Modelos personalizados con componentes MMM#
Los componentes subyacentes utilizados en la clase MMM ofrecen flexibilidad para construir otros modelos personalizados. Con un poco de conocimiento de PyMC y de cómo personalizar estos componentes de PyMC-Marketing, se pueden cubrir muchos casos de uso diferentes.
Este cuaderno no es una introducción, sino un ejemplo avanzado para aquellos que intentan comprender los internals de PyMC-Marketing para la flexibilidad en casos de uso personalizados.
Descripción general#
Este cuaderno cubrirá los componentes del modelo actualmente expuestos de la API de PyMC-Marketing. En este momento, esto incluye:
transformaciones de medios
adstock: cómo los medios de hoy tienen un efecto en el futuro
saturación: los rendimientos decrecientes para los medios
estacionalidad recurrente
Para cada uno de estos, se mostrará la flexibilidad y personalización, combinándolas en un modelo de juguete directamente con PyMC.
Configuración#
from functools import partial
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import pymc.dims as pmd
import xarray as xr
from pymc_extras.prior import Prior
from xarray import DataArray
from pymc_marketing import mmm
from pymc_marketing.mmm.events import (
AsymmetricGaussianBasis,
EventEffect,
GaussianBasis,
HalfGaussianBasis,
)
from pymc_marketing.plot import plot_curve
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
%config InlineBackend.figure_format = "retina"
/home/ricardo/Documents/pymc/pymc/dims/__init__.py:66: UserWarning: The `pymc.dims` module is experimental and may contain critical bugs (p=0.087).
Please report any issues you encounter at https://github.com/pymc-devs/pymc/issues.
API changes are expected in future releases.
__init__()
seed = sum(map(ord, "PyMC-Marketing provides flexible model components"))
rng = np.random.default_rng(seed)
draw = partial(pm.draw, random_seed=rng)
Transformaciones de Medios#
Hay clases para cada una de las transformaciones de adstock y saturación. Pueden ser importadas del módulo pymc_marketing.mmm.
saturation = mmm.MichaelisMentenSaturation()
Las curvas de saturación pueden adoptar muchas formas diferentes. En este ejemplo, utilizaremos la curva de Michaelis-Menten que proporcionamos en la clase MichaelisMentenSaturation.
Esta curva tiene dos parámetros, alpha y lam.
Una característica de estas curvas son los rendimientos decrecientes para indicar la saturación de una variable media. Esto se puede observar en el estancamiento a medida que x aumenta.
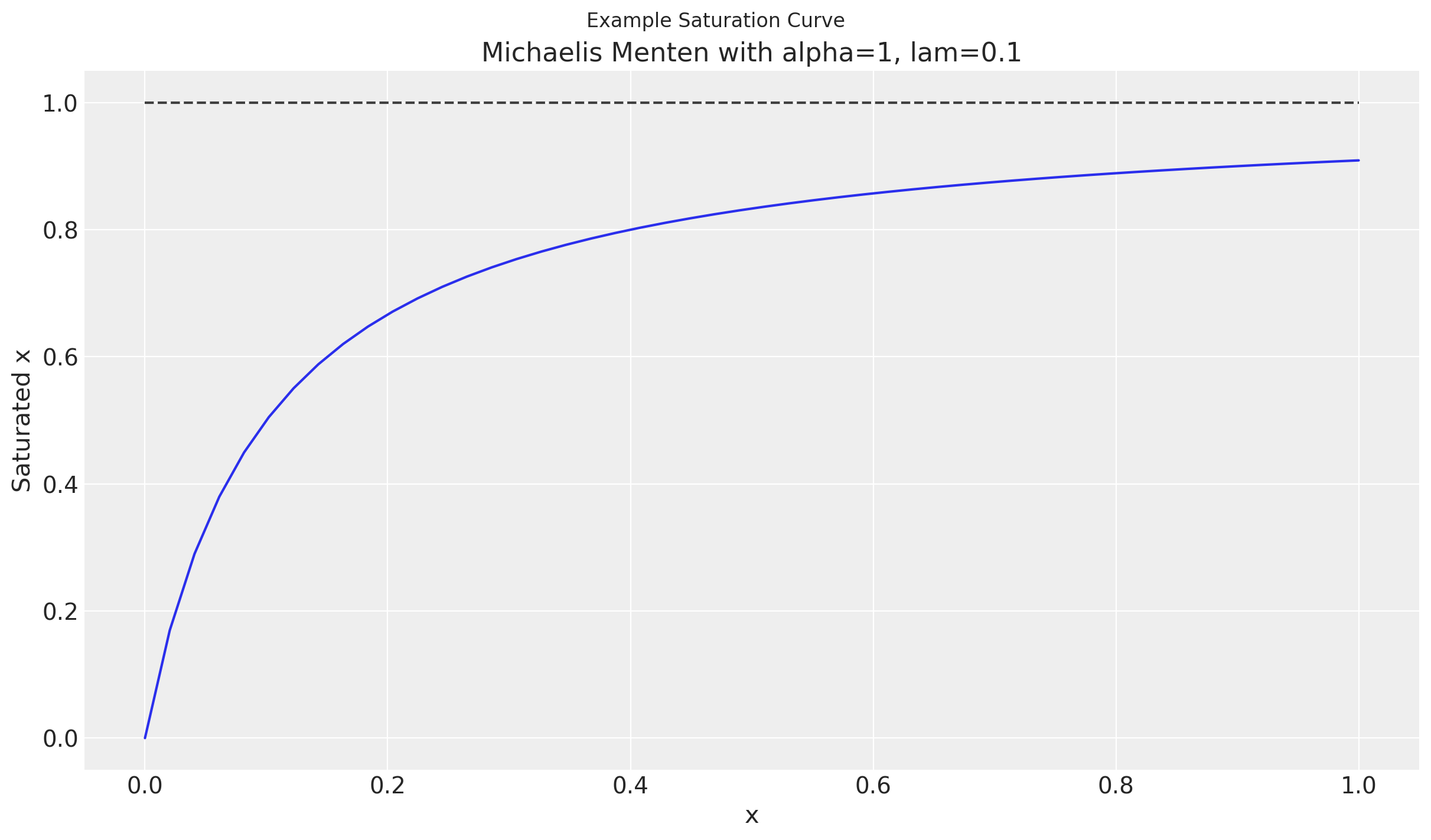
Función de Transformación de Muestreo#
Cada una de las transformaciones tendrá un conjunto de priors predeterminados. Estos pueden ser modificados en la inicialización con el parámetro priors, pero finalmente se almacenarán en el atributo function_priors de la instancia. Habrá un prior para cada uno de los parámetros estimados utilizados en la función.
saturation.function_priors
{'alpha': Prior("Gamma", mu=2, sigma=1), 'lam': Prior("HalfNormal", sigma=1)}
El método sample_prior se puede utilizar para muestrear los parámetros de las funciones.
Nota
Hay el prefijo saturation_ en cada uno de los parámetros para no chocar con el modelo más grande. Este es el valor predeterminado, pero también se puede cambiar.
parameters = saturation.sample_prior(random_seed=rng)
parameters
Sampling: [saturation_alpha, saturation_lam]
<xarray.Dataset> Size: 12kB
Dimensions: (chain: 1, draw: 500)
Coordinates:
* chain (chain) int64 8B 0
* draw (draw) int64 4kB 0 1 2 3 4 5 6 ... 494 495 496 497 498 499
Data variables:
saturation_lam (chain, draw) float64 4kB 0.7597 0.09256 ... 0.8022 0.8724
saturation_alpha (chain, draw) float64 4kB 2.114 0.8256 ... 2.056 2.347
Attributes:
created_at: 2026-02-26T17:13:52.356815+00:00
arviz_version: 0.23.1
inference_library: pymc
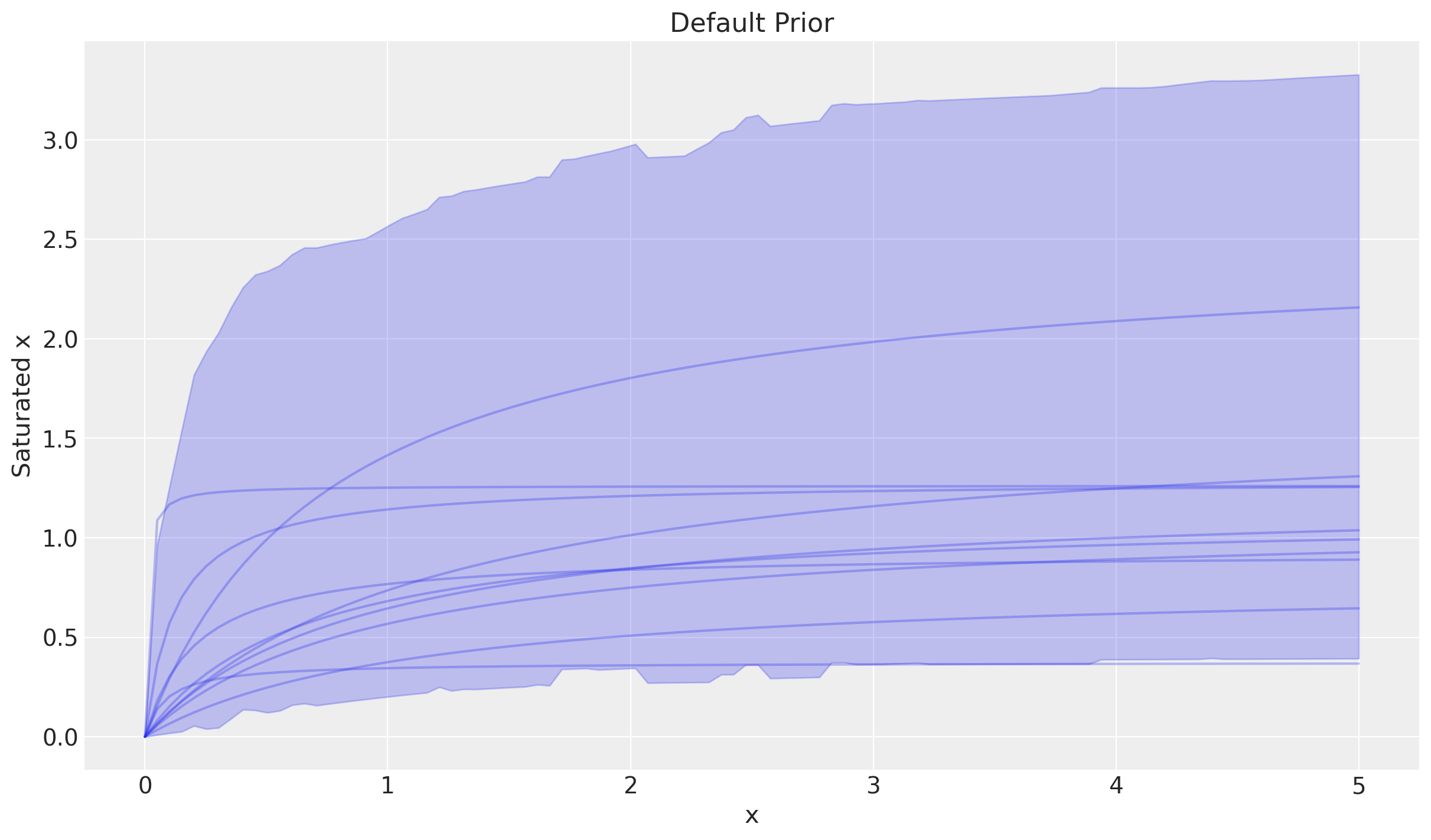
inference_library_version: 5.28.0Con parámetros para la función, la curva también se puede muestrear. Combinar sample_curve y plot_curve juntos puede proporcionar una buena visión de la forma que toma la curva.
Esto muestra las curvas más probables bajo las distribuciones a priori.
curve = saturation.sample_curve(parameters, max_value=5)
_, axes = saturation.plot_curve(curve)
axes[0].set(
ylabel="Saturated x",
title="Default Prior",
);
Sampling: []
Truco
El posterior puede ser utilizado en lugar del anterior en ambos métodos sample_curve y plot_curve. ¡Cualquier coordenada adicional de los parámetros será manejada automáticamente!
Añadiendo Dimensiones de Parámetro#
En la mayoría de los casos, se estimará una función de saturación separada para cada canal de medios. Se necesita agregar una dimensión al prior de los parámetros de la función para tener en cuenta esto.
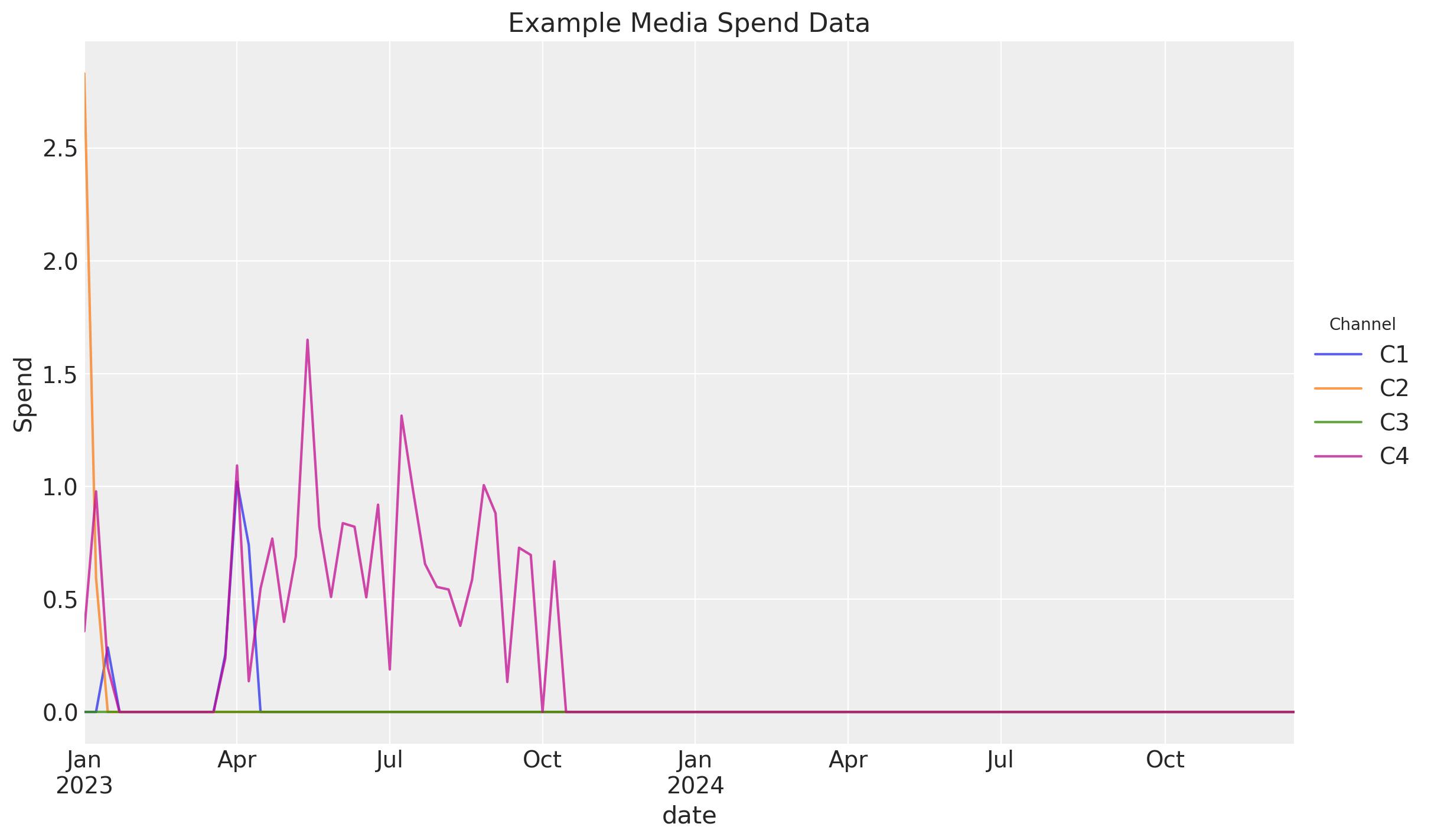
Creemos algunos datos de ejemplo para trabajar en esta transformación.
Para este ejemplo, tendremos 2 años de gasto en medios para 4 canales.
n_dates = 52 * 2
dates = pd.date_range("2023-01-01", periods=n_dates, freq="W-MON")
channels = ["C1", "C2", "C3", "C4"]
coords = {
"date": dates,
"channel": channels,
}
df_spends = random_spends(coords=coords).to_pandas()
df_spends.head()
| channel | C1 | C2 | C3 | C4 |
|---|---|---|---|---|
| date | ||||
| 2023-01-02 | 0.000000 | 2.830228 | 0.0 | 0.357625 |
| 2023-01-09 | 0.000000 | 0.594478 | 0.0 | 0.977781 |
| 2023-01-16 | 0.285379 | 0.000000 | 0.0 | 0.197317 |
| 2023-01-23 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| 2023-01-30 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
Como se mencionó, los priors predeterminados no tienen una dimensión de canal. Para utilizarlos en nuestro modelo con dimensión de «canal», debemos agregar las dimensiones a cada uno de los priors de función.
for dist in saturation.function_priors.values():
dist.dims = "channel"
saturation.function_priors
{'alpha': Prior("Gamma", mu=2, sigma=1, dims="channel"),
'lam': Prior("HalfNormal", sigma=1, dims="channel")}
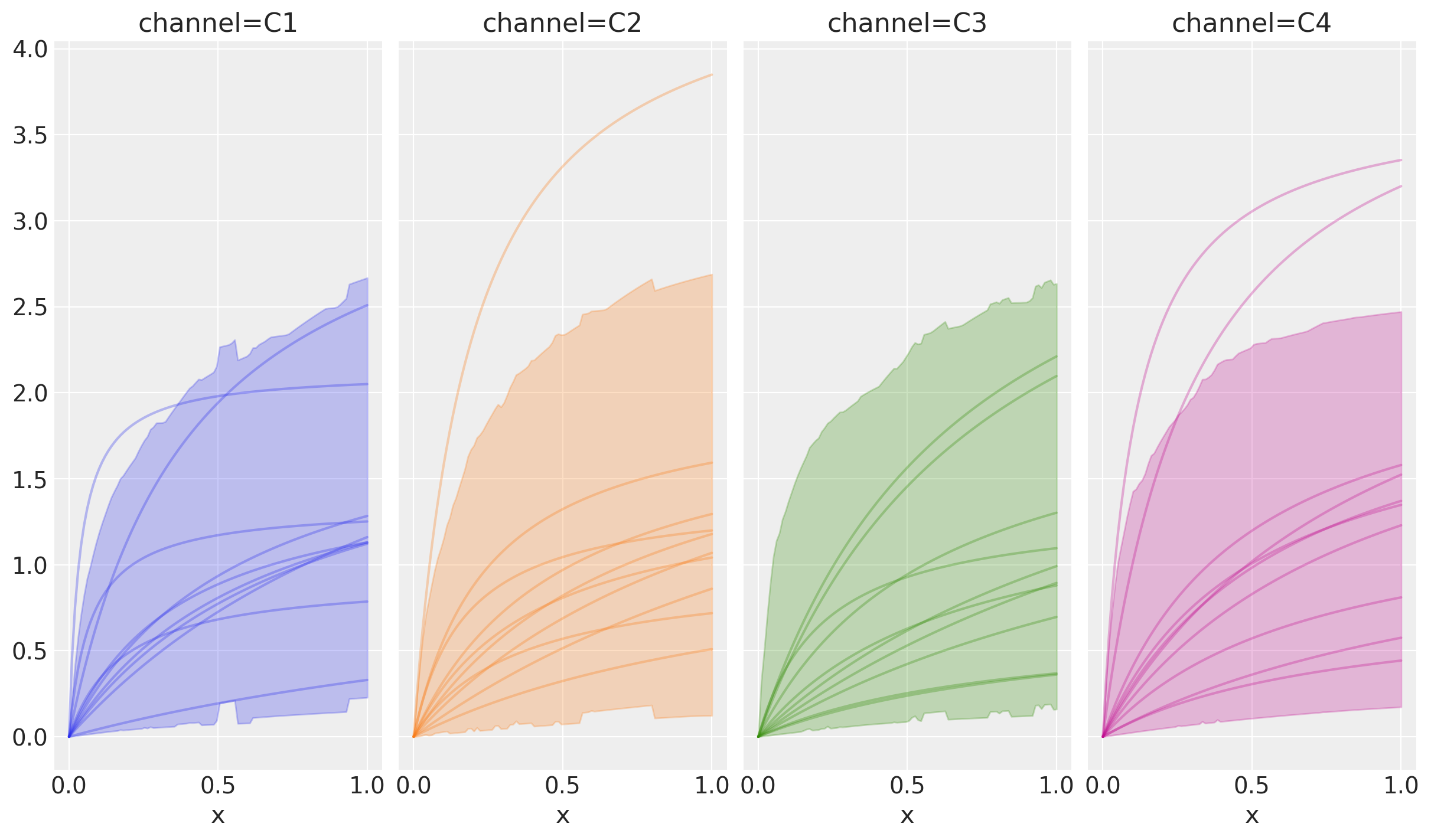
El flujo de trabajo anterior se puede utilizar para comprender nuestros priors aún. Simplemente pase las coords al método sample_prior para agregar dimensiones a las variables apropiadas.
prior = saturation.sample_prior(coords=coords, random_seed=rng)
prior
Sampling: [saturation_alpha, saturation_lam]
<xarray.Dataset> Size: 36kB
Dimensions: (chain: 1, draw: 500, channel: 4)
Coordinates:
* chain (chain) int64 8B 0
* draw (draw) int64 4kB 0 1 2 3 4 5 6 ... 494 495 496 497 498 499
* channel (channel) <U2 32B 'C1' 'C2' 'C3' 'C4'
Data variables:
saturation_lam (chain, draw, channel) float64 16kB 0.6277 ... 1.778
saturation_alpha (chain, draw, channel) float64 16kB 1.348 2.211 ... 2.639
Attributes:
created_at: 2026-02-26T17:13:53.382944+00:00
arviz_version: 0.23.1
inference_library: pymc
inference_library_version: 5.28.0Dado que cada canal previo es el mismo, solo habrá algo de ruido entre las muestras de HDI y de la curva.
curve = saturation.sample_curve(prior)
saturation.plot_curve(curve);
Sampling: []
Usando en el modelo de PyMC#
Al utilizar la transformación en un modelo más grande de PyMC, se utilizará el método apply.
Este método hará:
crear distribuciones basadas en la especificación previa de la instancia
aplicar la transformación a los datos
El parámetro dims es la forma de los parámetros y no de los datos. Los datos tienen una forma diferente, pero deberán ser compatibles para la transmisión con los parámetros.
with pm.Model(coords=coords) as model:
saturated_spends = saturation.apply(
DataArray(
df_spends.values,
dims=(
"date",
"channel",
),
)
)
Dado que se especificaron alpha y lam independientes, vemos que en el gráfico del modelo a continuación:
pm.model_to_graphviz(model)

Nota
Neither the df_spends nor saturated_spends show in the model. If needed, use pmd.Data and pmd.Deterministic to save off.
Nuestra variable será (fecha, canal) dimensiones.
saturated_spends.type.shape

Podemos manipular esto de cualquier manera que deseemos para conectarlo con el modelo más grande.
Cambiando Suposiciones#
Como se insinuó anteriormente, los priors para los parámetros de la función son personalizables, lo que puede dar lugar a muchos modelos diferentes. Cambie los priors, cambie el modelo.
Las distribuciones previas solo necesitan seguir la API de distribución aquí.
En lugar de los valores predeterminados, podemos usar:
parámetro jerárquico para el parámetro
lamparámetro
alphacomún
hierarchical_lam = Prior(
"HalfNormal",
sigma=Prior("HalfNormal", sigma=1),
dims="channel",
)
common_alpha = Prior("Gamma", mu=2, sigma=1)
priors = {
"lam": hierarchical_lam,
"alpha": common_alpha,
}
saturation = mmm.MichaelisMentenSaturation(priors=priors)
saturation.function_priors
{'alpha': Prior("Gamma", mu=2, sigma=1),
'lam': Prior("HalfNormal", sigma=Prior("HalfNormal", sigma=1), dims="channel")}
Entonces, esto se puede utilizar en un nuevo modelo PyMC, lo que conduce a un gráfico de modelo muy diferente al anterior.
with pm.Model(coords=coords) as model:
saturated_spends = saturation.apply(
DataArray(
df_spends.values,
dims=(
"date",
"channel",
),
)
)
pm.model_to_graphviz(model)

La forma de la salida seguirá siendo (fecha, canal) aunque algunas de las dimensiones del parámetro hayan cambiado.
saturated_spends.type.shape
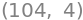
El flujo de trabajo anterior aún nos ayuda a comprender las curvas producidas:
muestra_anterior
sample_curvetrazar_curva
prior = saturation.sample_prior(coords=coords, random_seed=rng)
Sampling: [saturation_alpha, saturation_lam, saturation_lam_sigma]
Aunque todos parecen iguales en el anterior, el proceso de generación de datos es, de hecho, diferente como se observa en el gráfico del modelo.
curve = saturation.sample_curve(prior)
saturation.plot_curve(curve);
Sampling: []
Modelo Geo Jerárquico#
Las dimensiones de los parámetros no están limitadas a 1D, por lo que se pueden definir jerarquías adicionales.
A continuación se define:
alpha que es jerárquico a través de los canales
lam que es común en todas las geos pero en diferentes canales
# For reference
mmm.MichaelisMentenSaturation.default_priors
{'alpha': Prior("Gamma", mu=2, sigma=1), 'lam': Prior("HalfNormal", sigma=1)}
hierarchical_alpha = Prior(
"Gamma",
mu=Prior("HalfNormal", sigma=1, dims="geo"),
sigma=Prior("HalfNormal", sigma=1, dims="geo"),
dims=("channel", "geo"),
)
common_lam = Prior("HalfNormal", sigma=1, dims="channel")
priors = {
"alpha": hierarchical_alpha,
"lam": common_lam,
}
saturation = mmm.MichaelisMentenSaturation(priors=priors)
Nuestro nuevo conjunto de datos necesita tener información para geo ahora. Esto son los gastos del canal por fecha y geo. Esto se almacena en un xarray.DataArray que puede ser convertido a un numpy.ndarray 3D.
Mostrar los datos es fácil con pandas.
geo_coords = {
**coords,
"geo": ["Region1", "Region2", "Region3"],
}
geo_spends = random_spends(coords=geo_coords)
geo_spends.to_series().unstack("channel").head(6)
| channel | C1 | C2 | C3 | C4 | |
|---|---|---|---|---|---|
| date | geo | ||||
| 2023-01-02 | Region1 | 0.0 | 0.469285 | 1.800792 | 0.851362 |
| Region2 | 0.0 | 0.506669 | 0.000000 | 0.795277 | |
| Region3 | 0.0 | 1.504671 | 1.104576 | 0.000000 | |
| 2023-01-09 | Region1 | 0.0 | 1.996656 | 1.024629 | 0.000000 |
| Region2 | 0.0 | 0.000000 | 0.000000 | 0.574270 | |
| Region3 | 0.0 | 0.013698 | 1.131477 | 0.365130 |
Mientras el argumento dims de apply pueda transmitirse con los datos que se ingresan, ¡entonces se pueden utilizar las transformaciones de medios!
Aquí, los datos están en la forma (fecha, canal, geo) para que se puedan transmitir con los parámetros en la forma (canal, geo) para crear los gastos saturados.
with pm.Model(coords=geo_coords) as geo_model:
geo_data = pmd.Data(
"geo_data",
geo_spends.to_numpy(),
dims=("date", "channel", "geo"),
)
saturated_geo_spends = pmd.Deterministic(
"saturated_geo_spends",
saturation.apply(geo_data),
)
Las suposiciones de saturación se pueden ver en el gráfico del modelo:
pm.model_to_graphviz(geo_model)

Truco
El contexto del modelo PyMC permanecerá igual, pero los cambios en las suposiciones del modelo ocurrirán con los datos de entrada y la configuración previa.
Estacionalidad#
La estacionalidad recurrente se puede modelar con una instancia de MonthlyFourier o YearlyFourier.
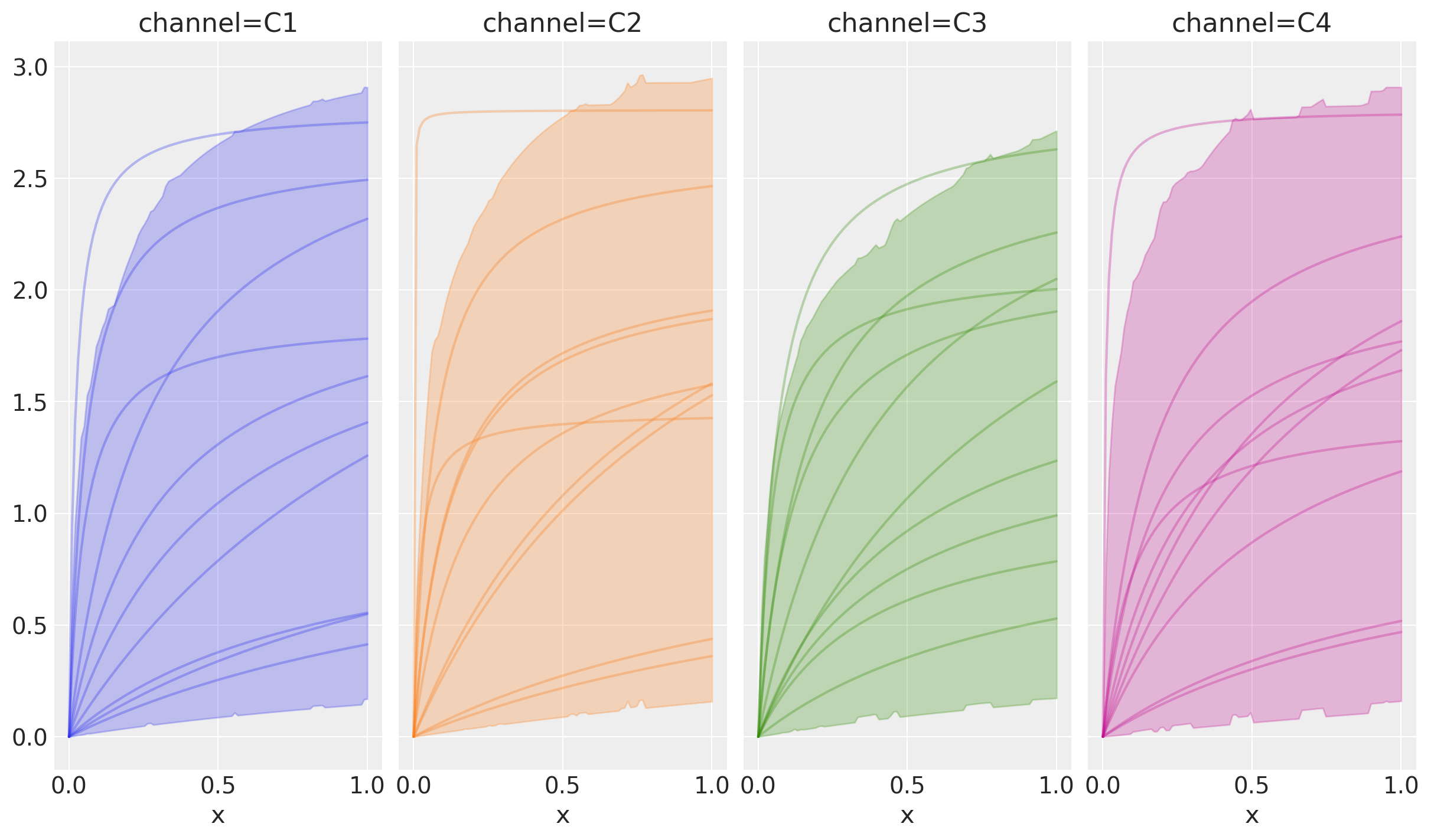
yearly = mmm.YearlyFourier(n_order=2)
Hay un flujo de trabajo similar para entender estos antecedentes como antes:
sample_prior: Muestre todos los priorssample_curve: Muestre la curva a lo largo de todo el períodoplot_curve: Graficar el IDH y algunas muestras
prior = yearly.sample_prior()
curve = yearly.sample_curve(prior)
yearly.plot_curve(curve);
Sampling: [fourier_beta]
Sampling: []
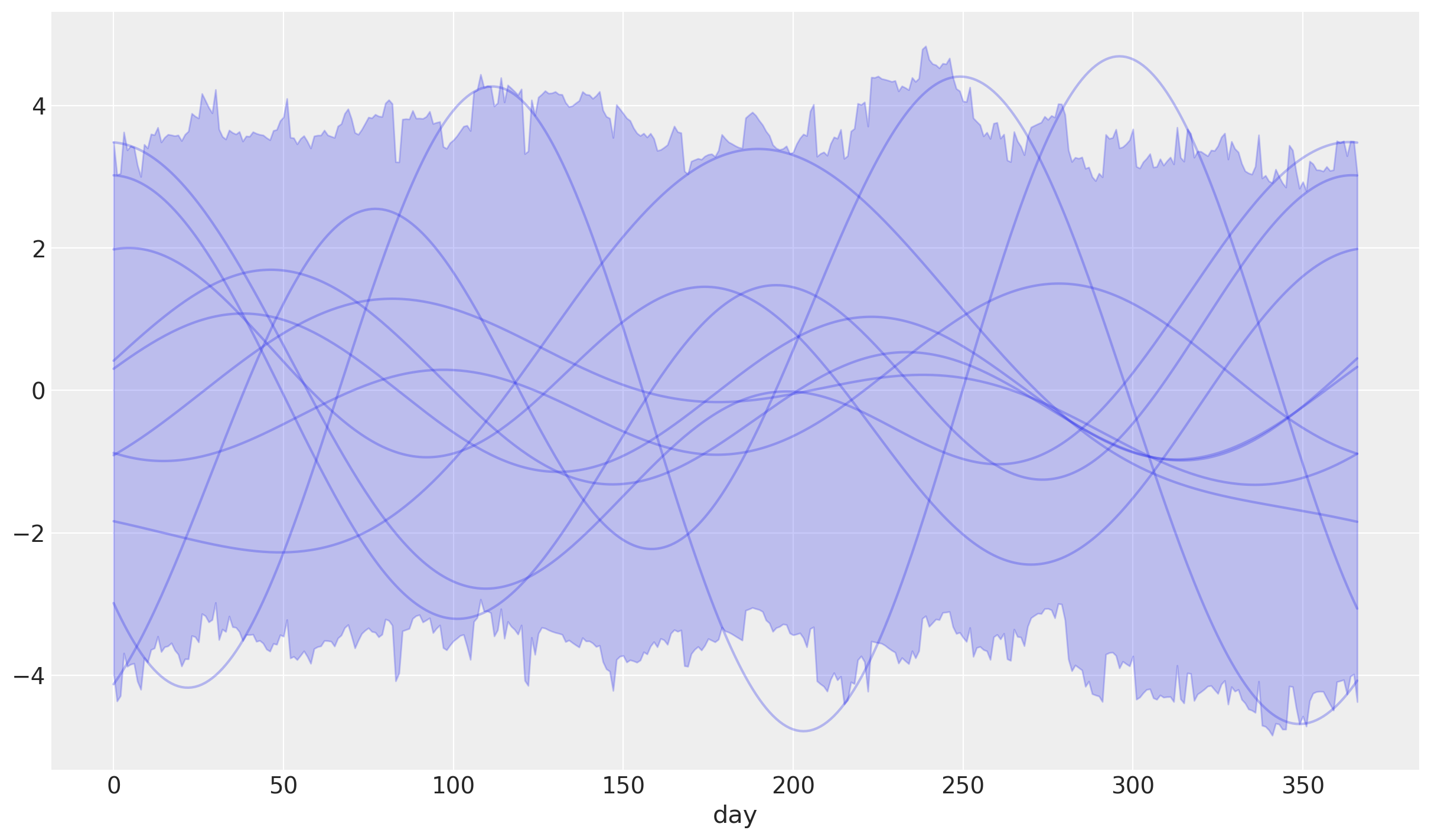
Esto también admite jerarquías arbitrarias que se pueden definir con la clase Prior. Pásalas con los parámetros prior.
Nota
¡Se requerirá una dimensión asociada con el prefijo! Por defecto es fourier
prior = Prior(
"Normal",
mu=DataArray([0, 0, -1, 0], dims="fourier"),
sigma=Prior("Gamma", mu=0.15, sigma=0.1, dims="fourier"),
dims=("geo", "fourier"),
)
yearly = mmm.YearlyFourier(n_order=2, prior=prior)
¡El flujo de trabajo anterior también funciona aquí! Las coordenadas solo necesitan ser pasadas como en pm.Model.
coords = {
"geo": ["A", "B"],
}
prior = yearly.sample_prior(coords=coords, xdist=True)
curve = yearly.sample_curve(prior)
Sampling: [fourier_beta, fourier_beta_sigma]
Sampling: []
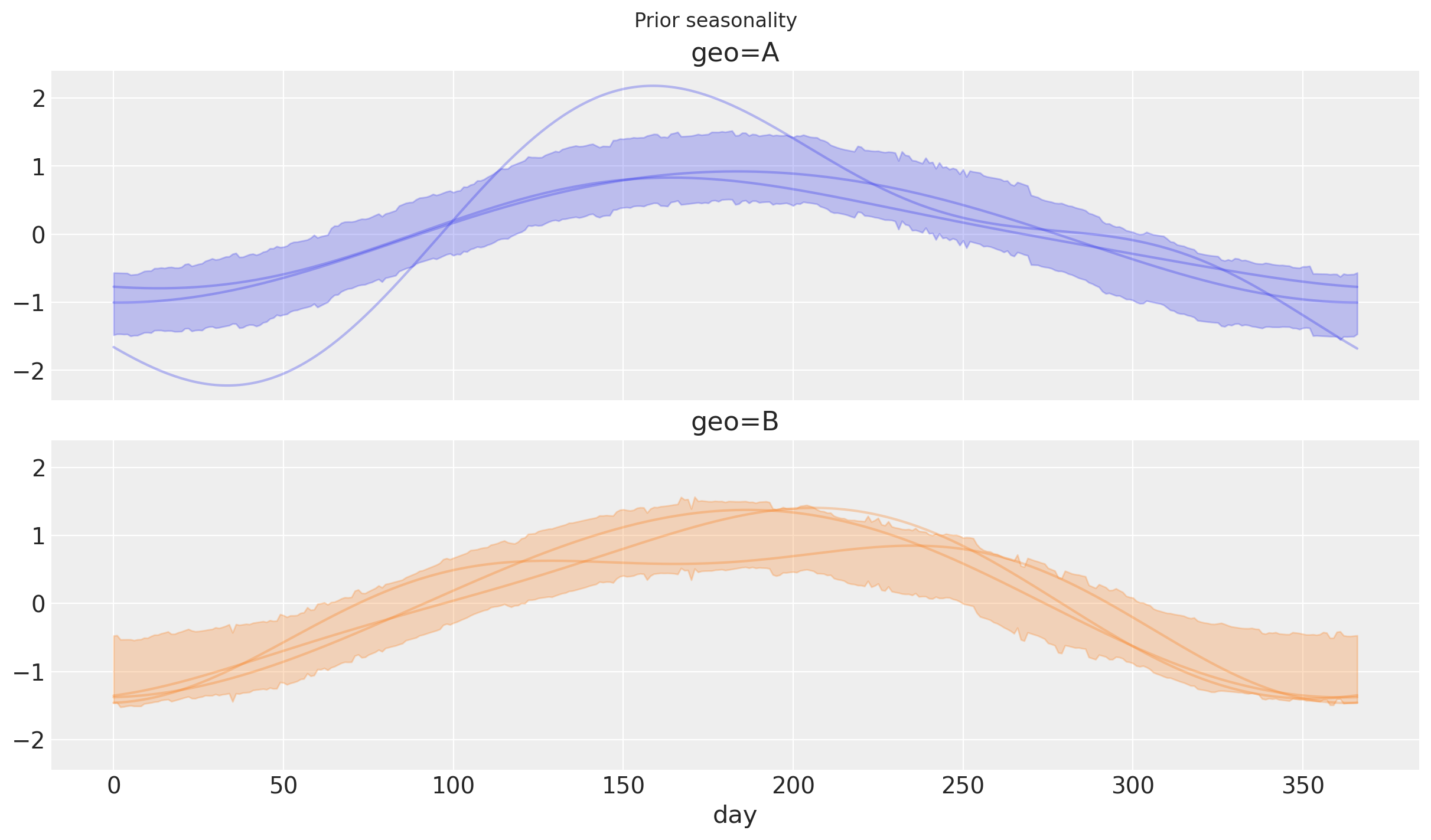
Basado en los priors jerárquicos, podemos observar una estacionalidad similar entre las geos. Sin embargo, ¡no son exactamente iguales!
subplot_kwargs = {"ncols": 1}
sample_kwargs = {"n": 3}
fig, _ = yearly.plot_curve(
curve, subplot_kwargs=subplot_kwargs, sample_kwargs=sample_kwargs
)
fig.suptitle("Prior seasonality");
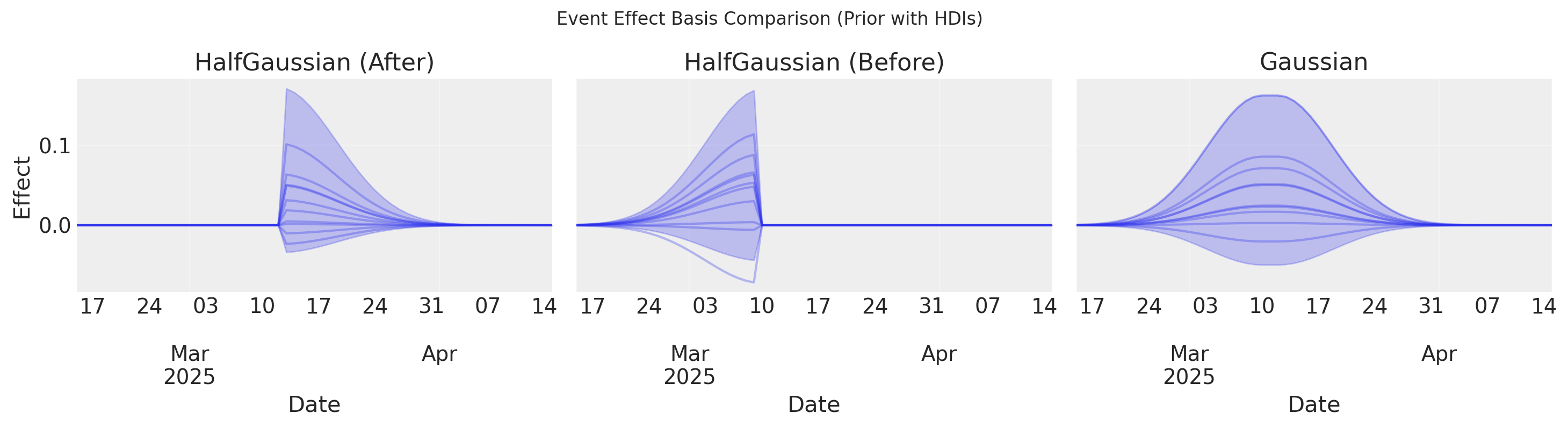
Eventos#
Puedes añadir eventos latentes utilizando la Base Gaussiana, esto modelará eventos como bultos gaussianos como lo describe Juan Orduz.
# Example event window
df_events = pd.DataFrame(
{
"event": ["Product Launch"],
"start_date": pd.to_datetime(["2025-03-10"]),
"end_date": pd.to_datetime(["2025-03-12"]),
}
)
# Build basis matrix of day offsets relative to event window
def difference_in_days(model_dates, event_dates):
if hasattr(model_dates, "to_numpy"):
model_dates = model_dates.to_numpy()
if hasattr(event_dates, "to_numpy"):
event_dates = event_dates.to_numpy()
return (model_dates[:, None] - event_dates) / np.timedelta64(1, "D")
def create_basis_matrix(df_events: pd.DataFrame, model_dates: np.ndarray):
start_dates = df_events["start_date"]
end_dates = df_events["end_date"]
s_ref = difference_in_days(model_dates, start_dates)
e_ref = difference_in_days(model_dates, end_dates)
return np.where(
(s_ref >= 0) & (e_ref <= 0),
0,
np.where(np.abs(s_ref) < np.abs(e_ref), s_ref, e_ref),
)
# Model dates and basis matrix
n_days = 60
dates = pd.date_range("2025-02-15", periods=n_days, freq="D")
X = X = DataArray(create_basis_matrix(df_events, dates), dims=("date", "event"))
# Create three different event effects
half_after = HalfGaussianBasis(
priors={
"sigma": Prior("Gamma", mu=7, sigma=1, dims="event"),
},
mode="after",
include_event=False,
)
half_before = HalfGaussianBasis(
priors={
"sigma": Prior("Gamma", mu=7, sigma=1, dims="event"),
},
mode="before",
include_event=False,
)
gaussian = GaussianBasis(
priors={
"sigma": Prior("Gamma", mu=7, sigma=1, dims="event"),
},
)
effect_size = Prior("Normal", mu=1, sigma=1, dims="event")
# Create effects for each basis
effect_after = EventEffect(basis=half_after, effect_size=effect_size, dims=("event",))
effect_before = EventEffect(basis=half_before, effect_size=effect_size, dims=("event",))
effect_gaussian = EventEffect(basis=gaussian, effect_size=effect_size, dims=("event",))
coords = {"date": dates, "event": df_events["event"].to_numpy()}
# Sample prior curves for all three effects
curves = {}
for name, effect in [
("HalfGaussian (After)", effect_after),
("HalfGaussian (Before)", effect_before),
("Gaussian", effect_gaussian),
]:
with pm.Model(coords=coords):
event_curve = pmd.Deterministic(
"effect", effect.apply(X), dims=("date", "event")
)
idata = pm.sample_prior_predictive()
curves[name] = idata.prior["effect"]
# Plot all three effects with HDIs and samples using plot_curve
fig, axes = plt.subplots(1, 3, figsize=(15, 4), sharey=True)
for i, (name, curve) in enumerate(curves.items()):
_fig, _axes = plot_curve(
curve,
"date",
n_samples=10,
axes=np.array([axes[i]]),
)
axes[i].set_title(name)
axes[i].set_xlabel("Date")
axes[i].grid(True, alpha=0.3)
axes[0].set_ylabel("Effect")
fig.suptitle("Event Effect Basis Comparison (Prior with HDIs)")
fig.tight_layout()
/home/ricardo/Documents/pymc-marketing/pymc_marketing/mmm/events.py:330: UserWarning: RandomVariables {gamma_rv{"(),()->()"}.out} were found in the derived graph. These variables are a clone and do not match the original ones on identity.
If you are deriving a quantity that depends on model RVs, use `model.replace_rvs_by_values` first. For example: `logp(model.replace_rvs_by_values([rv])[0], value)`
out = ptx.math.exp(logp(rv, x))
/home/ricardo/Documents/pymc/pymc/pytensorf.py:801: UserWarning: RNG Variable RNG(<Generator(PCG64) at 0x7FA4ECEF6EA0>) has multiple distinct clients [(gamma((core_dims=(((), ()), ()), extra_dims=('event',)))(RNG(<Generator(PCG64) at 0x7FA4ECEF6EA0>), TensorFromXTensor.0, XElemwise{scalar_op=Mul()}.0, XElemwise{scalar_op=Reciprocal()}.0), 0), (gamma_rv{"(),()->()"}(RNG(<Generator(PCG64) at 0x7FA4ECEF6EA0>), MakeVector{dtype='int64'}.0, [49.], [0.14285714]), 0)], likely due to an inconsistent random graph. No default update will be returned.
warnings.warn(
Sampling: [basis_sigma, event_effect_size]
/home/ricardo/Documents/pymc-marketing/pymc_marketing/mmm/events.py:330: UserWarning: RandomVariables {gamma_rv{"(),()->()"}.out} were found in the derived graph. These variables are a clone and do not match the original ones on identity.
If you are deriving a quantity that depends on model RVs, use `model.replace_rvs_by_values` first. For example: `logp(model.replace_rvs_by_values([rv])[0], value)`
out = ptx.math.exp(logp(rv, x))
/home/ricardo/Documents/pymc/pymc/pytensorf.py:801: UserWarning: RNG Variable RNG(<Generator(PCG64) at 0x7FA4EF0C8740>) has multiple distinct clients [(gamma((core_dims=(((), ()), ()), extra_dims=('event',)))(RNG(<Generator(PCG64) at 0x7FA4EF0C8740>), TensorFromXTensor.0, XElemwise{scalar_op=Mul()}.0, XElemwise{scalar_op=Reciprocal()}.0), 0), (gamma_rv{"(),()->()"}(RNG(<Generator(PCG64) at 0x7FA4EF0C8740>), MakeVector{dtype='int64'}.0, [49.], [0.14285714]), 0)], likely due to an inconsistent random graph. No default update will be returned.
warnings.warn(
Sampling: [basis_sigma, event_effect_size]
/home/ricardo/Documents/pymc-marketing/pymc_marketing/mmm/events.py:268: UserWarning: RandomVariables {gamma_rv{"(),()->()"}.out} were found in the derived graph. These variables are a clone and do not match the original ones on identity.
If you are deriving a quantity that depends on model RVs, use `model.replace_rvs_by_values` first. For example: `logp(model.replace_rvs_by_values([rv])[0], value)`
out = pmd.math.exp(logp(rv, x))
/home/ricardo/Documents/pymc/pymc/pytensorf.py:801: UserWarning: RNG Variable RNG(<Generator(PCG64) at 0x7FA4E372ECE0>) has multiple distinct clients [(gamma((core_dims=(((), ()), ()), extra_dims=('event',)))(RNG(<Generator(PCG64) at 0x7FA4E372ECE0>), TensorFromXTensor.0, XElemwise{scalar_op=Mul()}.0, XElemwise{scalar_op=Reciprocal()}.0), 0), (gamma_rv{"(),()->()"}(RNG(<Generator(PCG64) at 0x7FA4E372ECE0>), MakeVector{dtype='int64'}.0, [49.], [0.14285714]), 0)], likely due to an inconsistent random graph. No default update will be returned.
warnings.warn(
Sampling: [basis_sigma, event_effect_size]
/tmp/ipykernel_2955/1096890975.py:103: UserWarning: The figure layout has changed to tight
fig.tight_layout()
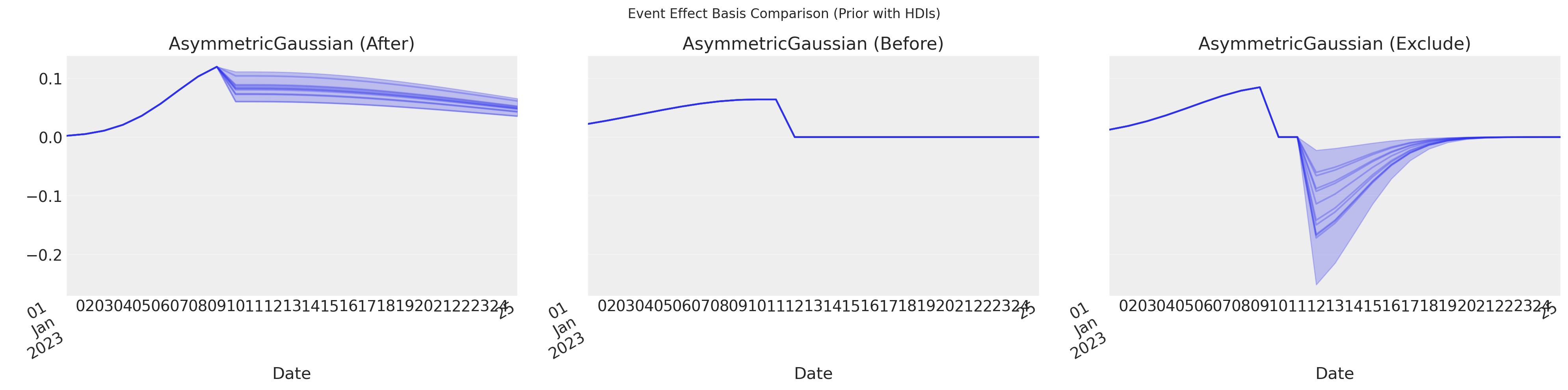
df_events = pd.DataFrame(
{
"event": ["e1"],
"start_date": pd.to_datetime(["2023-01-10"]),
"end_date": pd.to_datetime(["2023-01-11"]),
}
)
dates = pd.date_range("2023-01-01", periods=25, freq="D")
def create_basis_matrix(df_events: pd.DataFrame, model_dates: np.ndarray):
start_dates = df_events["start_date"]
end_dates = df_events["end_date"]
s_ref = difference_in_days(model_dates, start_dates)
e_ref = difference_in_days(model_dates, end_dates)
return np.where(
(s_ref >= 0) & (e_ref <= 0),
0,
np.where(np.abs(s_ref) < np.abs(e_ref), s_ref, e_ref),
)
X = DataArray(create_basis_matrix(df_events, dates), dims=("date", "event"))
asymmetric_after = AsymmetricGaussianBasis(
priors={
"sigma_before": Prior("Gamma", mu=3, sigma=1, dims="event"),
"sigma_after": Prior("Gamma", mu=7, sigma=2, dims="event"),
"a_after": Prior("Normal", mu=3, sigma=0.5, dims="event"),
},
event_in="after",
)
asymmetric_before = AsymmetricGaussianBasis(
priors={
"sigma_before": Prior("Gamma", mu=8, sigma=2, dims="event"),
"sigma_after": Prior("Gamma", mu=1, sigma=5, dims="event"),
"a_after": Prior("Normal", mu=1, sigma=0.5, dims="event"),
},
event_in="before",
)
asymmetric_exclude = AsymmetricGaussianBasis(
priors={
"sigma_before": Prior("Gamma", mu=2, sigma=2, dims="event"),
"sigma_after": Prior("Gamma", mu=3, sigma=1, dims="event"),
"a_after": Prior("Normal", mu=-1, sigma=0.5, dims="event"),
},
event_in="exclude",
)
effect_size = Prior("Normal", mu=1, sigma=1, dims="event")
effect_after = EventEffect(
basis=asymmetric_after, effect_size=effect_size, dims=("event",)
)
effect_before = EventEffect(
basis=asymmetric_before, effect_size=effect_size, dims=("event",)
)
effect_exclude = EventEffect(
basis=asymmetric_exclude, effect_size=effect_size, dims=("event",)
)
coords = {"date": dates, "event": df_events["event"].to_numpy()}
# Sample prior curves for all three effects
curves = {}
for name, effect in [
("AsymmetricGaussian (After)", asymmetric_after),
("AsymmetricGaussian (Before)", asymmetric_before),
("AsymmetricGaussian (Exclude)", asymmetric_exclude),
]:
with pm.Model(coords=coords):
event_curve = pmd.Deterministic("effect", effect.apply(X))
idata = pm.sample_prior_predictive()
curves[name] = idata.prior["effect"]
# Plot all three effects with HDIs and samples using plot_curve
fig, axes = plt.subplots(1, 3, figsize=(20, 5), sharey=True)
for i, (name, curve) in enumerate(curves.items()):
_fig, _axes = plot_curve(
curve,
"date",
n_samples=10,
axes=np.array([axes[i]]),
)
axes[i].set_title(name)
axes[i].set_xlabel("Date")
axes[i].grid(True, alpha=0.3)
# Rotate and align nicely
fig.autofmt_xdate(rotation=30)
fig.suptitle("Event Effect Basis Comparison (Prior with HDIs)")
fig.tight_layout()
/home/ricardo/Documents/pymc-marketing/pymc_marketing/mmm/events.py:432: UserWarning: RandomVariables {gamma_rv{"(),()->()"}.out} were found in the derived graph. These variables are a clone and do not match the original ones on identity.
If you are deriving a quantity that depends on model RVs, use `model.replace_rvs_by_values` first. For example: `logp(model.replace_rvs_by_values([rv])[0], value)`
ptx.math.exp(logp(rv_before, x)),
/home/ricardo/Documents/pymc-marketing/pymc_marketing/mmm/events.py:437: UserWarning: RandomVariables {gamma_rv{"(),()->()"}.out} were found in the derived graph. These variables are a clone and do not match the original ones on identity.
If you are deriving a quantity that depends on model RVs, use `model.replace_rvs_by_values` first. For example: `logp(model.replace_rvs_by_values([rv])[0], value)`
ptx.math.exp(logp(rv_after, x)) * a_after,
/home/ricardo/Documents/pymc/pymc/pytensorf.py:801: UserWarning: RNG Variable RNG(<Generator(PCG64) at 0x7FA4EC174F20>) has multiple distinct clients [(gamma((core_dims=(((), ()), ()), extra_dims=('event',)))(RNG(<Generator(PCG64) at 0x7FA4EC174F20>), TensorFromXTensor.0, XElemwise{scalar_op=Mul()}.0, XElemwise{scalar_op=Reciprocal()}.0), 0), (gamma_rv{"(),()->()"}(RNG(<Generator(PCG64) at 0x7FA4EC174F20>), MakeVector{dtype='int64'}.0, [12.25], [0.57142857]), 0)], likely due to an inconsistent random graph. No default update will be returned.
warnings.warn(
/home/ricardo/Documents/pymc/pymc/pytensorf.py:801: UserWarning: RNG Variable RNG(<Generator(PCG64) at 0x7FA4EC1749E0>) has multiple distinct clients [(gamma((core_dims=(((), ()), ()), extra_dims=('event',)))(RNG(<Generator(PCG64) at 0x7FA4EC1749E0>), TensorFromXTensor.0, XElemwise{scalar_op=Mul()}.0, XElemwise{scalar_op=Reciprocal()}.0), 0), (gamma_rv{"(),()->()"}(RNG(<Generator(PCG64) at 0x7FA4EC1749E0>), MakeVector{dtype='int64'}.0, [9.], [0.33333333]), 0)], likely due to an inconsistent random graph. No default update will be returned.
warnings.warn(
Sampling: [basis_a_after, basis_sigma_after, basis_sigma_before]
/home/ricardo/Documents/pymc-marketing/pymc_marketing/mmm/events.py:432: UserWarning: RandomVariables {gamma_rv{"(),()->()"}.out} were found in the derived graph. These variables are a clone and do not match the original ones on identity.
If you are deriving a quantity that depends on model RVs, use `model.replace_rvs_by_values` first. For example: `logp(model.replace_rvs_by_values([rv])[0], value)`
ptx.math.exp(logp(rv_before, x)),
/home/ricardo/Documents/pymc-marketing/pymc_marketing/mmm/events.py:437: UserWarning: RandomVariables {gamma_rv{"(),()->()"}.out} were found in the derived graph. These variables are a clone and do not match the original ones on identity.
If you are deriving a quantity that depends on model RVs, use `model.replace_rvs_by_values` first. For example: `logp(model.replace_rvs_by_values([rv])[0], value)`
ptx.math.exp(logp(rv_after, x)) * a_after,
/home/ricardo/Documents/pymc/pymc/pytensorf.py:801: UserWarning: RNG Variable RNG(<Generator(PCG64) at 0x7FA4EC44DD20>) has multiple distinct clients [(gamma((core_dims=(((), ()), ()), extra_dims=('event',)))(RNG(<Generator(PCG64) at 0x7FA4EC44DD20>), TensorFromXTensor.0, XElemwise{scalar_op=Mul()}.0, XElemwise{scalar_op=Reciprocal()}.0), 0), (gamma_rv{"(),()->()"}(RNG(<Generator(PCG64) at 0x7FA4EC44DD20>), MakeVector{dtype='int64'}.0, [0.04], [25.]), 0)], likely due to an inconsistent random graph. No default update will be returned.
warnings.warn(
/home/ricardo/Documents/pymc/pymc/pytensorf.py:801: UserWarning: RNG Variable RNG(<Generator(PCG64) at 0x7FA5162019A0>) has multiple distinct clients [(gamma((core_dims=(((), ()), ()), extra_dims=('event',)))(RNG(<Generator(PCG64) at 0x7FA5162019A0>), TensorFromXTensor.0, XElemwise{scalar_op=Mul()}.0, XElemwise{scalar_op=Reciprocal()}.0), 0), (gamma_rv{"(),()->()"}(RNG(<Generator(PCG64) at 0x7FA5162019A0>), MakeVector{dtype='int64'}.0, [16.], [0.5]), 0)], likely due to an inconsistent random graph. No default update will be returned.
warnings.warn(
Sampling: [basis_a_after, basis_sigma_after, basis_sigma_before]
/home/ricardo/Documents/pymc-marketing/pymc_marketing/mmm/events.py:432: UserWarning: RandomVariables {gamma_rv{"(),()->()"}.out} were found in the derived graph. These variables are a clone and do not match the original ones on identity.
If you are deriving a quantity that depends on model RVs, use `model.replace_rvs_by_values` first. For example: `logp(model.replace_rvs_by_values([rv])[0], value)`
ptx.math.exp(logp(rv_before, x)),
/home/ricardo/Documents/pymc-marketing/pymc_marketing/mmm/events.py:437: UserWarning: RandomVariables {gamma_rv{"(),()->()"}.out} were found in the derived graph. These variables are a clone and do not match the original ones on identity.
If you are deriving a quantity that depends on model RVs, use `model.replace_rvs_by_values` first. For example: `logp(model.replace_rvs_by_values([rv])[0], value)`
ptx.math.exp(logp(rv_after, x)) * a_after,
/home/ricardo/Documents/pymc/pymc/pytensorf.py:801: UserWarning: RNG Variable RNG(<Generator(PCG64) at 0x7FA4EC44E5E0>) has multiple distinct clients [(gamma((core_dims=(((), ()), ()), extra_dims=('event',)))(RNG(<Generator(PCG64) at 0x7FA4EC44E5E0>), TensorFromXTensor.0, XElemwise{scalar_op=Mul()}.0, XElemwise{scalar_op=Reciprocal()}.0), 0), (gamma_rv{"(),()->()"}(RNG(<Generator(PCG64) at 0x7FA4EC44E5E0>), MakeVector{dtype='int64'}.0, [9.], [0.33333333]), 0)], likely due to an inconsistent random graph. No default update will be returned.
warnings.warn(
/home/ricardo/Documents/pymc/pymc/pytensorf.py:801: UserWarning: RNG Variable RNG(<Generator(PCG64) at 0x7FA4EC3720A0>) has multiple distinct clients [(gamma((core_dims=(((), ()), ()), extra_dims=('event',)))(RNG(<Generator(PCG64) at 0x7FA4EC3720A0>), TensorFromXTensor.0, XElemwise{scalar_op=Mul()}.0, XElemwise{scalar_op=Reciprocal()}.0), 0), (gamma_rv{"(),()->()"}(RNG(<Generator(PCG64) at 0x7FA4EC3720A0>), MakeVector{dtype='int64'}.0, [1.], [2.]), 0)], likely due to an inconsistent random graph. No default update will be returned.
warnings.warn(
Sampling: [basis_a_after, basis_sigma_after, basis_sigma_before]
/tmp/ipykernel_2955/1519355296.py:98: UserWarning: The figure layout has changed to tight
fig.tight_layout()
Ejemplo de MMM personalizado#
Mucha flexibilidad al combinarlos. Esto se basará en el ejemplo anterior e incluirá también una transformación de adstock de los datos.
def create_media_transformation(adstock, saturation, adstock_first: bool = True):
"""Flexible media transformation which allows for order to transformations."""
first, second = (adstock, saturation) if adstock_first else (saturation, adstock)
def media_transformation(x, dim: str):
return second.apply(first.apply(x, core_dim=dim), core_dim=dim)
return media_transformation
Nuestra función de adstock tendrá un parámetro jerárquico para cada geo. Nuestra configuración es lo suficientemente flexible como para cambiar esto siempre que las dimensiones finales se transmitan con los datos.
# For reference
mmm.GeometricAdstock.default_priors
{'alpha': Prior("Beta", alpha=1, beta=3)}
Estos también son parámetros jerárquicos, pero en dimensiones diferentes a la transformación de saturación.
hierarchical_alpha = Prior(
"Beta",
alpha=Prior("HalfNormal", sigma=1, dims="channel"),
beta=Prior("HalfNormal", sigma=1, dims="channel"),
dims=("channel", "geo"),
)
priors = {
"alpha": hierarchical_alpha,
}
adstock = mmm.GeometricAdstock(l_max=10, priors=priors)
Luego, para algunas diferencias adicionales entre geo y observaciones, asumiremos una intersección y ruido alrededor de las observaciones. La intersección será independiente entre geos y se asumirá que el ruido es jerárquico entre geos.
La clase Prior se utilizará para reflejar estas suposiciones fuera del contexto del modelo.
intercept_dist = Prior("Normal", mu=2.5, sigma=0.25, dims="geo")
sigma_dist = Prior(
"Normal",
mu=-1,
sigma=Prior("Gamma", mu=0.25, sigma=0.05),
dims="geo",
transform="exp",
)
media_transformation = create_media_transformation(
adstock, saturation, adstock_first=True
)
with pm.Model(coords=geo_coords) as geo_model:
intercept = intercept_dist.create_variable("intercept", xdist=True)
# Media
geo_data = pmd.Data(
"geo_data",
geo_spends.to_numpy(),
dims=("date", "channel", "geo"),
)
channel_contributions = pmd.Deterministic(
"channel_contributions",
media_transformation(geo_data, dim="date"),
)
media_contributions = pmd.Deterministic(
"media_contributions",
channel_contributions.sum(dim="channel"),
)
# Seasonality
dayofyear = pmd.Data(
"dayofyear",
geo_spends.coords["date"].dt.dayofyear.to_numpy(),
dims="date",
)
fourier_trend = pmd.Deterministic(
"fourier_trend",
yearly.apply(dayofyear),
)
# Combined
mu = pmd.Deterministic(
"mu",
intercept + media_contributions + fourier_trend,
)
sigma = sigma_dist.create_variable("target_sigma", xdist=True)
target = pmd.Normal(
"target",
mu=mu,
sigma=sigma,
# observed=...,
)
El proceso de generación de datos combinados se puede ver a continuación:
pm.model_to_graphviz(geo_model)

Podemos entonces muestrear de este modelo para investigar la variable objetivo del MMM.
with geo_model:
prior = pm.sample_prior_predictive(random_seed=rng).prior
prior
Sampling: [adstock_alpha, adstock_alpha_alpha, adstock_alpha_beta, fourier_beta, fourier_beta_sigma, intercept, saturation_alpha, saturation_alpha_mu, saturation_alpha_sigma, saturation_lam, target, target_sigma_raw, target_sigma_raw_sigma]
<xarray.Dataset> Size: 10MB
Dimensions: (chain: 1, draw: 500, channel: 4, geo: 3,
fourier: 4, date: 104)
Coordinates:
* chain (chain) int64 8B 0
* draw (draw) int64 4kB 0 1 2 3 4 5 ... 495 496 497 498 499
* channel (channel) <U2 32B 'C1' 'C2' 'C3' 'C4'
* geo (geo) <U7 84B 'Region1' 'Region2' 'Region3'
* fourier (fourier) <U5 80B 'sin_1' 'sin_2' 'cos_1' 'cos_2'
* date (date) datetime64[ns] 832B 2023-01-02 ... 2024-12-23
Data variables: (12/18)
adstock_alpha_alpha (chain, draw, channel) float64 16kB 1.098 ... 1.247
saturation_lam (chain, draw, channel) float64 16kB 0.01971 ... 1...
fourier_beta (chain, draw, geo, fourier) float64 48kB 0.0356 ....
target_sigma_raw_sigma (chain, draw) float64 4kB 0.332 0.2756 ... 0.1946
saturation_alpha (chain, draw, channel, geo) float64 48kB 0.8443 ....
media_contributions (chain, draw, geo, date) float64 1MB 1.048 ... 0....
... ...
saturation_alpha_mu (chain, draw, geo) float64 12kB 0.5439 ... 0.7651
target_sigma (chain, draw, geo) float64 12kB 0.2758 ... 0.327
adstock_alpha_beta (chain, draw, channel) float64 16kB 0.7069 ... 1.123
target_sigma_raw (chain, draw, geo) float64 12kB -1.288 ... -1.118
fourier_beta_sigma (chain, draw, fourier) float64 16kB 0.2988 ... 0....
fourier_trend (chain, draw, date, geo) float64 1MB -1.099 ... -...
Attributes:
created_at: 2026-02-26T17:14:02.826846+00:00
arviz_version: 0.23.1
inference_library: pymc
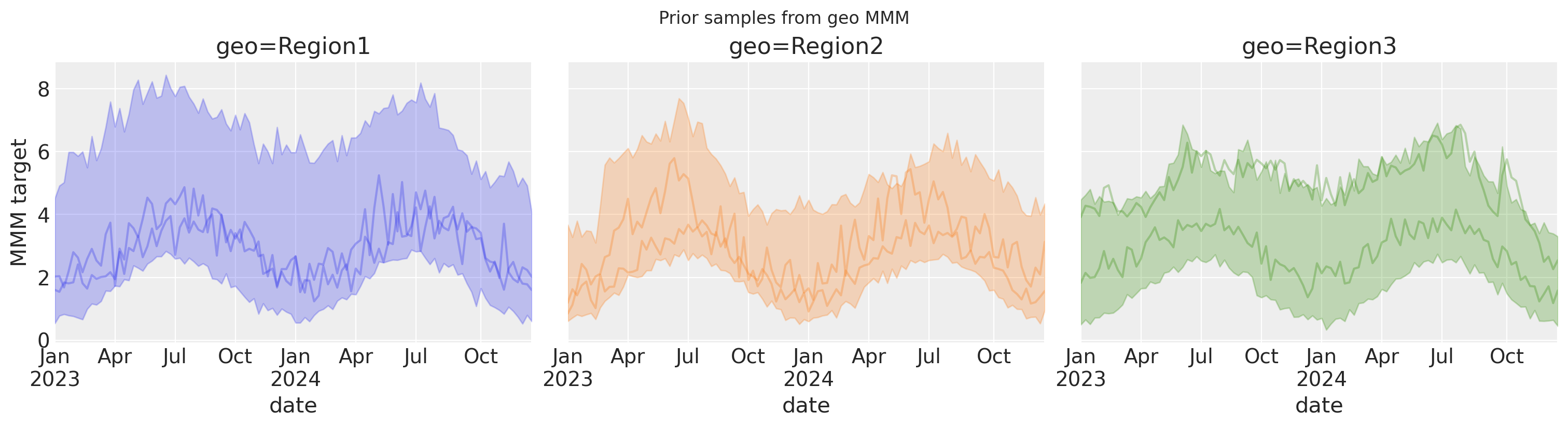
inference_library_version: 5.28.0Usaremos la función auxiliar plot_curve para graficar la variable target a lo largo del tiempo para cada región. Esto muestra el IDH y 2 muestras anteriores para cada una de las 3 series temporales.
fig, axes = plot_curve(
prior["target"],
{"date"},
sample_kwargs={
"rng": rng,
"n": 2,
},
subplot_kwargs={"ncols": 3, "figsize": (15, 4)},
)
axes[0].set(ylabel="MMM target")
fig.suptitle("Prior samples from geo MMM");
Resumen#
Los modelos personalizados son posibles utilizando los componentes que conforman la clase MMM y las distribuciones de PyMC en sí. Con una configuración previa de la distribución y los componentes que proporciona PyMC-Marketing, se pueden construir modelos novedosos para ajustarse a diversos casos de uso y diversas suposiciones del modelo.
Gran parte de la flexibilidad provendrá de la configuración de distribución previa en lugar de las transformaciones en sí. Esto está destinado a mantener una interfaz estándar al trabajar con ellos, independientemente de cuál sea su función.
Si tiene alguna sugerencia o comentario sobre cómo mejorar los modelos personalizados con el paquete, cree un problema en GitHub o participe en las diversas discusiones.
Aunque los modelos se pueden construir de esta manera, las estructuras preconstruidas también ofrecen muchos beneficios. Por ejemplo, la clase MMM proporciona:
escalado de datos de entrada y salida
métodos de representación para parámetros, datos predictivos, contribuciones, etc.
transformaciones de adstock y saturación personalizadas
predicciones fuera de muestra
integración de prueba de elevación
optimización del presupuesto
Nuestra recomendación es comenzar con los modelos preconstruidos y avanzar a partir de ahí.
%load_ext watermark
%watermark -n -u -v -iv -w -p pymc_marketing,pytensor
Last updated: Thu, 26 Feb 2026
Python implementation: CPython
Python version : 3.13.11
IPython version : 9.9.0
pymc_marketing: 0.18.2
pytensor : 2.38.0+3.g9b81d36bb
arviz : 0.23.1
matplotlib : 3.10.8
numpy : 2.3.5
pandas : 2.3.3
pymc : 5.28.0
pymc_extras : 0.9.2.dev0+gb4ee3c133.d20260226
pymc_marketing: 0.18.2
xarray : 2025.12.0
Watermark: 2.6.0