MMMs y la escalera de inferencia causal de Pearl#
En este cuaderno, exploraremos la escalera causal de Judea Pearl y cómo se puede aplicar para resolver problemas empresariales con Modelos de Mezcla de Medios (MMM). Supondremos familiaridad con los conceptos básicos de los MMM para centrarnos en la inferencia causal.
¿Cuál es la escalera causal de Pearl?#
La escalera causal de Pearl describe 3 niveles de razonamiento causal sucesivamente más sofisticados:
Predicción / Pronóstico / Asociación: Con el primer paso en la escalera, podríamos utilizar un modelo para predecir las ventas futuras basándonos en datos pasados. Esto no implica razonamiento causal, solo predicción.
Intervención: El segundo paso en la escalera implica utilizar un modelo para predecir el efecto futuro de una intervención. Es similar al paso 1 en que involucra predicción/forecasting, pero es diferente en que consideramos una intervención potencial que tendrá efectos en el futuro.
Contrafactuales: El tercer y último paso en la escalera podría utilizar un {like_this} para estimar cómo habría sido diferente el mundo si hubiéramos tomado una acción diferente en el pasado. Esto es claramente diferente de los dos primeros pasos en que es retrospectivo. También es el nivel más sofisticado de razonamiento causal: implica aprender sobre el mundo a partir de datos históricos, pero luego imaginar cómo podría haber sido diferente el mundo en un escenario contrafactual.
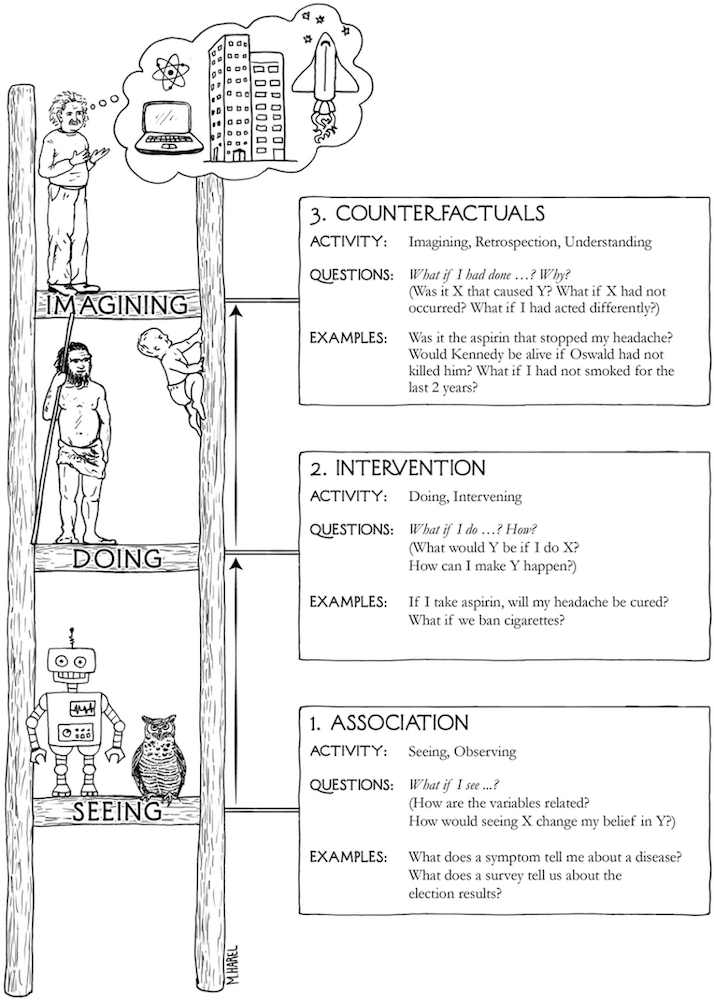
La imagen de la escalera causal de Pearl aparece en el libro «The Book of Why» de Judea Pearl y Dana Mackenzie. El libro es una excelente introducción a la inferencia causal.
El operador do#
El operador do es un concepto clave en el marco de inferencia causal de Pearl y es necesario para el razonamiento causal en los pasos 2 o 3 de la escalera causal. Se utiliza para denotar intervenciones en un sistema. Si pensamos en nuestros esfuerzos de modelado como la descripción de un modelo causal estructural bayesiano, entonces el operador do se utiliza para denotar el efecto de cambiar una variable en el modelo. Cualquier enlace causal entrante a ese nodo se corta, y el nodo se establece en el valor especificado por el operador do.
Ver también
Para ejemplos prácticos del operador do en acción, los siguientes recursos son útiles:
Análisis causal con PyMC: Respondiendo a «¿Qué pasaría si?» con el nuevo operador do
Distribuciones interventionales y mutación de gráficos con el operador do.
¿Cómo nos ayuda esto a resolver problemas de negocio?#
Ahora que hemos resumido la escalera causal, consideremos cómo puede ayudarnos a resolver problemas empresariales, específicamente con los MMM. Veamos algunos casos de uso de ejemplo y veamos a qué nivel de la escalera causal corresponden:
Predicción de ventas futuras: Un caso de uso muy común de los MMM es hacer pronósticos de nuestra variable de resultado (por ejemplo, ventas). Esto puede ser un ingrediente particularmente útil en la previsión de la demanda, por ejemplo. Una vez que hemos entrenado un MMM con datos históricos, podemos utilizar el MMM para predecir ventas futuras (predicción fuera de muestra) basándonos en ventas pasadas, gasto en marketing y otras variables predictoras. Esto correspondería al paso 1 en la escalera causal: estamos pronosticando hacia el futuro pero no considerando ningún cambio en nuestra estrategia de marketing. Consulte nuestra documentación Asignación de Presupuesto con PyMC-Marketing para un ejemplo trabajado.
Optimización del gasto en marketing existente: Un caso de uso más sofisticado de los MMM es utilizar el modelo para predecir el efecto de diferentes estrategias de marketing (consulte nuestra documentación Validación cruzada por segmentos de tiempo y estabilidad de parámetros). Por ejemplo, podríamos usarlo para predecir el efecto de varios cambios en el gasto en medios. Luego podríamos predecir las ventas esperadas bajo estos escenarios y elegir un escenario que maximice las ventas o el beneficio, por ejemplo. Esto corresponde al paso 2 en la escalera causal - intervención. Este es un nivel más sofisticado de razonamiento causal, ya que implica predicción, pero en presencia de estrategias de marketing alteradas (es decir, intervenciones).
Planificación de un aumento en el gasto en marketing: Supongamos que nuestro negocio desea ganar más cuota de mercado y ha decidido aumentar el gasto en marketing en un 20% durante el próximo trimestre. Se le ha encomendado la tarea de proponer una serie de diferentes estrategias de gasto en medios futuros que usted cree que causarán el mayor aumento en las ventas. Esto corresponde al paso 2 en la escalera causal - intervención. Estamos prediciendo el efecto de una intervención (aumento del gasto en medios) en las ventas.
Evaluando el impacto de un aumento previo en el gasto de marketing: Supongamos que nuestro negocio aumentó el gasto en televisión en un 20% durante el último trimestre y queremos saber qué impacto tuvo esto en las ventas. Podemos responder a esta pregunta comparando lo que realmente sucedió con lo que creemos que habría sucedido en algún escenario contrafactual alternativo imaginado, como no haber aumentado el gasto en televisión en un 20%. Es importante destacar que este razonamiento contrafactual es retrospectivo, pero utiliza el conocimiento que hemos aprendido de todas las observaciones hasta ahora. Esto corresponde al paso 3 en la escalera causal - inferencia contrafactual. Estamos aprendiendo de datos históricos, pero luego imaginamos cómo el mundo podría haber sido diferente en un escenario contrafactual. Así que esto implica un razonamiento causal retrospectivo.
Configuración del cuaderno#
import arviz as az
import graphviz as gr
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import xarray as xr
from IPython.display import Image
from pymc_marketing.mmm import MMM, GeometricAdstock, LogisticSaturation
from pymc_marketing.mmm.transformers import geometric_adstock, logistic_saturation
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "retina"
plt.rcParams.update({"figure.constrained_layout.use": True})
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
seed: int = sum(map(ord, "ladder"))
rng: np.random.Generator = np.random.default_rng(seed=seed)
Generar datos sintéticos#
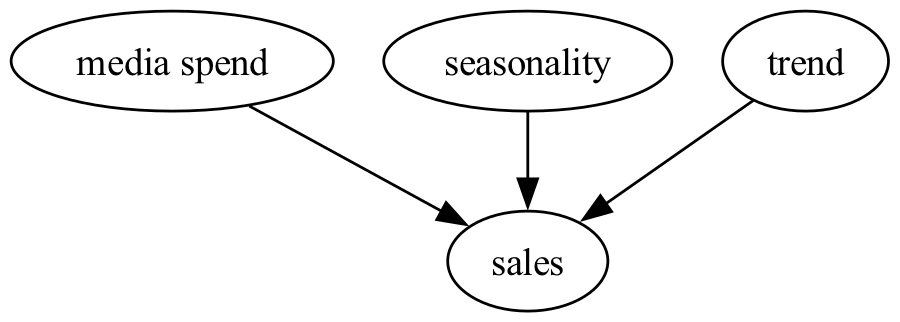
Ahora generaremos algunos datos sintéticos para utilizar en el resto del cuaderno. En resumen, consideraremos una situación relativamente simple en la que tenemos dos canales de medios (\(x_1\) y \(x_2\)), y consideramos los efectos del tiempo en términos de una tendencia subyacente en las ventas, así como efectos estacionales. Podemos representar nuestro DAG causal de la siguiente manera:
En el código a continuación, generaremos algunos datos sintéticos con la estructura general descrita anteriormente. Nuestro conjunto de datos incluirá una campaña de marketing en la que aumentamos el gasto en un canal de medios durante un período de tiempo. Esto se utilizará más adelante cuando lleguemos a examinar el Paso 3, donde evaluaremos el impacto de esta campaña.
Como una ligera variación, dado que estamos utilizando datos simulados, nos encontramos en la posición privilegiada de conocer las verdaderas relaciones causales en los datos. Este no es el caso en el mundo real, donde debemos inferir estas relaciones a partir de los datos. Por lo tanto, primero generaremos un escenario contrafactual (donde no ejecutamos la campaña) y luego generaremos el escenario real (donde sí ejecutamos la campaña). Esto nos permite comparar nuestro impacto causal estimado de la campaña con el impacto causal verdadero de la campaña. Pero hablaremos más sobre esto cuando lleguemos al Paso 3 de la escalera causal.
Generemos algunos datos sintéticos, más específicamente algunos predictores como el gasto en medios, la intersección, la estacionalidad y la tendencia.
def generate_counterfactual_dataset(params, rng):
"""Generate a synthetic dataset.
For the counterfactual scenario of no advertising campaign.
"""
df = pd.DataFrame(
data={
"date_week": pd.date_range(
start=pd.to_datetime("2019-04-01"),
end=pd.to_datetime("2021-09-01"),
freq="W-MON",
)
}
).assign(
year=lambda x: x["date_week"].dt.year,
month=lambda x: x["date_week"].dt.month,
dayofyear=lambda x: x["date_week"].dt.dayofyear,
t=lambda x: range(x.shape[0]),
)
n_rows = df.shape[0]
# media data
x1 = rng.uniform(low=0.0, high=1.0, size=n_rows)
df["x1"] = np.where(x1 > 0.9, x1, x1 / 2)
x2 = rng.uniform(low=0.0, high=1.0, size=n_rows)
df["x2"] = np.where(x2 > 0.8, x2, 0)
# Intercept, trend, seasonality components
df["intercept"] = 2.0
df["trend"] = (np.linspace(start=0.0, stop=50, num=n_rows) + 10) ** (1 / 4) - 1
df["cs"] = -np.sin(2 * 2 * np.pi * df["dayofyear"] / 365.5)
df["cc"] = np.cos(1 * 2 * np.pi * df["dayofyear"] / 365.5)
df["seasonality"] = 0.5 * (df["cs"] + df["cc"])
# Noise - can be considered as the effects of unobserved variables upon sales
df["epsilon"] = rng.normal(loc=0.0, scale=0.25, size=n_rows)
df = forward_pass(df, params)
return df
Ahora escribiremos una función para simular hacia adelante la respuesta (ventas), dado estas variables predictoras. Las funciones a continuación simplemente calculan una suma ponderada de las variables predictoras, después de haber pasado los canales de medios a través de nuestras confiables funciones de adstock y saturación.
def apply_transformations(df, channel, alpha, lam):
"""Apply geometric adstock and saturation transformations."""
adstocked = geometric_adstock(
x=df[channel].to_xarray(),
alpha=alpha,
l_max=8,
normalize=True,
dim="index",
)
saturated = logistic_saturation(x=adstocked, lam=lam).eval()
return saturated
def forward_pass(df_in, params):
"""Run predictor variables through the forward pass of the model.
Given a dataframe with spend data columns `x1` and `x2`, run this through the
transformations and return the response variable `y`.
"""
df = df_in.copy()
# Apply transformations to channels and calculate y
df["y"] = params["amplitude"] * (
df["intercept"]
+ df["trend"]
+ df["seasonality"]
+ sum(
params["beta"][i]
* apply_transformations(
df, params["channels"][i], params["alpha"][i], params["lam"][i]
)
for i in range(len(params["channels"]))
)
+ df["epsilon"]
)
return df
Ahora utilicemos esas funciones para generar datos sintéticos que representen lo que ocurre en nuestro mundo simulado bajo un escenario de “negocios como siempre” (o contrafactual) de ausencia de campaña mediática.
params = {
"channels": ["x1", "x2"],
"amplitude": 1.0,
"beta": [3.0, 2.0],
"lam": [4.0, 3.0],
"alpha": [0.4, 0.2],
}
df_counterfactual = generate_counterfactual_dataset(params, rng)
Finalmente, creemos una copia de estos datos, pero una en la que realizamos una intervención. Es decir, una campaña de marketing en la que aumentamos el gasto en medios en el canal 1 en un 40% para el primer trimestre de 2021. Estos datos df_actual representarán lo que realmente sucedió en nuestro mundo. Los datos df_counterfactual representarán lo que habría sucedido si no hubiéramos realizado la intervención, y esto se utilizará cuando lleguemos al Paso 3 de la escalera causal.
def simulate_intervention(df: pd.DataFrame, intervention_dates) -> pd.DataFrame:
"""Simulate an intervention.
This function will generate the 'actual' dataset. Based on the counterfactual
dataset, apply the intervention on the specified date and return the actual dataset.
"""
df = df.copy()
# increase x1 by 40% in for date_week between intervention_dates
df.loc[
(df["date_week"] >= intervention_dates[0])
& (df["date_week"] < intervention_dates[1]),
"x1",
] *= 1.40
# compute the outcome variable
df = forward_pass(df, params)
return df
intervention_dates = (pd.to_datetime("2021-01-01"), pd.to_datetime("2021-03-31"))
df_actual = simulate_intervention(df_counterfactual, intervention_dates)
Vamos a visualizar el conjunto de datos:
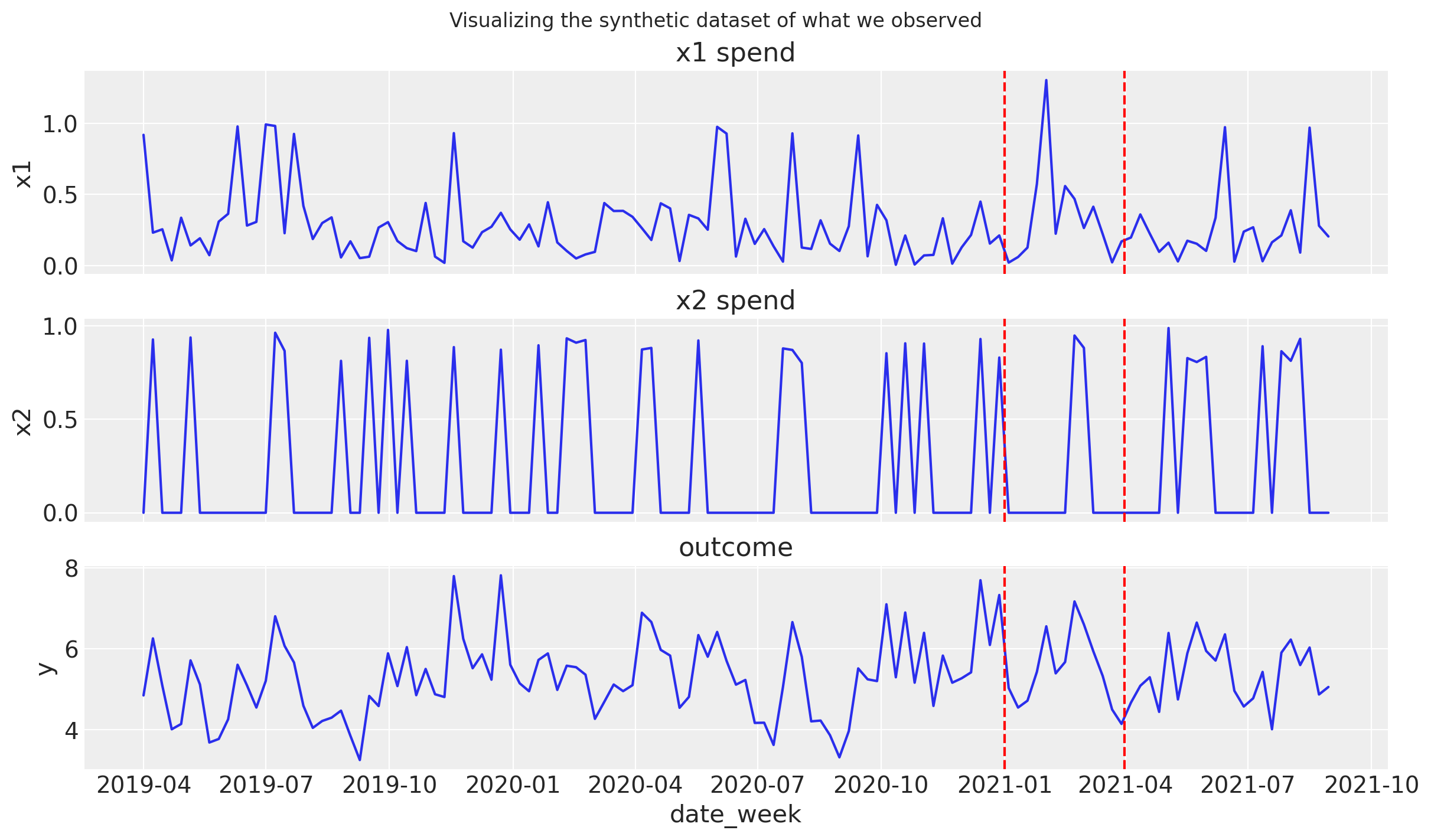
Este gráfico muestra nuestros gastos en medios (normalizados) (paneles superiores) y las ventas resultantes (panel inferior). Nuestro conjunto de datos también incluye un período (entre las líneas rojas discontinuas) en el que realizamos una campaña de marketing que incrementó nuestro gasto en medios en un 40%.
Construya un MMM y ajuste a los datos#
Como parte de nuestro flujo de trabajo regular de MMM, construiremos un objeto MMM y lo ajustaremos a nuestros datos sintéticos.
mmm = MMM(
date_column="date_week",
adstock=GeometricAdstock(l_max=8),
saturation=LogisticSaturation(),
channel_columns=["x1", "x2"],
control_columns=["t"],
yearly_seasonality=2,
)
# prepare data for model
X = df_actual.drop("y", axis=1)
y = df_actual["y"]
# fit
mmm.fit(X=X, y=y, target_accept=0.85, chains=4, random_seed=rng)
# generate posterior predictive samples
mmm.sample_posterior_predictive(X, extend_idata=True, combined=True);
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [intercept, adstock_alpha, saturation_lam, saturation_beta, gamma_control, gamma_fourier, y_sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 16 seconds.
Sampling: [y]
Antes de comenzar nuestro procedimiento para la inferencia contrafactual, primero confirmemos que el MMM está haciendo un trabajo razonable al contabilizar los datos. A continuación se muestra un gráfico de la distribución predictiva posterior para las ventas (regiones sombreadas) y las ventas reales (línea negra).
fig = mmm.plot_posterior_predictive(original_scale=True)
plot_intervention_dates(intervention_dates, fig.get_axes()[0])
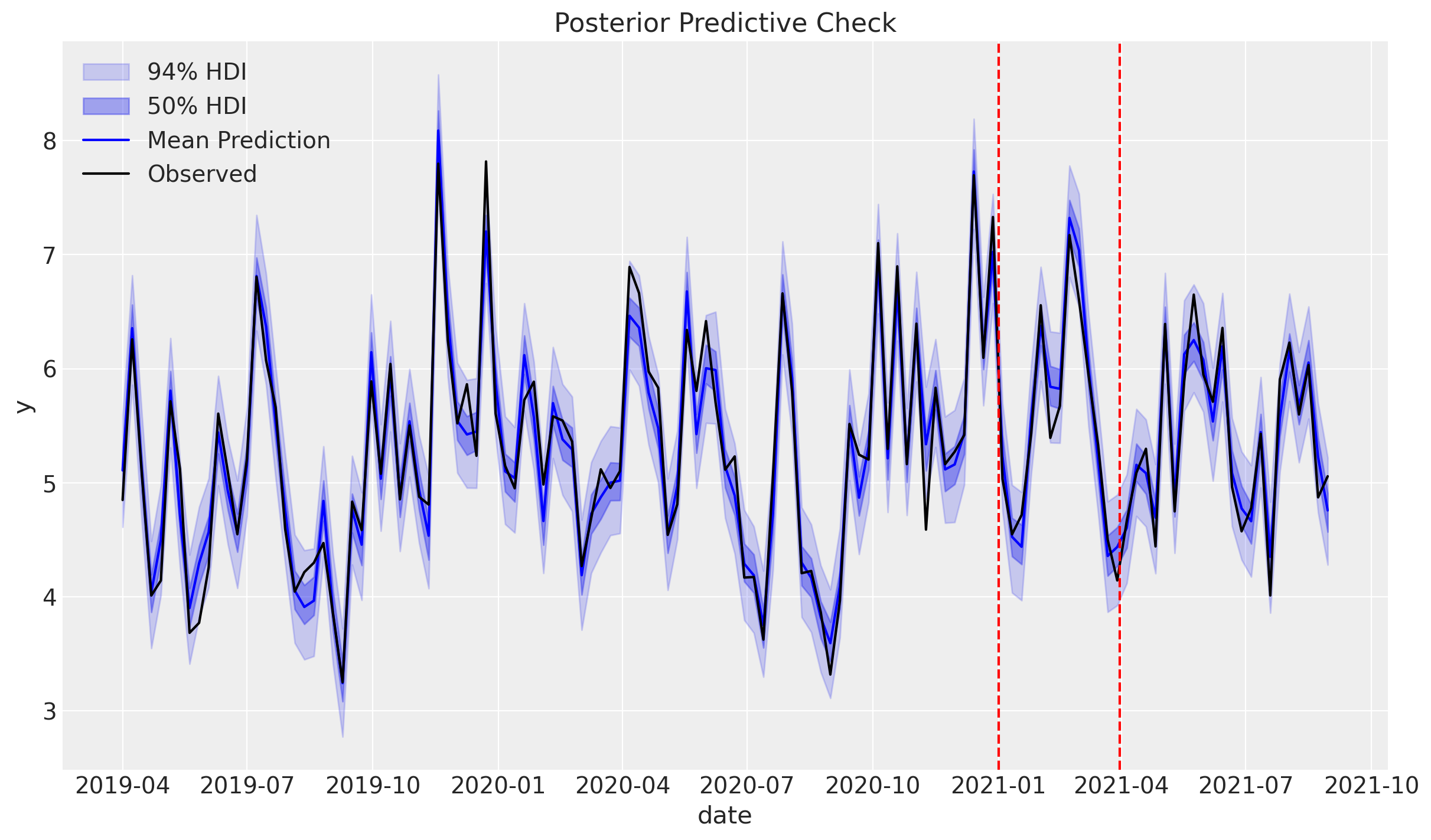
El modelo parece estar haciendo un buen trabajo al capturar los datos, por lo que podemos proceder.
Nivel 1 - Asociación y Predicción#
En el Nivel 1 de la escalera, podemos hacer al menos 2 cosas:
Explora los resultados del ajuste del modelo: obtén información sobre la relación entre el gasto en medios y las ventas. No obstante, en este punto, incluso si nuestro MMM representa un DAG causal que captura lo que creemos que son relaciones causales razonables, todavía estamos operando únicamente a nivel de predicción y asociación.
Utilice el modelo para predecir las ventas futuras. Este es un caso de uso común de los MMM y corresponde al paso 1 en la escalera causal. Profundicemos en esto con más detalle.
Para predecir las ventas futuras, necesitamos especificar los valores futuros de nuestras variables predictoras. Para simplificar, asumiremos que nuestro gasto en medios tomará el promedio de los gastos en medios pasados. Luego utilizaremos el MMM para predecir las ventas futuras. El código a continuación genera un escenario para la previsión.
n_new_periods = 20
X_forecast = pd.DataFrame(
{
"date_week": pd.date_range(
start=X["date_week"].max(), periods=1 + n_new_periods, freq="W-MON"
)[1:]
}
).assign(
# assume avarage of historical spends into the future
x1=X["x1"].mean(),
x2=X["x2"].mean(),
# other features
t=lambda df: range(len(X), len(X) + n_new_periods),
)
X_forecast.head()
| date_week | x1 | x2 | t | |
|---|---|---|---|---|
| 0 | 2021-09-06 | 0.290445 | 0.244675 | 127 |
| 1 | 2021-09-13 | 0.290445 | 0.244675 | 128 |
| 2 | 2021-09-20 | 0.290445 | 0.244675 | 129 |
| 3 | 2021-09-27 | 0.290445 | 0.244675 | 130 |
| 4 | 2021-10-04 | 0.290445 | 0.244675 | 131 |
Ahora tenemos un “escenario de pronóstico” que podemos utilizar para que nuestro MMM prediga las ventas futuras, basándose en lo que ha aprendido de los datos históricos.
y_forecast = mmm.sample_posterior_predictive(
X_forecast, extend_idata=False, include_last_observations=True
)
Sampling: [y]
Visualicemos las ventas pronosticadas.
/var/folders/pd/p2qnky2x3xl4w3mgc4lct2200000gn/T/ipykernel_63803/843057844.py:16: FutureWarning: The behavior of DatetimeProperties.to_pydatetime is deprecated, in a future version this will return a Series containing python datetime objects instead of an ndarray. To retain the old behavior, call `np.array` on the result
X_out_of_sample["date_week"].dt.to_pydatetime(),
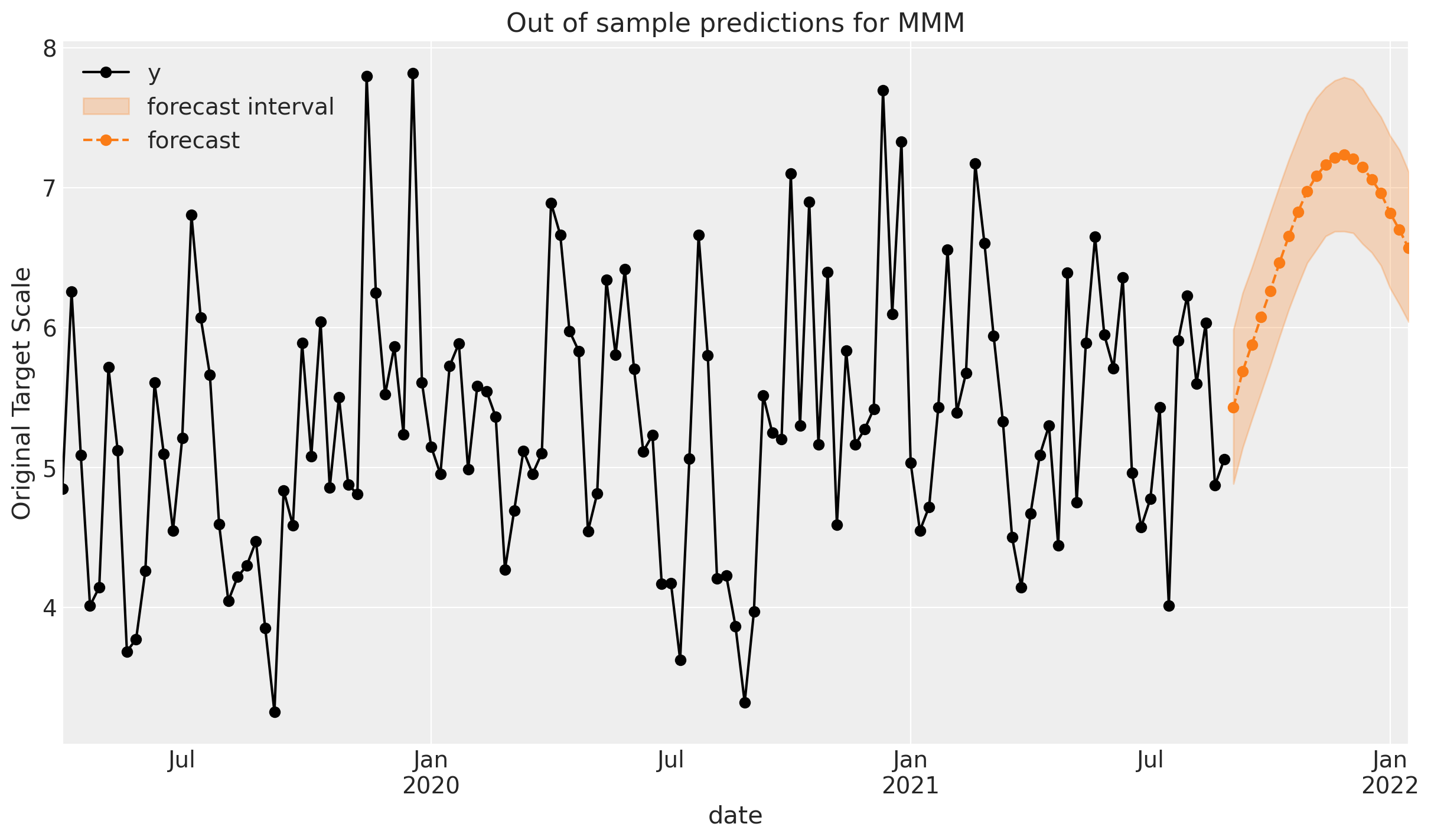
El gráfico anterior muestra la predicción del modelo para las ventas futuras (región sombreada). Tomemos un momento para desglosar lo que estamos viendo:
En nuestro escenario de pronóstico, hacemos la suposición simplificadora de que el gasto futuro en medios (para ambos canales) se mantendría en un nivel constante, igual a sus promedios históricos.
Por lo tanto, no hay una variación real en la predicción del modelo para las ventas futuras desde la perspectiva del gasto en medios.
Sin embargo, el modelo tiene una tendencia y un componente estacional, por lo que la variación en la predicción se debe a estos componentes.
Podemos, por supuesto, hacer esto más realista considerando diferentes escenarios para el gasto en medios futuros, pero es una cuestión de refinamiento. Lo que hemos visto hasta ahora es el proceso general de utilizar un MMM para la previsión de estilo Paso 1.
Nivel 2 - Intervención#
Ahora subiremos un peldaño y veremos cómo podemos utilizar nuestro MMM para predecir el efecto de una intervención. En este caso, consideraremos el efecto del promedio histórico del canal \(x_2\) y doblaremos el promedio histórico del canal \(x_1\). Así que generemos las variables predictoras para este escenario de intervención:
X_intervention = pd.DataFrame(
{
"date_week": pd.date_range(
start=X["date_week"].max(), periods=1 + n_new_periods, freq="W-MON"
)[1:]
}
).assign(
x1=X["x1"].mean() * 2, # double the historical average spend
x2=X["x2"].mean(), # maintain the historical average spend
# other features
t=lambda df: range(len(X), len(X) + n_new_periods),
)
X_intervention.head()
| date_week | x1 | x2 | t | |
|---|---|---|---|---|
| 0 | 2021-09-06 | 0.58089 | 0.244675 | 127 |
| 1 | 2021-09-13 | 0.58089 | 0.244675 | 128 |
| 2 | 2021-09-20 | 0.58089 | 0.244675 | 129 |
| 3 | 2021-09-27 | 0.58089 | 0.244675 | 130 |
| 4 | 2021-10-04 | 0.58089 | 0.244675 | 131 |
Ahora podemos ejecutar la intervención y preguntar al MMM qué cree que será el efecto de esta intervención en las ventas futuras. Más formalmente, esto equivale a muestrear de la distribución predictiva posterior, pero bajo el escenario de intervención.
y_intervention = mmm.sample_posterior_predictive(
X_intervention, extend_idata=False, include_last_observations=True
)
Sampling: [y]
/var/folders/pd/p2qnky2x3xl4w3mgc4lct2200000gn/T/ipykernel_63803/843057844.py:16: FutureWarning: The behavior of DatetimeProperties.to_pydatetime is deprecated, in a future version this will return a Series containing python datetime objects instead of an ndarray. To retain the old behavior, call `np.array` on the result
X_out_of_sample["date_week"].dt.to_pydatetime(),
/var/folders/pd/p2qnky2x3xl4w3mgc4lct2200000gn/T/ipykernel_63803/843057844.py:16: FutureWarning: The behavior of DatetimeProperties.to_pydatetime is deprecated, in a future version this will return a Series containing python datetime objects instead of an ndarray. To retain the old behavior, call `np.array` on the result
X_out_of_sample["date_week"].dt.to_pydatetime(),
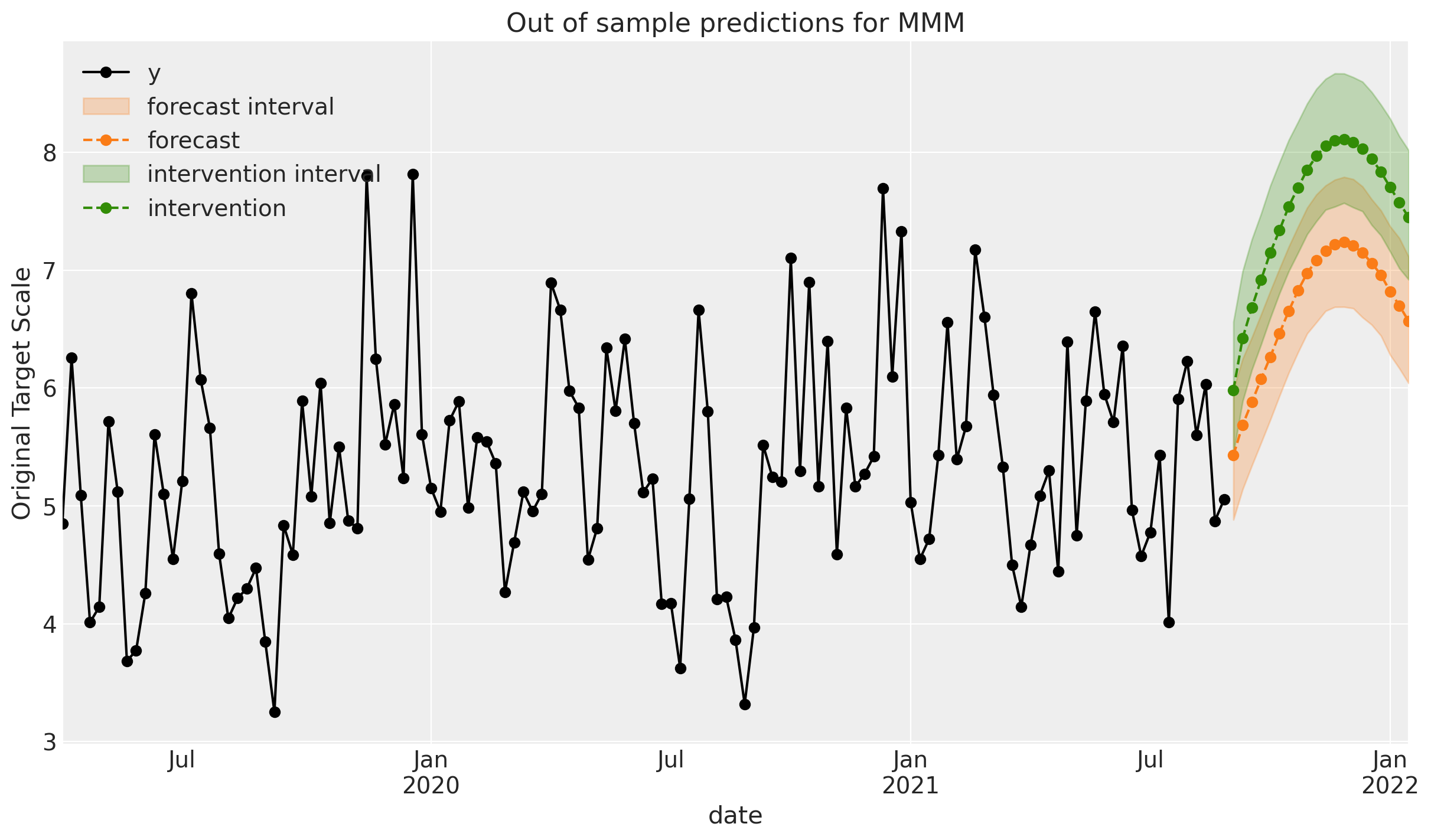
¡Genial! Podemos ver que, en relación con nuestro “negocio como siempre” (pronóstico del Paso 1), el MMM predice que la intervención conducirá a un aumento en las ventas. Este es un ejemplo simple de cómo utilizar un MMM para inferencia causal: estamos prediciendo el efecto de una intervención en las ventas futuras.
Ver también
Para obtener mucha más información sobre el uso del Nivel 2 de la escalera causal, consulte el cuaderno dedicado en Asignación de Presupuesto con PyMC-Marketing.
Nivel 3 - Inferencia contrafactual#
¡Finalmente estamos en la cima de la escalera! Ahora utilizaremos nuestro MMM para estimar el efecto de una intervención previa. Recuerde que nuestro conjunto de datos históricos incluye un período en el que aumentamos el gasto en medios en \(x_1\) en un 40%. Utilizaremos nuestro MMM para estimar el efecto de esta intervención en las ventas.
Para hacer esto, compararemos lo que realmente sucedió con lo que creemos que habría sucedido bajo algún escenario contrafactual alternativo imaginado, como no aumentar el gasto en medios en un 40%.
Esto requiere idear un escenario contrafactual en el que debemos pensar detenidamente sobre cuál habría sido el gasto en medios de $x_1 en ausencia de la campaña. En situaciones del mundo real, esto puede ser fácil o difícil, dependiendo.
Fácil: Si nuestro gasto en marketing es predecible, simplemente podemos utilizar nuestro conocimiento empresarial para definir cuál habría sido el gasto en ausencia de la campaña.
Difícil: Si nuestro gasto en marketing es impredecible, podríamos tener que utilizar un modelo más sofisticado para predecir cuál habría sido el gasto en ausencia de la campaña. Hay formas de hacerlo, pero es un poco una misión secundaria, por lo que está más allá del alcance de este cuaderno.
En nuestro caso, tomaremos el camino fácil. Debido a que simulamos los datos, ya sabemos cuál habría sido nuestro gasto en medios en ausencia de la campaña. Podemos utilizar esta información para definir nuestro escenario contrafactual. Esto nos permite adoptar un enfoque de recuperación de parámetros: podremos comparar las predicciones contrafactuales del modelo con la verdad objetiva.
Recuperación de parámetros
La lógica de seguir estos pasos con datos simulados reales y contrafactuales es que podemos comparar la capacidad del MMM para estimar el impacto causal de la campaña de marketing con el verdadero impacto causal que conocemos porque simulamos los datos. Si lo hacemos bien aquí, podemos tener más confianza en que el MMM podrá estimar el impacto causal de la campaña de marketing en datos reales donde solo están disponibles los datos reales.
Hagamos esto más real al visualizar los predictores x1 y x2, junto con la variable de resultado y. Esto se realiza tanto para los escenarios reales como para los contrafactuales. Podemos observar que hay una divergencia en el gasto en medios en x1 durante el período de la campaña y también para la variable de resultado y. La diferencia entre el resultado en los escenarios real y contrafactual es el efecto causal de la campaña de marketing (gráfico inferior).
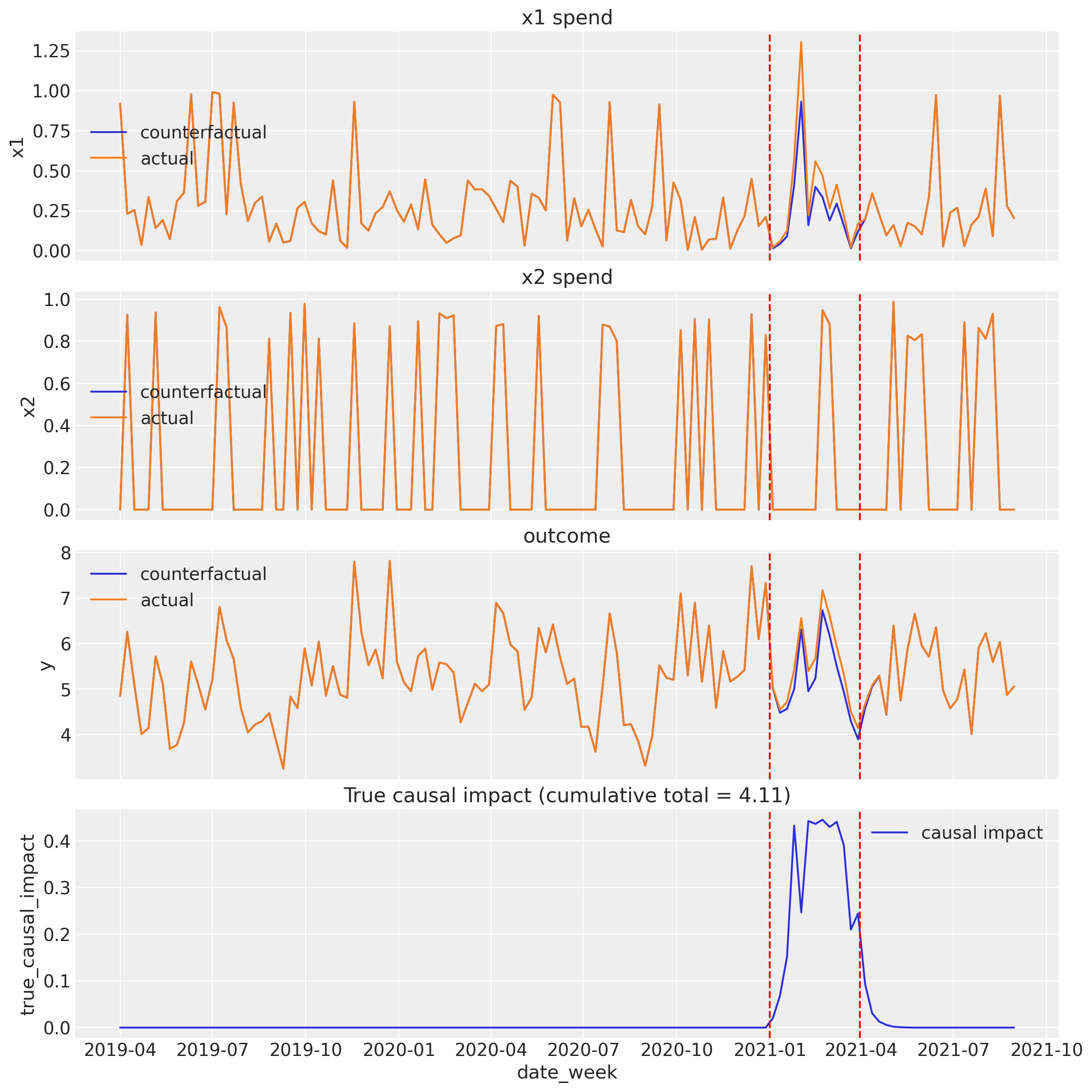
Nota
Observe en el gráfico inferior que el impacto causal de la campaña continúa durante un corto período después de que la campaña ha terminado. Esto es un resultado directo de la función de adstock en el MMM, que modela el efecto rezagado del gasto en medios sobre las ventas. De manera similar, hay un ligero efecto rezagado al inicio de la campaña. También hay ruido en el impacto causal; esto tiene sentido porque la forma en que simulamos estos datos se basó en cambios en el gasto en medios, no en un nivel específico de diferencia en ventas.
Ahora queremos evaluar qué piensa el modelo que habría sucedido en el escenario contrafactual en el que la intervención no tuvo lugar. Para esto, utilizaremos el gasto contrafactual en df.x1. Pero recuerde, en un escenario del mundo real, no tendríamos acceso a estos datos y, por lo tanto, tendríamos que estimarlos como se discutió anteriormente.
X_counterfactual = df_counterfactual[["t", "date_week", "x1", "x2"]]
X_counterfactual.head()
| t | date_week | x1 | x2 | |
|---|---|---|---|---|
| 0 | 0 | 2019-04-01 | 0.918883 | 0.0000 |
| 1 | 1 | 2019-04-08 | 0.230898 | 0.9264 |
| 2 | 2 | 2019-04-15 | 0.254486 | 0.0000 |
| 3 | 3 | 2019-04-22 | 0.035995 | 0.0000 |
| 4 | 4 | 2019-04-29 | 0.336013 | 0.0000 |
El comando a continuación utiliza de manera efectiva el operador do para intervenir en el DAG y establecer x1 en el gasto contrafactual, y usar el modelo para predecir cuáles habrían sido las ventas en el escenario contrafactual.
y_counterfactual = mmm.sample_posterior_predictive(
X_counterfactual, extend_idata=False
);
Sampling: [y]
Ahora que tenemos los datos de ventas reales y nuestras ventas predichas en el escenario contrafactual, podemos calcular el impacto causal de la intervención. Esto se realiza comparando las ventas reales con las ventas predichas en el escenario contrafactual.
y_obs = xr.DataArray(df_actual["y"].to_numpy(), dims=["date"])
causal_impact = y_obs - y_counterfactual["y"]
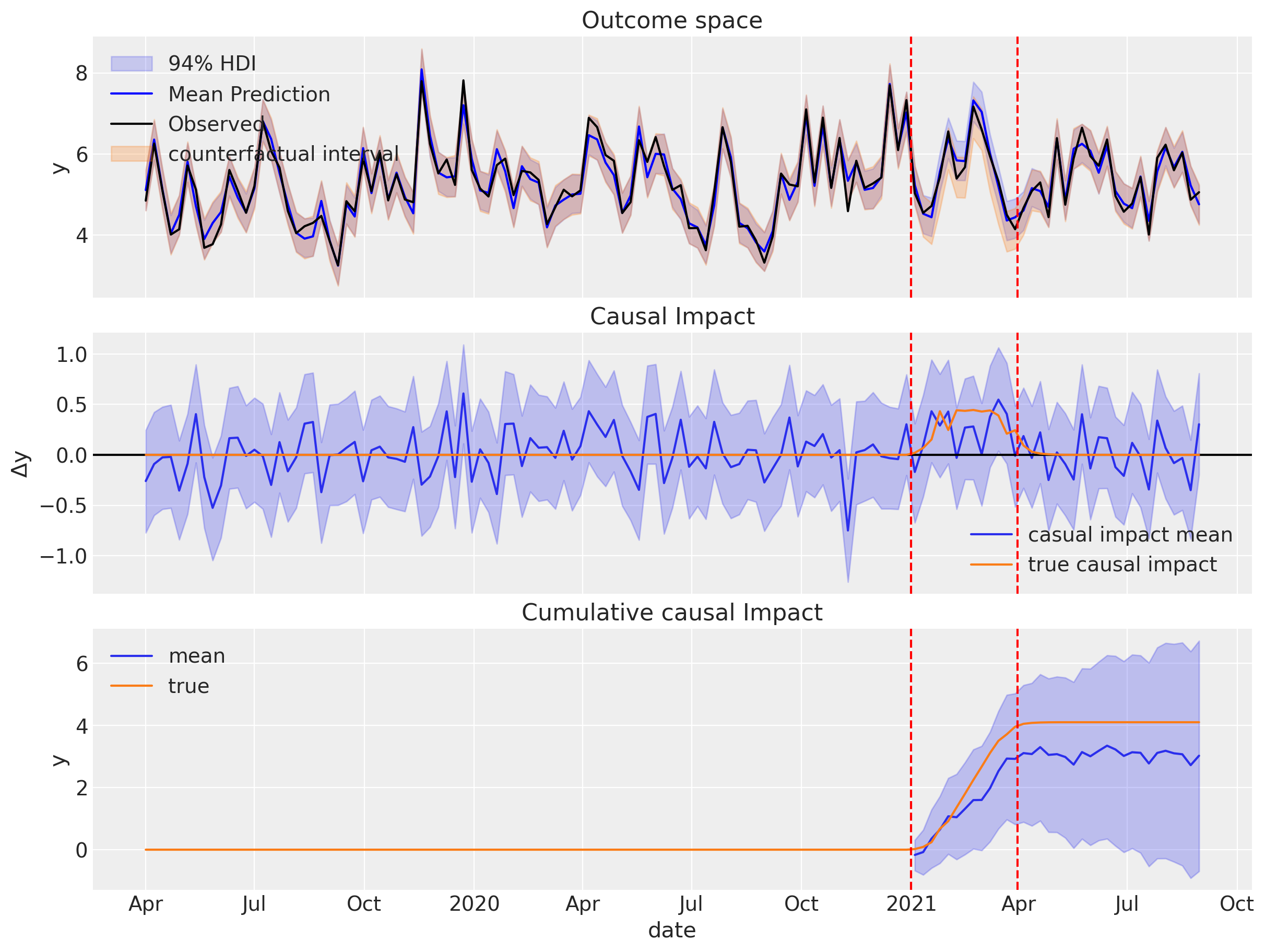
Gráfico superior: El gráfico superior muestra los datos de ventas reales (línea negra), las ventas predichas posteriores bajo el escenario actual (región sombreada en azul) y las ventas predichas posteriores bajo el escenario contrafactual (región sombreada en naranja). Podríamos observar que el modelo predice ventas más bajas en el escenario contrafactual que en el escenario actual. Esto tiene sentido porque el escenario contrafactual es aquel en el que no realizamos la campaña de marketing, por lo que se esperarían ventas más bajas en este caso.
Gráfico del medio: El gráfico del medio muestra la diferencia entre las ventas reales y las contrafactuales. Este es el impacto causal de la campaña de marketing. Podemos ver que el modelo predice un impacto causal positivo de la campaña de marketing. También podemos observar que el modelo predice un impacto causal negligible de la campaña de marketing antes de que comenzara la campaña; esto tiene total sentido, pero es importante verificar que no tengamos algún impacto causal inesperado antes de que comenzara la campaña.
Gráfico inferior: El gráfico inferior muestra el impacto causal acumulado estimado desde el inicio de la campaña. Y dado que simulamos los datos y conocemos el verdadero impacto causal, podemos ver que el modelo está funcionando bien.
Resumen#
En este cuaderno, hemos resumido la escalera causal de Pearl y hemos visto cómo se pueden aplicar diferentes niveles de razonamiento causal para resolver problemas empresariales con MMMs. Hemos observado cómo se pueden utilizar los MMMs para predecir ventas futuras (Paso 1), optimizar el gasto en marketing (Paso 2) y evaluar el impacto de las campañas de marketing (Paso 3).
Vimos cómo la inferencia contrafactual puede ser utilizada para estimar el impacto causal de las campañas de marketing. En este cuaderno utilizamos el «Modo Dios» para simular un mundo en el que teníamos conocimiento del escenario contrafactual, pero en casos de uso del mundo real, es posible que tengamos que estimar cuál habría sido el gasto en medios si no hubiéramos realizado una campaña de marketing.
Por supuesto, los métodos demostrados aquí pueden utilizarse de otras maneras. Una inmediata que viene a la mente es evaluar el impacto causal de nuestro gasto en medios pasados comparándolo con un escenario contrafactual de gasto en medios cero (en uno o múltiples canales), por ejemplo.
Esperamos que vea cómo esto puede ser una herramienta poderosa para que las empresas comprendan el impacto de sus esfuerzos de marketing y tomen decisiones basadas en datos.
%load_ext watermark
%watermark -n -u -v -iv -w -p pymc_marketing,pytensor
Last updated: Wed Nov 06 2024
Python implementation: CPython
Python version : 3.10.15
IPython version : 8.29.0
pymc_marketing: 0.10.0
pytensor : 2.22.1
seaborn : 0.13.2
IPython : 8.29.0
pandas : 2.2.3
graphviz : 0.20.3
pymc_marketing: 0.10.0
xarray : 2024.10.0
numpy : 1.26.4
matplotlib : 3.9.2
arviz : 0.20.0
Watermark: 2.5.0