
az.plot_posterior(
model.idata.posterior[var_name].values.flatten(),
color="C0",
point_estimate="mean",
ax=ax,
label="MCMC",
)
ax.axvline(x=map_summary[var_name], color="C1", linestyle="--", label="MAP")
ax.legend(loc="upper right")
ax.set_title(var_name)
plt.gcf().suptitle("MBG/NBD Model Parameters", fontsize=18, fontweight="bold");
Comprobaciones Predictivas Anteriores y Posteriores#
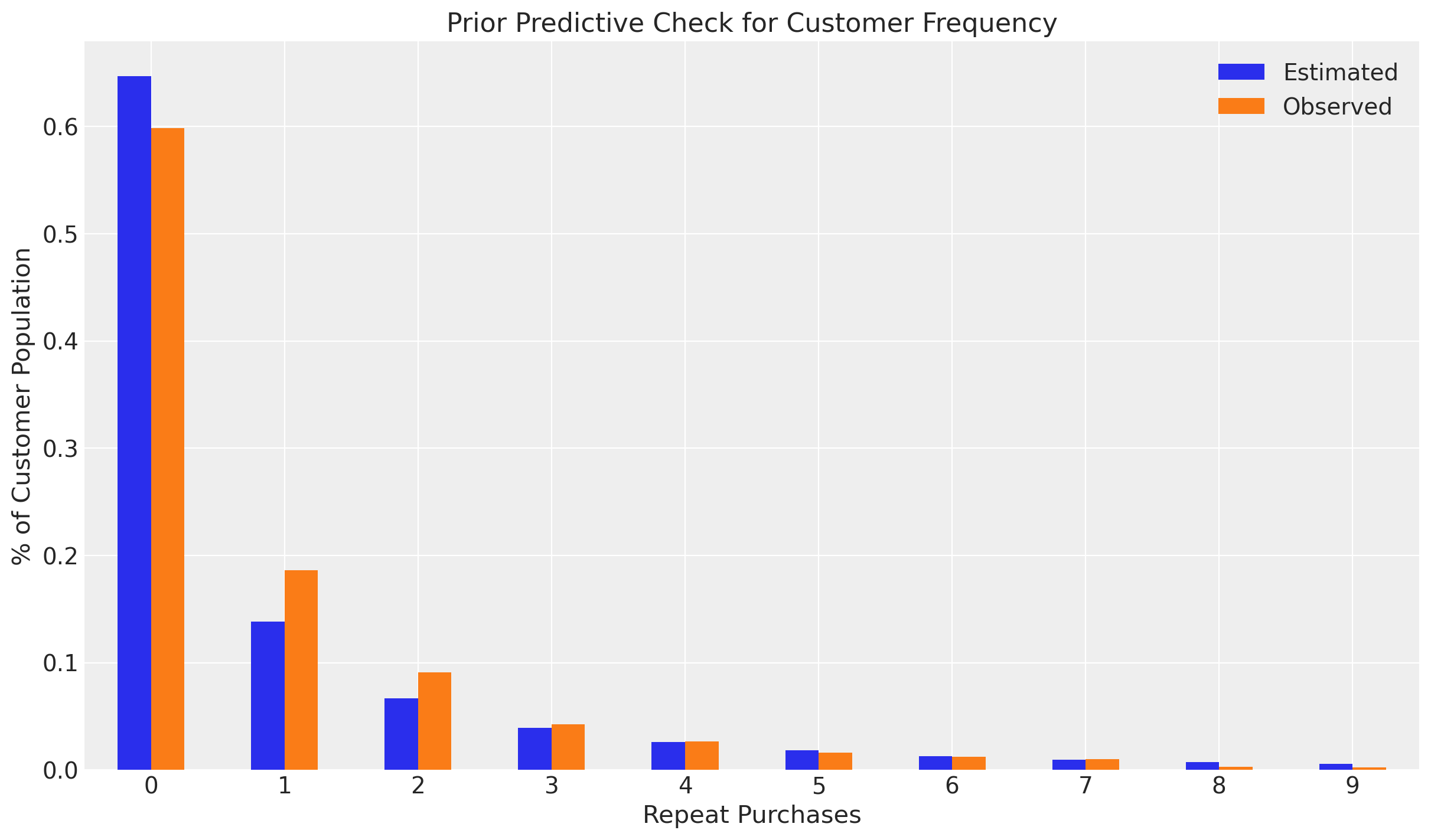
Los PPCs nos permiten verificar la eficacia de nuestras distribuciones a priori y el rendimiento de las distribuciones a posteriori ajustadas.
Veamos cómo se desempeña el modelo en una verificación predictiva previa, donde muestreamos de las distribuciones a priori predeterminadas antes de ajustar el modelo:
# PPC histogram plot
clv.plot_expected_purchases_ppc(model, ppc="prior");
Sampling: [alpha, kappa_dropout, phi_dropout, r, recency_frequency]
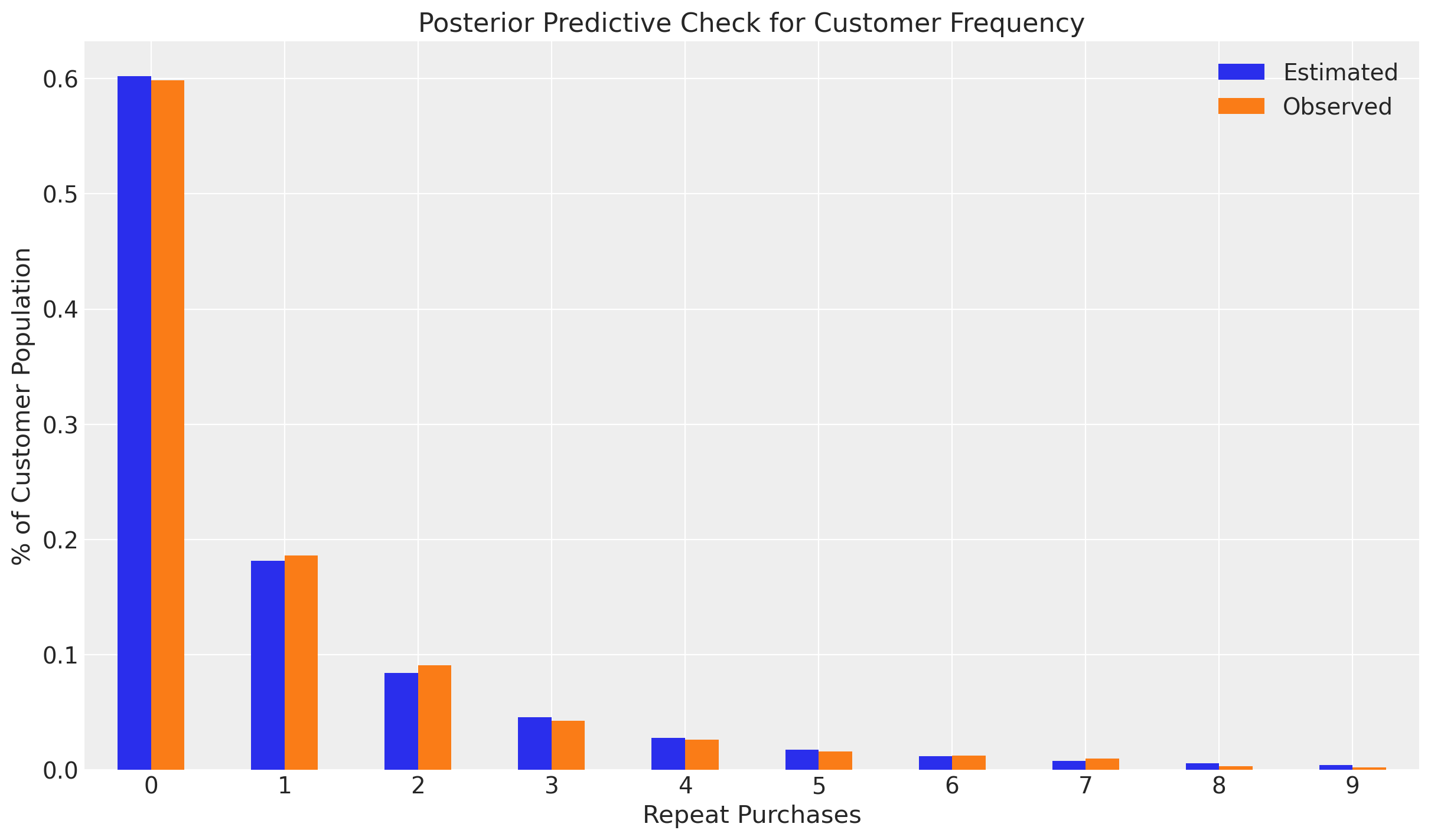
# PPC histogram plot
clv.plot_expected_purchases_ppc(model, ppc="posterior");
Sampling: [recency_frequency]
Algunas Aplicaciones#
Ahora que ha ajustado el modelo, podemos utilizarlo para hacer predicciones. Por ejemplo, podemos predecir la probabilidad esperada de que un cliente esté vivo en función del tiempo (pasos). Aquí hay un fragmento de código para hacerlo:
Número Esperado de Compras#
Tomemos una muestra de usuarios:
example_customer_ids = [1, 6, 10, 18, 45, 1412]
data_small = data.query("customer_id.isin(@example_customer_ids)")
data_small.head(6)
| customer_id | frequency | recency | T | |
|---|---|---|---|---|
| 1 | 1 | 1 | 1.71 | 38.86 |
| 6 | 6 | 1 | 5.00 | 38.86 |
| 10 | 10 | 5 | 24.43 | 38.86 |
| 18 | 18 | 3 | 28.29 | 38.71 |
| 45 | 45 | 12 | 34.43 | 38.57 |
| 1412 | 1412 | 14 | 30.29 | 31.57 |
Observe que los últimos dos clientes son compradores frecuentes en comparación con los demás.
steps = 90
expected_num_purchases_steps = xr.concat(
objs=[
model.expected_purchases(
data=data_small,
future_t=t,
)
for t in progress_bar(range(steps))
],
dim="t",
).transpose(..., "t")
Podemos trazar el número esperado de compras para los próximos \(90\) períodos:
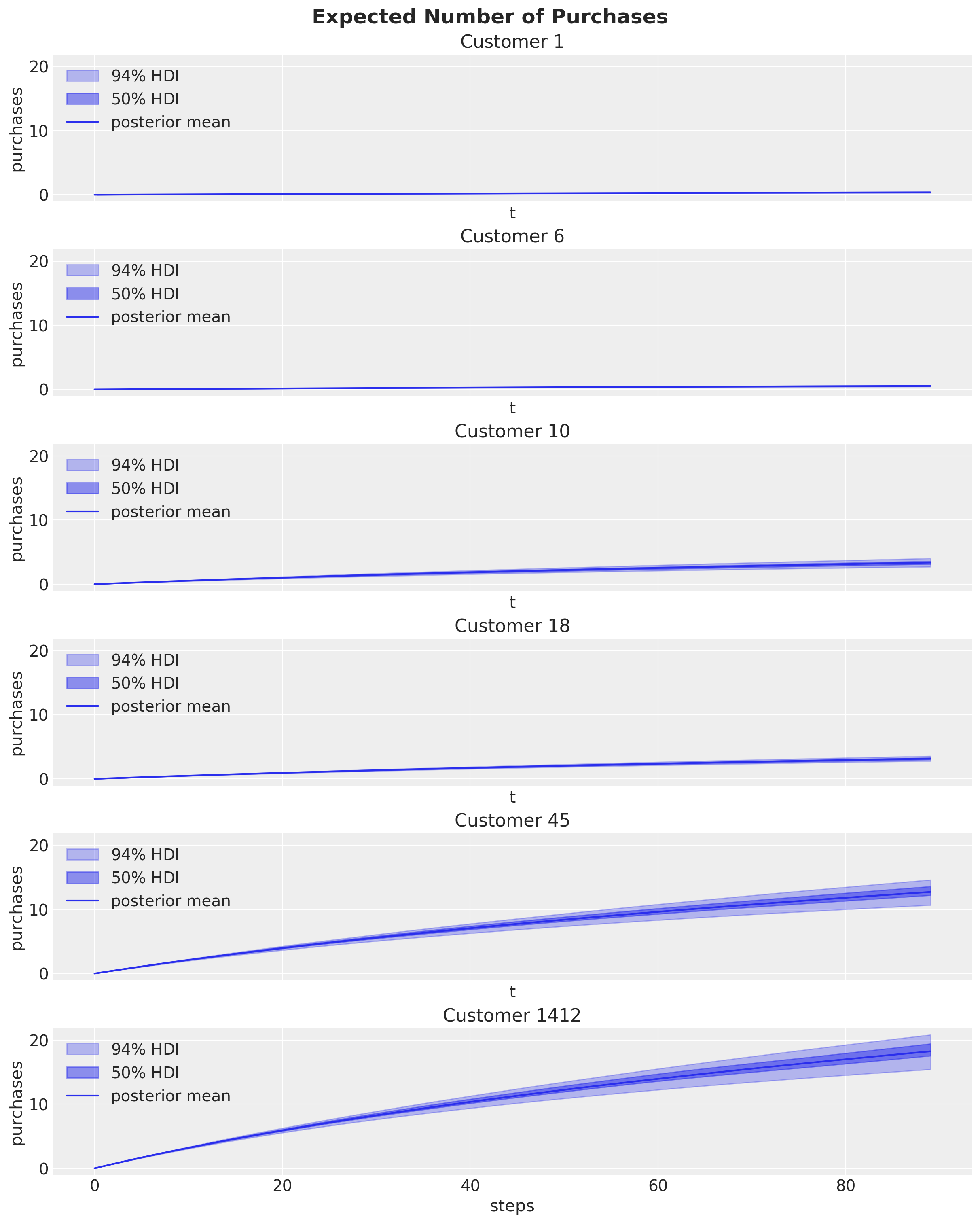
Tenga en cuenta que se espera que los compradores frecuentes realicen más compras en el futuro.
Probabilidad de que un Cliente Esté Vivo#
Ahora analizamos la probabilidad de que un cliente esté vivo durante los próximos \(90\) períodos:
steps = 90
future_alive_all = []
for t in progress_bar(range(steps)):
future_data = data_small.copy()
future_data["T"] = future_data["T"] + t
future_alive = model.expected_probability_alive(data=future_data)
future_alive_all.append(future_alive)
expected_probability_alive_steps = xr.concat(
objs=future_alive_all,
dim="t",
).transpose(..., "t")
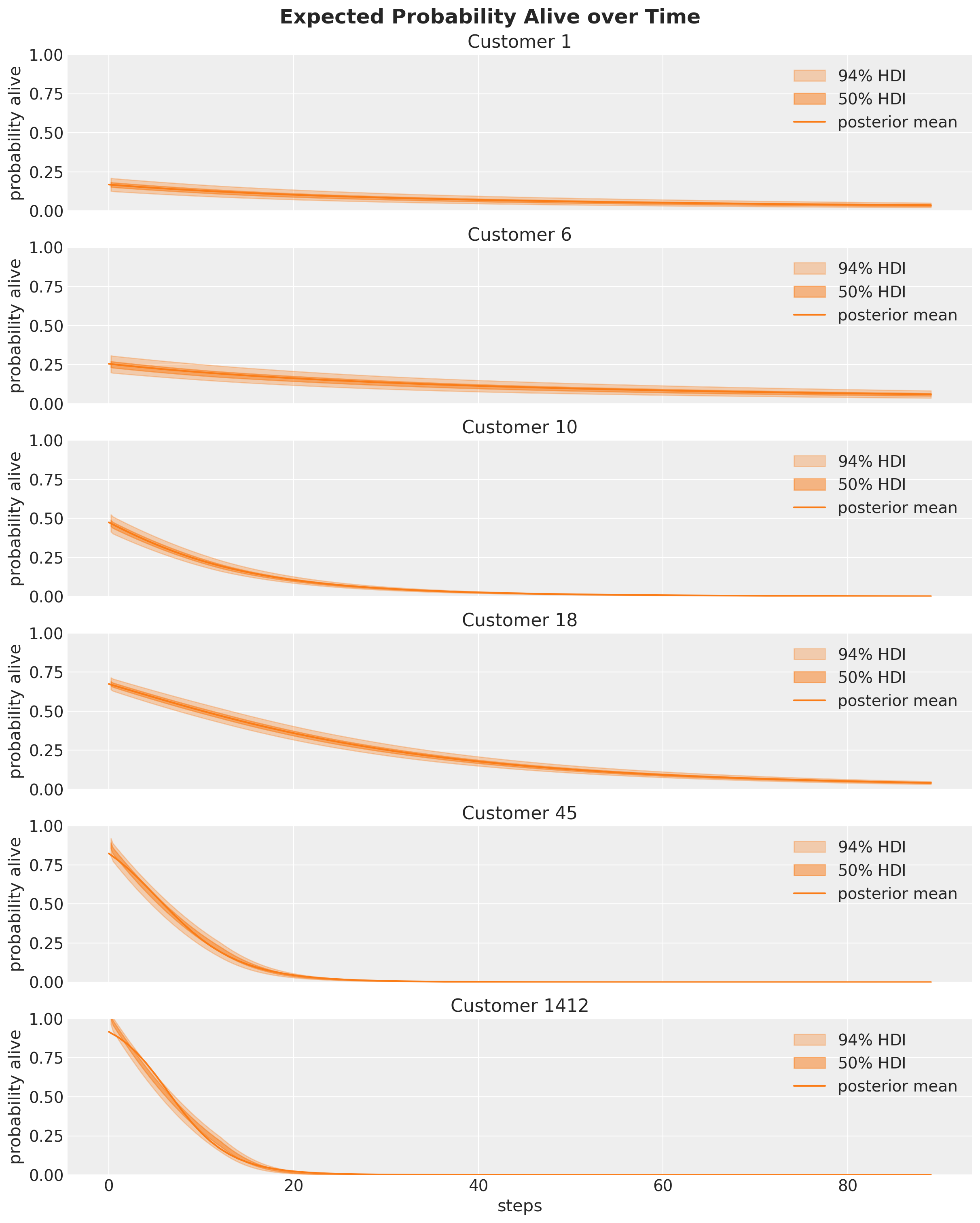
Truco
Aquí hay algunas observaciones generales:
Estos gráficos suponen que no habrá compras futuras.
La probabilidad de descomposición no es la misma, ya que depende del historial de compras del cliente.
La probabilidad de estar vivo siempre está disminuyendo, asumiendo que no hay cambios en los otros parámetros.
Estas probabilidades son siempre no negativas, como se esperaba.
Advertencia
Para los compradores frecuentes, la probabilidad de estar vivos disminuye muy rápidamente ya que asumimos que no habrá compras futuras. Es muy importante tener esto en cuenta al interpretar los resultados.
%reload_ext watermark
%watermark -n -u -v -iv -w -p pymc,pytensor
Last updated: Fri Dec 20 2024
Python implementation: CPython
Python version : 3.10.16
IPython version : 8.30.0
pymc : 5.19.1
pytensor: 2.26.4
fastprogress : 1.0.3
pymc_marketing: 0.10.0
matplotlib : 3.9.3
pandas : 2.2.3
arviz : 0.20.0
lifetimes : 0.11.3
xarray : 2024.11.0
Watermark: 2.5.0