Modelos de Elección Multinomial y la Independencia de Alternativas Irrelevantes#
import arviz as az
import matplotlib.pyplot as plt
import pandas as pd
from pymc_marketing.customer_choice.mnl_logit import MNLogit
from pymc_marketing.paths import data_dir
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
%config InlineBackend.figure_format = "retina"
Los modelos de elección discreta son una clase de modelos estadísticos utilizados para analizar y predecir las elecciones realizadas por individuos entre un conjunto finito de alternativas. El conjunto de alternativas generalmente representa una elección entre «productos» en un sentido amplio.
Estos modelos se basan en la teoría de maximización de la utilidad, donde cada opción proporciona un cierto nivel de utilidad al tomador de decisiones, y se elige la opción con la mayor utilidad percibida.
Los modelos de elección discreta se aplican ampliamente en campos como el transporte, el marketing y la economía de la salud para comprender el comportamiento e informar políticas o diseños. Las variantes comunes incluyen el modelo logit multinomial, el logit anidado y el modelo logit mixto, cada uno de los cuales captura diferentes aspectos del comportamiento de elección, como la similitud entre alternativas o la heterogeneidad individual. En este cuaderno, demostraremos cómo especificar el modelo logit multinomial y destacaremos una propiedad de este modelo conocida como la Independencia de Alternativas Irrelevantes.
Los Datos#
Examinaremos un caso de elecciones entre sistemas de calefacción. Estos datos se extraen de un ejemplo en el paquete R mlogit.
Tenga en cuenta que los datos han sido formateados de manera «amplia», donde cada fila representa un escenario de elección caracterizado por (a) el resultado elegido depvar, (b) los atributos del producto: costos de instalación (ic_x) y costos de operación (oc_x), y (c) atributos fijos del agente que toma la decisión, por ejemplo, el ingreso del consumidor y las habitaciones.
data_path = data_dir / "choice_wide_heating.csv"
df = pd.read_csv(data_path)
df
| idcase | depvar | ic_gc | ic_gr | ic_ec | ic_er | ic_hp | oc_gc | oc_gr | oc_ec | oc_er | oc_hp | income | agehed | rooms | region | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | gc | 866.00 | 962.64 | 859.90 | 995.76 | 1135.50 | 199.69 | 151.72 | 553.34 | 505.60 | 237.88 | 7 | 25 | 6 | ncostl |
| 1 | 2 | gc | 727.93 | 758.89 | 796.82 | 894.69 | 968.90 | 168.66 | 168.66 | 520.24 | 486.49 | 199.19 | 5 | 60 | 5 | scostl |
| 2 | 3 | gc | 599.48 | 783.05 | 719.86 | 900.11 | 1048.30 | 165.58 | 137.80 | 439.06 | 404.74 | 171.47 | 4 | 65 | 2 | ncostl |
| 3 | 4 | er | 835.17 | 793.06 | 761.25 | 831.04 | 1048.70 | 180.88 | 147.14 | 483.00 | 425.22 | 222.95 | 2 | 50 | 4 | scostl |
| 4 | 5 | er | 755.59 | 846.29 | 858.86 | 985.64 | 883.05 | 174.91 | 138.90 | 404.41 | 389.52 | 178.49 | 2 | 25 | 6 | valley |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 895 | 896 | gc | 766.39 | 877.71 | 751.59 | 869.78 | 942.70 | 142.61 | 136.21 | 474.48 | 420.65 | 203.00 | 6 | 20 | 4 | mountn |
| 896 | 897 | gc | 1128.50 | 1167.80 | 1047.60 | 1292.60 | 1297.10 | 207.40 | 213.77 | 705.36 | 551.61 | 243.76 | 7 | 45 | 7 | scostl |
| 897 | 898 | gc | 787.10 | 1055.20 | 842.79 | 1041.30 | 1064.80 | 175.05 | 141.63 | 478.86 | 448.61 | 254.51 | 5 | 60 | 7 | scostl |
| 898 | 899 | gc | 860.56 | 1081.30 | 799.76 | 1123.20 | 1218.20 | 211.04 | 151.31 | 495.20 | 401.56 | 246.48 | 5 | 50 | 6 | scostl |
| 899 | 900 | gc | 893.94 | 1119.90 | 967.88 | 1091.70 | 1387.50 | 175.80 | 180.11 | 518.68 | 458.53 | 245.13 | 2 | 65 | 4 | ncostl |
900 rows × 16 columns
Viendo que tenemos 5 alternativas para elegir:
df["depvar"].value_counts()
depvar
gc 573
gr 129
er 84
ec 64
hp 50
Name: count, dtype: int64
La idea de los modelos de elección discreta es determinar cómo la propensión a elegir estos productos está impulsada por sus atributos observables.
Teoría de la Utilidad y Maximización#
La idea general de estos modelos es que las elecciones de los individuos entre alternativas observadas reflejan la maximización de una función de utilidad subyacente. En este marco, cada alternativa en un conjunto de elecciones está asociada con una utilidad latente compuesta de componentes observables (por ejemplo, costo, tiempo de viaje) y factores no observables capturados como errores aleatorios. Daniel McFadden formalizó este enfoque utilizando modelos de utilidad aleatoria, incluido el modelo logit multinomial, que asume que los componentes no observados de la utilidad siguen una distribución de valor extremo. Sus modelos proporcionaron una base econométrica rigurosa para analizar el comportamiento de elección a partir de decisiones observadas, permitiendo la estimación de cómo los cambios en los atributos influyen en las probabilidades de elección. Este trabajo le valió a McFadden el Premio Nobel de Economía en 2000 y ha tenido una influencia duradera en el transporte, el marketing y la economía laboral.
Para especificar nuestro modelo de logit multinomial, especificamos, por lo tanto, la forma de las ecuaciones de utilidad que podrían llevar a los consumidores a comprar bienes particulares entre un conjunto de opciones. Observe cómo distinguimos cada una de las alternativas individuales y las covariables específicas de la alternativa y las covariables específicas del individuo utilizando la notación |. Esta es una variante de la notación de fórmula al estilo Wilkinson estándar para especificar modelos de regresión. En el fondo, ajustamos N modelos de regresión para cada uno de los N bienes. Estas regresiones se utilizan para generar una puntuación de utilidad que se alimenta a través de una transformación softmax para darnos las probabilidades de cada elección particular. La elección más probable debería ser la que tenga la mayor utilidad predicha.
Para más detalles sobre la teoría de fondo y las variedades de especificación de utilidad, consulte el ejemplo de PyMC aquí
utility_formulas = [
"gc ~ ic_gc + oc_gc | income + rooms + agehed",
"gr ~ ic_gr + oc_gr | income + rooms + agehed",
"ec ~ ic_ec + oc_ec | income + rooms + agehed",
"er ~ ic_er + oc_er | income + rooms + agehed",
"hp ~ ic_hp + oc_hp | income + rooms + agehed",
]
mnl = MNLogit(df, utility_formulas, "depvar", covariates=["ic", "oc"])
mnl
<pymc_marketing.customer_choice.mnl_logit.MNLogit at 0x16680a120>
Una vez que hemos inicializado nuestra clase de modelo, podemos estimar el modelo con el comando de muestra.
mnl.sample(
fit_kwargs={
"target_accept": 0.97,
"tune": 2000,
"idata_kwargs": {"log_likelihood": True},
"nuts_sampler": "nutpie",
"progressbar": True,
}
)
Sampling: [alphas_, betas, betas_fixed_, likelihood]
/Users/nathanielforde/mambaforge/envs/pymc-marketing-dev/lib/python3.12/site-packages/pymc/sampling/mcmc.py:328: UserWarning: `idata_kwargs` are currently ignored by the nutpie sampler
warnings.warn(
Sampler Progress
Total Chains: 4
Active Chains: 0
Finished Chains: 4
Sampling for a minute
Estimated Time to Completion: now
| Progress | Draws | Divergences | Step Size | Gradients/Draw |
|---|---|---|---|---|
| 3000 | 0 | 0.10 | 63 | |
| 3000 | 0 | 0.10 | 63 | |
| 3000 | 0 | 0.10 | 31 | |
| 3000 | 0 | 0.09 | 63 |
Sampling: [likelihood]
<pymc_marketing.customer_choice.mnl_logit.MNLogit at 0x16680a120>
Podemos acceder entonces al objeto de datos de inferencia ajustada para inspeccionar las estimaciones posteriores de los parámetros del modelo de interés.
az.summary(mnl.idata, var_names=["alphas", "betas", "betas_fixed"])
/Users/nathanielforde/mambaforge/envs/pymc-marketing-dev/lib/python3.12/site-packages/arviz/stats/diagnostics.py:596: RuntimeWarning: invalid value encountered in scalar divide
(between_chain_variance / within_chain_variance + num_samples - 1) / (num_samples)
/Users/nathanielforde/mambaforge/envs/pymc-marketing-dev/lib/python3.12/site-packages/arviz/stats/diagnostics.py:991: RuntimeWarning: invalid value encountered in scalar divide
varsd = varvar / evar / 4
/Users/nathanielforde/mambaforge/envs/pymc-marketing-dev/lib/python3.12/site-packages/arviz/stats/diagnostics.py:596: RuntimeWarning: invalid value encountered in scalar divide
(between_chain_variance / within_chain_variance + num_samples - 1) / (num_samples)
/Users/nathanielforde/mambaforge/envs/pymc-marketing-dev/lib/python3.12/site-packages/arviz/stats/diagnostics.py:991: RuntimeWarning: invalid value encountered in scalar divide
varsd = varvar / evar / 4
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alphas[gc] | 1.376 | 0.725 | 0.059 | 2.763 | 0.026 | 0.017 | 771.0 | 1191.0 | 1.0 |
| alphas[gr] | 0.354 | 0.796 | -1.177 | 1.796 | 0.027 | 0.018 | 851.0 | 1268.0 | 1.0 |
| alphas[ec] | 0.778 | 1.030 | -1.182 | 2.693 | 0.033 | 0.017 | 978.0 | 1654.0 | 1.0 |
| alphas[er] | 2.301 | 0.946 | 0.554 | 4.145 | 0.031 | 0.018 | 946.0 | 1562.0 | 1.0 |
| alphas[hp] | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | NaN | 4000.0 | 4000.0 | NaN |
| betas[ic] | -0.002 | 0.001 | -0.003 | -0.000 | 0.000 | 0.000 | 4764.0 | 3064.0 | 1.0 |
| betas[oc] | -0.007 | 0.002 | -0.010 | -0.004 | 0.000 | 0.000 | 2281.0 | 2669.0 | 1.0 |
| betas_fixed[gc, income] | -0.062 | 0.084 | -0.215 | 0.103 | 0.002 | 0.002 | 1146.0 | 1663.0 | 1.0 |
| betas_fixed[gc, rooms] | 0.002 | 0.084 | -0.149 | 0.164 | 0.002 | 0.001 | 1296.0 | 2012.0 | 1.0 |
| betas_fixed[gc, agehed] | 0.016 | 0.011 | -0.004 | 0.036 | 0.000 | 0.000 | 967.0 | 1735.0 | 1.0 |
| betas_fixed[gr, income] | -0.168 | 0.096 | -0.356 | 0.007 | 0.003 | 0.002 | 1294.0 | 1602.0 | 1.0 |
| betas_fixed[gr, rooms] | -0.012 | 0.095 | -0.193 | 0.165 | 0.003 | 0.001 | 1410.0 | 2291.0 | 1.0 |
| betas_fixed[gr, agehed] | 0.019 | 0.012 | -0.004 | 0.042 | 0.000 | 0.000 | 1089.0 | 1772.0 | 1.0 |
| betas_fixed[ec, income] | -0.054 | 0.112 | -0.267 | 0.147 | 0.003 | 0.002 | 1475.0 | 1942.0 | 1.0 |
| betas_fixed[ec, rooms] | 0.055 | 0.109 | -0.156 | 0.254 | 0.003 | 0.002 | 1591.0 | 2483.0 | 1.0 |
| betas_fixed[ec, agehed] | 0.020 | 0.014 | -0.005 | 0.046 | 0.000 | 0.000 | 1307.0 | 1943.0 | 1.0 |
| betas_fixed[er, income] | -0.089 | 0.105 | -0.283 | 0.113 | 0.003 | 0.002 | 1337.0 | 1832.0 | 1.0 |
| betas_fixed[er, rooms] | 0.034 | 0.102 | -0.161 | 0.221 | 0.003 | 0.002 | 1487.0 | 2175.0 | 1.0 |
| betas_fixed[er, agehed] | -0.005 | 0.013 | -0.030 | 0.019 | 0.000 | 0.000 | 1266.0 | 2002.0 | 1.0 |
| betas_fixed[hp, income] | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | NaN | 4000.0 | 4000.0 | NaN |
| betas_fixed[hp, rooms] | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | NaN | 4000.0 | 4000.0 | NaN |
| betas_fixed[hp, agehed] | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | NaN | 4000.0 | 4000.0 | NaN |
Observe aquí cómo los coeficientes beta asociados a los costos de instalación y operación son negativos, lo que implica que los aumentos unitarios en el costo provocan una disminución en la utilidad subjetiva latente en toda la base de consumidores. Es este tipo de conocimiento conductual sobre los atributos de cada producto lo que estos modelos están destinados a descubrir.
Sin embargo, se debe tener cuidado en la interpretación de los parámetros en estos modelos. Fundamentalmente, los modelos de elección discreta son una especie de modelo de inferencia causal donde nuestro objetivo no es simplemente hacer inferencias sobre las relaciones en los datos, sino hacer afirmaciones sobre los efectos causales de los cambios en los atributos del producto, por ejemplo, ¿cómo responde el mercado a los cambios de precio? El criterio de adecuación de un modelo de elección discreta está relacionado con cuán plausibles son como guías para la acción futura y la acción en escenarios contrafactuales.
Nueva intervención de precios#
¿Considera la siguiente intervención? ¿Cómo podría responder la población consumidora a una intervención de precios que se dirige a un segmento de mercado particular? Podemos ajustar el modelo logit multinomial como antes bajo una intervención de precios.
new_policy_df = df.copy()
new_policy_df[["ic_ec", "ic_er"]] = new_policy_df[["ic_ec", "ic_er"]] * 1.5
idata_new_policy = mnl.apply_intervention(new_choice_df=new_policy_df)
Sampling: [likelihood]
Entonces podemos inspeccionar cómo se actualiza la cuota de mercado asignada a cada uno de los productos después de esta intervención de precios. Por un lado, tiene sentido observar una caída en la demanda de los sistemas de calefacción eléctrica que acaban de experimentar un aumento de precio. Sin embargo, también podemos notar un hecho curioso sobre la asignación de cuotas para los tres bienes restantes. Cada uno de los bienes absorbe un aumento igual de 0.08 en su cuota de mercado. Esto no es una casualidad.
La observación proviene de la propiedad IIA del modelo logit multinomial. Bajo intervenciones contrafactuales, los cambios en el mercado conducen a patrones de sustitución de mercado algo contraintuitivos. Los bienes restantes en el mercado exhiben sustitución proporcional, donde todas las opciones restantes «compiten» de manera equitativa. Esta es a menudo una suposición bastante implausible sobre el comportamiento del mercado porque no respeta las propiedades de la estructura del mercado o de las preferencias. En nuestro caso, podemos preguntarnos si los consumidores inclinados hacia los sistemas de calefacción eléctrica se dirigirían todos por igual hacia los sistemas de gas o si existe un sesgo inherente en ese grupo de consumidores hacia los sistemas de bomba de calor más ecológicos.
change_df = mnl.calculate_share_change(mnl.idata, mnl.intervention_idata)
change_df
| policy_share | new_policy_share | relative_change | |
|---|---|---|---|
| product | |||
| gc | 0.636682 | 0.689173 | 0.082443 |
| gr | 0.143194 | 0.155058 | 0.082856 |
| ec | 0.070832 | 0.043271 | -0.389108 |
| er | 0.093264 | 0.051614 | -0.446580 |
| hp | 0.056027 | 0.060884 | 0.086683 |
fig = mnl.plot_change(change_df, figsize=(20, 8))
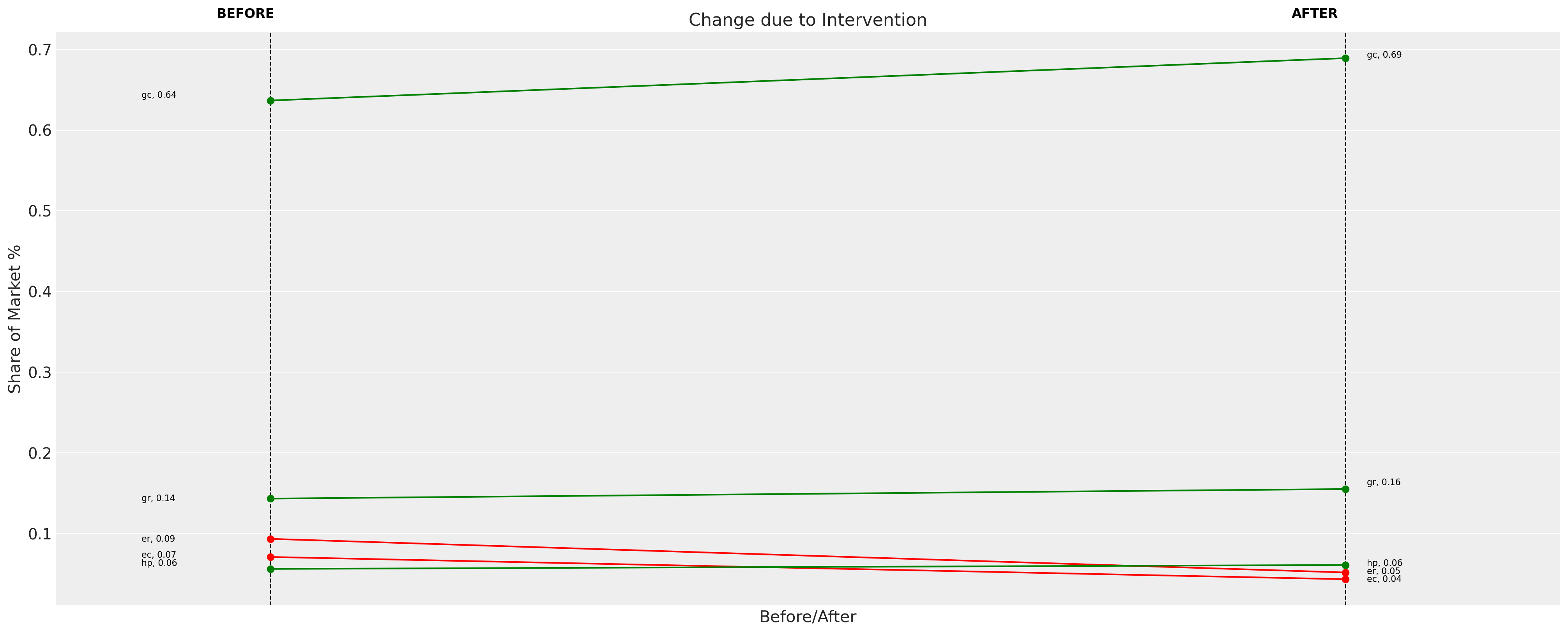
La idea de la preferencia estructural o los patrones de sustitución no proporcionales simplemente no pueden ser explicados con el modelo logit multinomial. Esto se llama ocasionalmente el paradoja del autobús rojo y el autobús azul porque la propiedad del modelo implica que incluso en un mercado de transporte con un 50% entre un coche y un autobús. Si introducimos otro autobús similar en todos los aspectos al original, entonces el nuevo mercado se divide equitativamente entre los tres bienes, lo que da una participación del 33% para cada uno. Esto parece incorrecto porque un nuevo autobús debería solo canibalizar la cuota de mercado de los consumidores de autobuses.
Veamos cómo se desarrolla este patrón en nuestro ejemplo. Podemos eliminar un producto de la siguiente manera y volver a estimar nuestro logit multinomial.
Intervención de Producto en el Mercado#
new_policy_df = df.copy()
new_policy_df = new_policy_df[new_policy_df["depvar"] != "hp"]
new_utility_formulas = [
"gc ~ ic_gc + oc_gc | income + rooms + agehed",
"gr ~ ic_gr + oc_gr | income + rooms + agehed",
"ec ~ ic_ec + oc_ec | income + rooms + agehed",
"er ~ ic_er + oc_er | income + rooms + agehed",
]
idata_new_policy = mnl.apply_intervention(
new_choice_df=new_policy_df, new_utility_equations=new_utility_formulas
)
Sampling: [alphas_, betas, betas_fixed_, likelihood]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alphas_, betas, betas_fixed_]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 103 seconds.
Sampling: [likelihood]
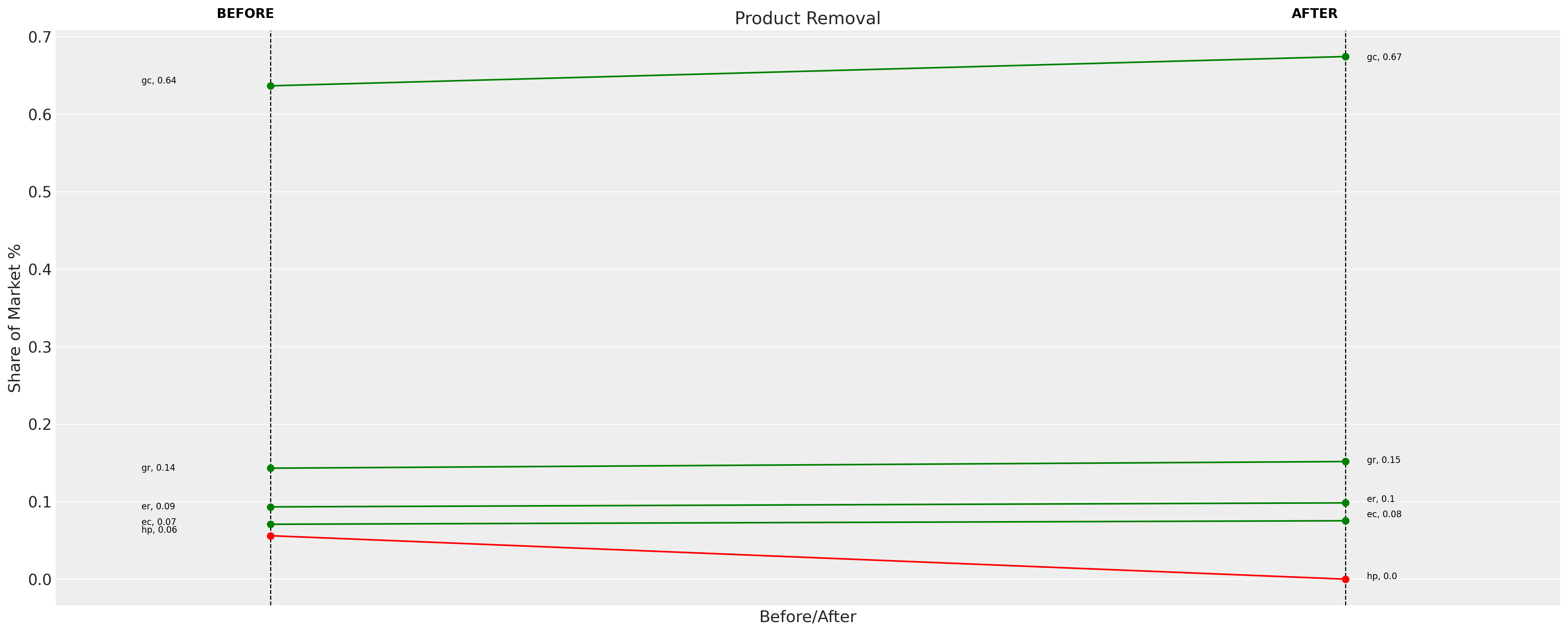
Aquí nuevamente vemos una reasignación básicamente proporcional donde la demanda del mercado se redistribuye equitativamente entre los bienes restantes.
change_df = mnl.calculate_share_change(mnl.idata, mnl.intervention_idata)
change_df
| policy_share | new_policy_share | relative_change | |
|---|---|---|---|
| product | |||
| gc | 0.636682 | 0.674460 | 0.059335 |
| gr | 0.143194 | 0.151770 | 0.059894 |
| ec | 0.070832 | 0.075343 | 0.063679 |
| er | 0.093264 | 0.098427 | 0.055355 |
| hp | 0.056027 | 0.000000 | -1.000000 |
fig = mnl.plot_change(change_df, title="Product Removal", figsize=(20, 8))
Plausibilidad contrafactual como criterio de adecuación#
Kenneth Train observa que
La propiedad [IIA] puede verse como una restricción impuesta por el modelo o como el resultado natural de un modelo bien especificado que captura todas las fuentes de correlación entre alternativas en una utilidad representativa, de modo que solo queda ruido blanco. A menudo, el investigador no puede capturar todas las fuentes de correlación de manera explícita, de modo que las porciones no observadas de la utilidad están correlacionadas y la IIA no se cumple.
lo que sugiere que el modelo Logit multinomial puede tener un papel convincente en los mercados donde la estructura de las preferencias no está gobernada por nada que no hayamos incluido en las ecuaciones de utilidad. Pero dada la dificultad de una especificación de modelo tan completa, podríamos querer buscar especificaciones de modelo alternativas que puedan apoyar inferencias contrafactuales más plausibles sobre los patrones de sustitución en el mercado bajo intervención. Una de estas especificaciones de modelo es el modelo logit anidado.
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Mon Jan 19 2026
Python implementation: CPython
Python version : 3.12.12
IPython version : 9.8.0
pytensor: 2.36.3
pymc_marketing: 0.17.1
matplotlib : 3.10.8
arviz : 0.23.0
pandas : 2.3.3
Watermark: 2.5.0