Entendiendo su MMM: Análisis de Sensibilidad y Efectos Marginales#
Extraer información para impulsar decisiones comerciales es un objetivo principal de cualquier MMM. PyMC-Marketing ya ofrece un conjunto potente de herramientas para esto, que incluye:
Contribuciones de los controladores: Comprender cuánto está contribuyendo cada canal o factor al resultado.
Retorno de la Inversión en Publicidad (ROAS): Cuantificando el retorno financiero de sus inversiones en medios.
Curvas de saturación: Visualizando cómo el impacto del gasto en medios cambia a diferentes niveles de gasto (por ejemplo, rendimientos decrecientes).
Sin embargo, en muchos casos del mundo real, queremos ir más allá de estos resúmenes. Los especialistas en marketing y los analistas preguntan con frecuencia:
¿Qué habría pasado si hubiéramos gastado un 10% menos en medios el mes pasado?
¿Cuál habría sido el efecto de reducir el umbral de envío gratuito en $5?
¿Seguimos obteniendo buenos rendimientos incrementales con los niveles de gasto actuales, o hemos alcanzado rendimientos decrecientes?
Estas preguntas se centran en escenarios hipotéticos de lo que habría sucedido bajo diferentes condiciones. Como tal, son una forma clara de análisis de sensibilidad. Dado que nos enfocamos en predicciones retrospectivas, estas preguntas son «Paso 3» en la escalera causal de Pearl (consulte la documentación sobre MMMs y la escalera de inferencia causal de Pearl). La idea básica es que podemos usar nuestro modelo (y lo que ha aprendido de los datos) para simular cómo habría cambiado el resultado bajo varias perturbaciones de las variables impulsoras.
En lugar de considerar una sola perturbación (por ejemplo, «¿qué pasaría si hubiéramos gastado un 10% menos en un canal de medios determinado?»), el análisis de sensibilidad nos permite explorar una gama de escenarios. Así que, en su lugar, podríamos evaluar nuestras predicciones dado un barrido de posibles perturbaciones. Por ejemplo, «¿qué pasaría si hubiéramos gastado [0.5, 0.75, 1.0, 1.25, 2.0] veces más en un canal de medios determinado?»
Le presentamos una herramienta flexible que le permite:
Realice barridos contrafactuales a través de una variedad de valores predictivos (por ejemplo, aumentando/disminuyendo el gasto en medios o ajustando palancas comerciales como los precios).
Visualice tanto el impacto total esperado de estas intervenciones.
Calcular efectos marginales—mostrando la tasa de cambio instantánea en el resultado a medida que ajusta un predictor.
Este enfoque complementa las herramientas integradas de PyMC-Marketing al proporcionar información basada en escenarios que le ayuda a responder preguntas de «¿qué pasaría si?» con precisión y claridad.
Estableciendo el escenario con un conjunto de datos de ejemplo#
En este ejemplo, modelamos las ventas semanales para una marca de venta directa al consumidor (DTC) que invierte en marketing de influencers mientras también ajusta su política de envío gratuito para impulsar las conversiones.
Nuestra variable de medios es Gasto en Influencers, que típicamente presenta efectos no lineales debido a factores como la saturación de la audiencia y el impacto retrasado, lo que la convierte en una buena candidata para transformaciones de adstock y saturación.
Como variable de control, incluimos el Umbral de Envío Gratis — el valor mínimo de pedido requerido para que los clientes califiquen para el envío gratis. Este es un factor empresarial completamente controlable y se espera que tenga una relación más lineal con las ventas: reducir el umbral generalmente aumenta las tasas de conversión de manera predecible.
Al examinar los efectos marginales del gasto en medios y la política de envío, podemos proporcionar información práctica sobre cómo cada palanca contribuye al rendimiento general.
import warnings
import arviz as az
import graphviz as gr
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pymc_marketing.mmm import (
GeometricAdstock,
LogisticSaturation,
)
from pymc_marketing.mmm.multidimensional import MMM
from pymc_marketing.mmm.transformers import geometric_adstock, logistic_saturation
warnings.filterwarnings("ignore", category=FutureWarning)
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "retina"
seed: int = sum(map(ord, "ladder"))
rng: np.random.Generator = np.random.default_rng(seed=seed)
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
/Users/carlostrujillo/Documents/GitHub/pymc-marketing/pymc_marketing/mmm/multidimensional.py:216: FutureWarning: This functionality is experimental and subject to change. If you encounter any issues or have suggestions, please raise them at: https://github.com/pymc-labs/pymc-marketing/issues/new
warnings.warn(warning_msg, FutureWarning, stacklevel=1)
Así que nuestro MMM causal se verá así:

Por qué importan los efectos marginales: yendo más allá de las curvas de medios brutos#
En los Modelos de Mezcla de Medios (MMM), a menudo estamos interesados en comprender cómo cada insumo de marketing (como el gasto en publicidad) impulsa los resultados comerciales. Una forma común de explorar esto es observando las curvas de respuesta inferidas, como la curva de saturación para el gasto en medios. Estas curvas muestran cómo las ventas totales responden a un aumento en la inversión, teniendo en cuenta efectos como los rendimientos decrecientes y el adstock.
Pero aunque estos gráficos son útiles, pueden ser engañosos o incompletos cuando se utilizan de forma aislada.
La razón es la siguiente: las curvas de respuesta te indican el nivel absoluto de impacto en diferentes cantidades de gasto, pero no te dicen directamente el impacto incremental de un pequeño cambio en el gasto en un momento dado. Esta distinción es crucial. Por ejemplo:
Una curva de saturación puede parecer empinada en niveles de gasto bajos y aplanarse en niveles de gasto más altos, pero la pendiente exacta en un punto específico (por ejemplo, $50,000 por semana) te indica el rendimiento real de gastar un extra de $1,000 en este momento.
En casos donde múltiples entradas están en juego (como el gasto en medios y los cambios de precios), las curvas de respuesta para una variable no muestran cómo las interacciones o los niveles actuales de otras variables podrían afectar su impacto marginal.
Los efectos marginales se centran en esta pendiente: la tasa de cambio instantánea. Responden a preguntas como:
¿Cuánto aumento en ventas adicionales obtengo si incremento el gasto en influencers en un 10% la próxima semana?
¿Cuál es el aumento esperado si reduzco el umbral de envío gratuito en $5 ahora mismo?
Estos conocimientos solo son accesibles a través de efectos marginales porque reflejan la capacidad de respuesta dinámica y sensible al contexto del modelo:
Para las entradas de medios con transformaciones no lineales (como adstock + saturación), los efectos marginales muestran cómo varía la efectividad a lo largo del rango de gasto, revelando si aún te encuentras en la zona de alto ROI o si has alcanzado rendimientos decrecientes.
Para palancas no mediáticas controlables (como políticas de precios o de envío), los efectos marginales proporcionan estimaciones precisas y accionables sobre cómo los ajustes a estas palancas impactan los resultados, incluso si su relación general es más lineal.
En otras palabras, mientras que una curva de respuesta es como un mapa del terreno, los efectos marginales te indican si vale la pena escalar esa próxima colina. Permiten una precisión quirúrgica en la toma de decisiones, asegurando que los mercadólogos no solo vean dónde se sitúan sus esfuerzos en una curva, sino que comprendan si seguir presionando en una dirección particular sigue siendo valioso.
Al incorporar efectos marginales en los resultados de MMM, pasamos de una comprensión estática del rendimiento de los medios a una visión dinámica y consciente del contexto que informa directamente sobre la asignación de recursos y los ajustes estratégicos.
Generar datos simulados#
Y aquí están las primeras 5 filas del conjunto de datos sintético:
df.head()
| date | year | month | dayofyear | t | influencer_spend | shipping_threshold | intercept | trend | cs | cc | seasonality | epsilon | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019-04-01 | 2019 | 4 | 91 | 0 | 0.918883 | 25.0 | 2.0 | 0.778279 | -0.012893 | 0.006446 | -0.003223 | -0.118826 | 2.561363 |
| 1 | 2019-04-08 | 2019 | 4 | 98 | 1 | 0.230898 | 25.0 | 2.0 | 0.795664 | 0.225812 | -0.113642 | 0.056085 | 0.064977 | 2.264874 |
| 2 | 2019-04-15 | 2019 | 4 | 105 | 2 | 0.254486 | 25.0 | 2.0 | 0.812559 | 0.451500 | -0.232087 | 0.109706 | -0.020269 | 1.998208 |
| 3 | 2019-04-22 | 2019 | 4 | 112 | 3 | 0.035995 | 25.0 | 2.0 | 0.828993 | 0.651162 | -0.347175 | 0.151993 | 0.400209 | 1.701116 |
| 4 | 2019-04-29 | 2019 | 4 | 119 | 4 | 0.336013 | 25.0 | 2.0 | 0.844997 | 0.813290 | -0.457242 | 0.178024 | 0.057609 | 2.003646 |
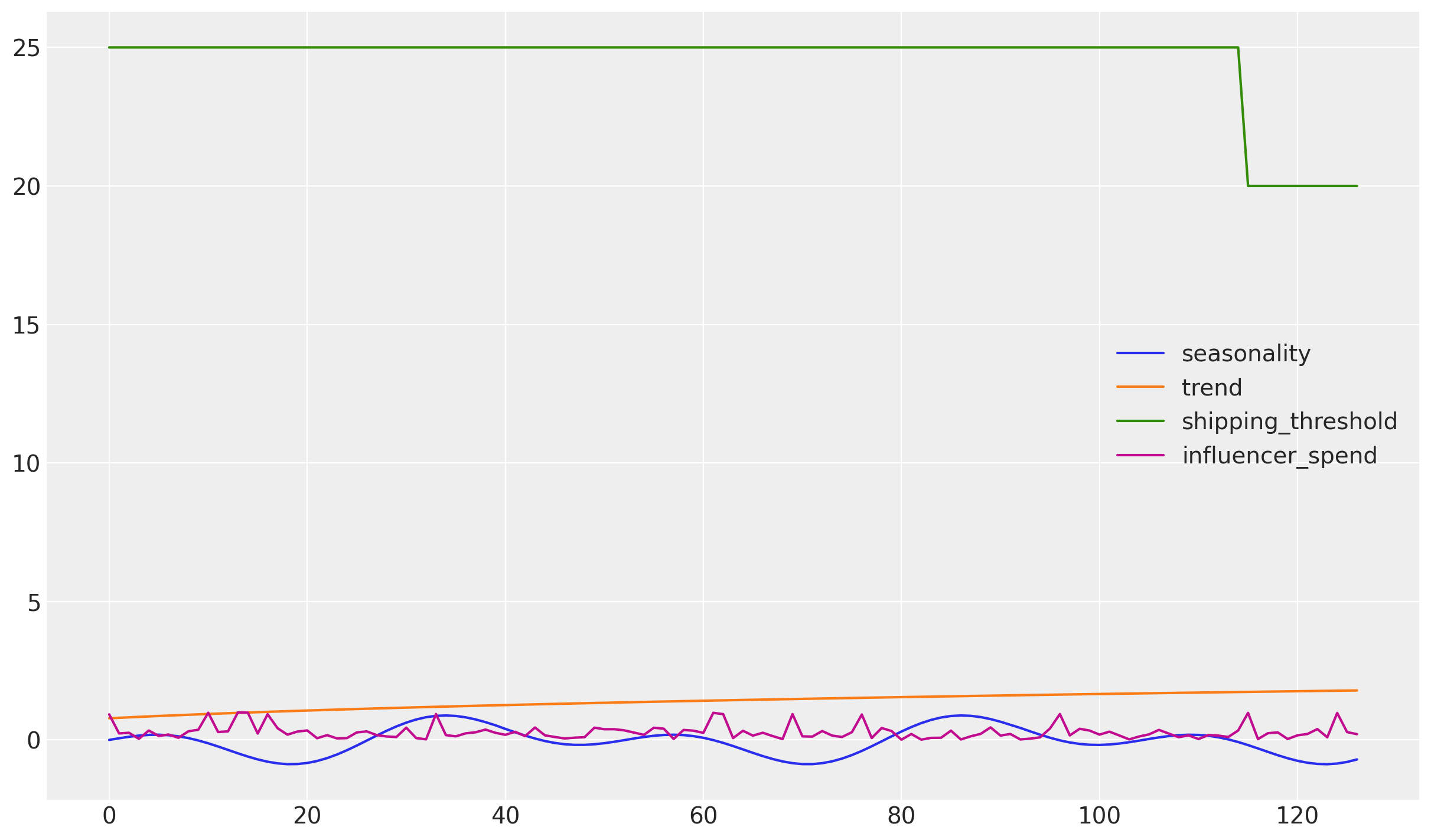
Y podemos graficar los datos para tener una mejor comprensión de la información:
df[["seasonality", "trend", "shipping_threshold", "influencer_spend"]].plot();
Construya y ajuste el MMM#
mmm = MMM(
date_column="date",
target_column="y",
adstock=GeometricAdstock(l_max=8),
saturation=LogisticSaturation(),
channel_columns=["influencer_spend"],
control_columns=["t", "shipping_threshold"],
yearly_seasonality=2,
)
x_train = df.drop(columns=["y"])
y_train = df["y"]
mmm.fit(
X=x_train,
y=y_train,
)
mmm.sample_posterior_predictive(x_train, extend_idata=True);
Análisis de sensibilidad y efectos marginales#
Un barrido multiplicativo sobre el gasto en influencers#
sweeps = np.linspace(0.1, 2.0, 100)
mmm.model.to_graphviz()

Influencer spend exist under channel_* nodes. In our graph, every individual driver will exist under those containers. We could calculate a sweep over any variable (node) in the computational graph, in this case, we pick channel data to be able to access later on influencer_spend.
Note: This compute deterministic not using aleatoric uncertainty from likelihood. Meaning, the sigma parameter for the likelihood will not modify our sweep.
mmm.sensitivity.run_sweep(
sweep_values=sweeps,
var_input="channel_data",
var_names="channel_contribution",
extend_idata=True,
);
El código anterior guarda sus resultados en un nuevo grupo en el mmm.idata llamado sensitivity_analysis. Puedes explorarlo a continuación:
mmm.idata
-
<xarray.Dataset> Size: 33MB Dimensions: (chain: 4, draw: 1000, control: 2, fourier_mode: 4, date: 127, channel: 1) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 ... 998 999 * control (control) <U18 144B 'shipping_th... * fourier_mode (fourier_mode) <U5 80B 'sin_1' .... * date (date) datetime64[ns] 1kB 2019-0... * channel (channel) <U16 64B 'influencer_s... Data variables: intercept_contribution (chain, draw) float64 32kB 0.803... adstock_alpha (chain, draw) float64 32kB 0.474... saturation_lam (chain, draw) float64 32kB 4.096... saturation_beta (chain, draw) float64 32kB 0.782... gamma_control (chain, draw, control) float64 64kB ... gamma_fourier (chain, draw, fourier_mode) float64 128kB ... y_sigma (chain, draw) float64 32kB 0.068... channel_contribution (chain, draw, date, channel) float64 4MB ... total_media_contribution_original_scale (chain, draw) float64 32kB 190.3... control_contribution (chain, draw, date, control) float64 8MB ... fourier_contribution (chain, draw, date, fourier_mode) float64 16MB ... yearly_seasonality_contribution (chain, draw, date) float64 4MB ... Attributes: created_at: 2025-10-27T10:29:49.678161+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 sampling_time: 15.281957149505615 tuning_steps: 1000 pymc_marketing_version: 0.17.0 -
<xarray.Dataset> Size: 528kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 Data variables: (12/18) index_in_trajectory (chain, draw) int64 32kB -32 23 -46 -59 ... -45 -8 -8 perf_counter_start (chain, draw) float64 32kB 1.547e+06 ... 1.547e+06 energy (chain, draw) float64 32kB -136.3 -134.9 ... -138.1 energy_error (chain, draw) float64 32kB 0.5431 ... -9.683e-05 step_size_bar (chain, draw) float64 32kB 0.04843 ... 0.04397 max_energy_error (chain, draw) float64 32kB 0.7827 2.718 ... -0.09356 ... ... divergences (chain, draw) int64 32kB 0 0 0 0 0 0 ... 0 0 0 0 0 0 diverging (chain, draw) bool 4kB False False ... False False n_steps (chain, draw) float64 32kB 127.0 63.0 ... 63.0 127.0 lp (chain, draw) float64 32kB 142.4 141.9 ... 144.6 tree_depth (chain, draw) int64 32kB 7 6 6 6 6 6 ... 6 7 6 6 6 7 reached_max_treedepth (chain, draw) bool 4kB False False ... False False Attributes: created_at: 2025-10-27T10:29:49.686194+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 sampling_time: 15.281957149505615 tuning_steps: 1000 -
<xarray.Dataset> Size: 2kB Dimensions: (date: 127) Coordinates: * date (date) datetime64[ns] 1kB 2019-04-01 2019-04-08 ... 2021-08-30 Data variables: y (date) float64 1kB 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 Attributes: created_at: 2025-10-27T10:29:50.279640+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 -
<xarray.Dataset> Size: 6kB Dimensions: (channel: 1, date: 127, control: 2) Coordinates: * channel (channel) <U16 64B 'influencer_spend' * date (date) datetime64[ns] 1kB 2019-04-01 ... 2021-08-30 * control (control) <U18 144B 'shipping_threshold' 't' Data variables: channel_scale (channel) float64 8B 0.9919 target_scale float64 8B 3.981 channel_data (date, channel) float64 1kB 0.9189 0.2309 ... 0.2797 0.2041 target_data (date) float64 1kB 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 control_data (date, control) float64 2kB 25.0 0.0 25.0 ... 20.0 126.0 dayofyear (date) int32 508B 91 98 105 112 119 ... 214 221 228 235 242 Attributes: created_at: 2025-10-27T10:29:50.282164+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 -
<xarray.Dataset> Size: 13kB Dimensions: (date: 127) Coordinates: * date (date) datetime64[ns] 1kB 2019-04-01 ... 2021-08-30 Data variables: (12/13) year (date) int32 508B 2019 2019 2019 2019 ... 2021 2021 2021 month (date) int32 508B 4 4 4 4 4 5 5 5 5 ... 7 7 7 8 8 8 8 8 dayofyear (date) int32 508B 91 98 105 112 119 ... 221 228 235 242 t (date) int64 1kB 0 1 2 3 4 5 ... 121 122 123 124 125 126 influencer_spend (date) float64 1kB 0.9189 0.2309 ... 0.2797 0.2041 shipping_threshold (date) float64 1kB 25.0 25.0 25.0 ... 20.0 20.0 20.0 ... ... trend (date) float64 1kB 0.7783 0.7957 0.8126 ... 1.779 1.783 cs (date) float64 1kB -0.01289 0.2258 ... -0.9747 -0.8932 cc (date) float64 1kB 0.006446 -0.1136 ... -0.623 -0.5246 seasonality (date) float64 1kB -0.003223 0.05608 ... -0.7988 -0.7089 epsilon (date) float64 1kB -0.1188 0.06498 ... -0.3317 -0.05244 y (date) float64 1kB 2.561 2.265 1.998 ... 2.734 2.607 -
<xarray.Dataset> Size: 4MB Dimensions: (chain: 4, draw: 1000, date: 127) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 * date (date) datetime64[ns] 1kB 2019-04-01 2019-04-08 ... 2021-08-30 Data variables: y (chain, draw, date) float64 4MB 0.6217 0.4625 ... 0.6679 0.6904 Attributes: created_at: 2025-10-27T10:29:50.277380+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 -
<xarray.Dataset> Size: 3MB Dimensions: (sample: 4000, sweep: 100, channel: 1) Coordinates: * sample (sample) int64 32kB 0 1 2 3 4 5 6 ... 3994 3995 3996 3997 3998 3999 * sweep (sweep) float64 800B 0.1 0.1192 0.1384 0.1576 ... 1.962 1.981 2.0 * channel (channel) <U16 64B 'influencer_spend' Data variables: x (sample, sweep, channel) float64 3MB 5.693 6.779 ... 69.68 70.02
Truco
The group sensitivity analysis contains all the channels from the node channel_contribution. Meaning, you can select whatever channel you want.
mmm.idata["sensitivity_analysis"].sel(channel="influencer_spend")
<xarray.Dataset> Size: 3MB
Dimensions: (sample: 4000, sweep: 100)
Coordinates:
* sample (sample) int64 32kB 0 1 2 3 4 5 6 ... 3994 3995 3996 3997 3998 3999
* sweep (sweep) float64 800B 0.1 0.1192 0.1384 0.1576 ... 1.962 1.981 2.0
channel <U16 64B 'influencer_spend'
Data variables:
x (sample, sweep) float64 3MB 5.693 6.779 7.861 ... 69.35 69.68 70.02And of course, you can plot the results! To demonstrate some of the plotting options we’ll plot using the default y-axis scale of absolute sales.
_ = mmm.plot.sensitivity_analysis(
aggregation={"sum": ("channel",)},
xlabel="Sweep multiplicative",
ylabel="Total contribution over training period",
);
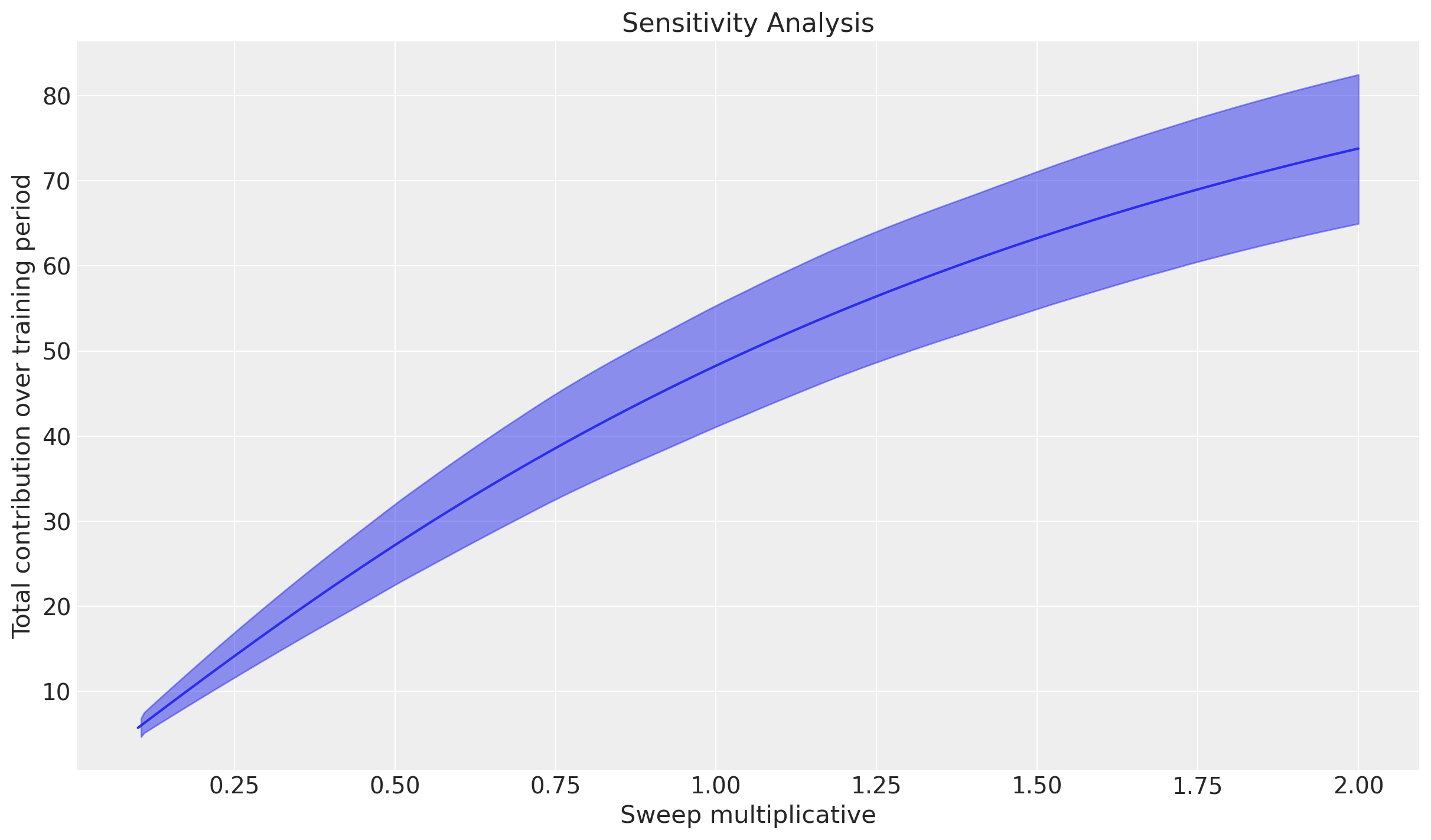
We did a multiplicative sweep. X will be the multiplicative factor and Y the total incremental conversions during the full training period at the given multiplicative factor. We could visualize this as certain uplift, respect to an arbitrary number.
For this case, we can use the historical contributions as our reference point. This will generate a curve that shows the relative uplift when we increase or decrease spending. For example: if we maintain the same spending level, the uplift relative to the current contribution will be zero. However, if we increase spending, we’ll see a positive uplift, and conversely, if we decrease spending, we’ll observe a negative uplift.
ref_value = (
mmm.idata.posterior.channel_contribution.sum(
["channel", "date"]
) # The ref can be your spend level during training
.mean(["chain", "draw"])
.item()
)
mmm.sensitivity.compute_uplift_curve_respect_to_base(
results=mmm.idata.sensitivity_analysis["x"],
ref=ref_value,
extend_idata=True,
);
_ = mmm.plot.uplift_curve(
aggregation={"sum": ("channel",)},
xlabel="Sweep multiplicative",
ylabel="Total uplift respect to historical contribution",
)
# add vertical line at zero
plt.axvline(x=1.0, color="black", linestyle="--")
# add horizontal line at zero
plt.axhline(y=0.0, color="black", linestyle="--");
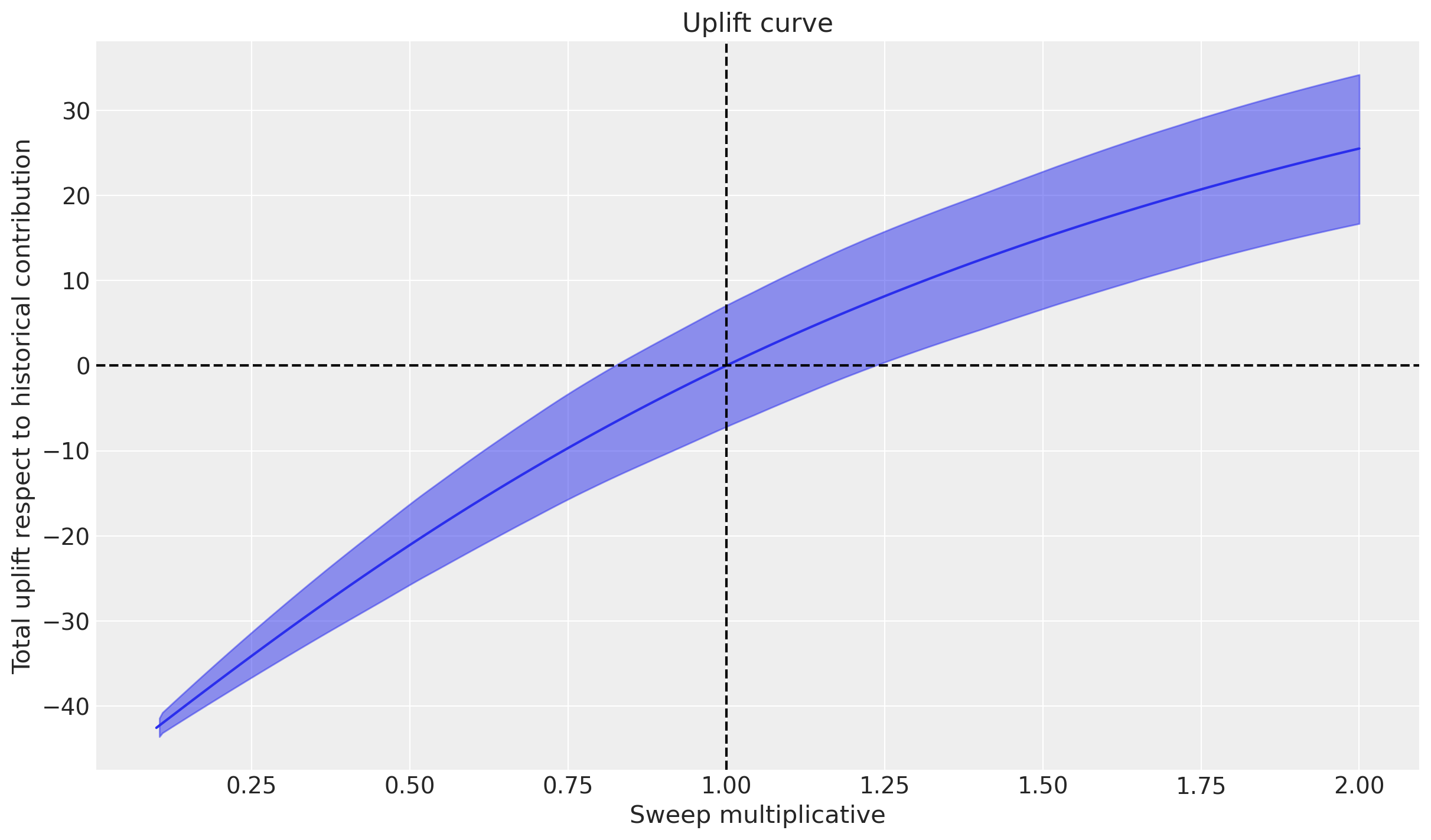
La figura anterior muestra el aumento total esperado (puede ser positivo o negativo) para la variable de resultado como una función de los valores de barrido proporcionados. En este caso, utilizamos un barrido multiplicativo, por lo que la curva muestra cómo variaría el resultado total si multiplicamos hacia arriba (valores de barrido > 1) o hacia abajo (valores de barrido < 1) el gasto en influenciadores por el conjunto de valores que solicitamos.
Intuitivamente, si multiplicamos el gasto en influencia por 1.0, entonces, en promedio, no esperamos ningún cambio. Si reducimos el gasto, entonces esperamos un aumento negativo (es decir, menores ventas) y si aumentamos el gasto, entonces esperamos un aumento positivo (es decir, mayores ventas). El hecho de que la curva sea curva (no lineal) es principalmente el resultado de la función de saturación en la variable de gasto en influenciadores.
We can also plot the corresponding marginal effects from the uplift curve as below:
mmm.sensitivity.compute_marginal_effects(
results=mmm.idata.sensitivity_analysis["uplift_curve"], extend_idata=True
);
_ = mmm.plot.marginal_curve(
aggregation={"sum": ("channel",)}, xlabel="Sweep multiplicative"
);
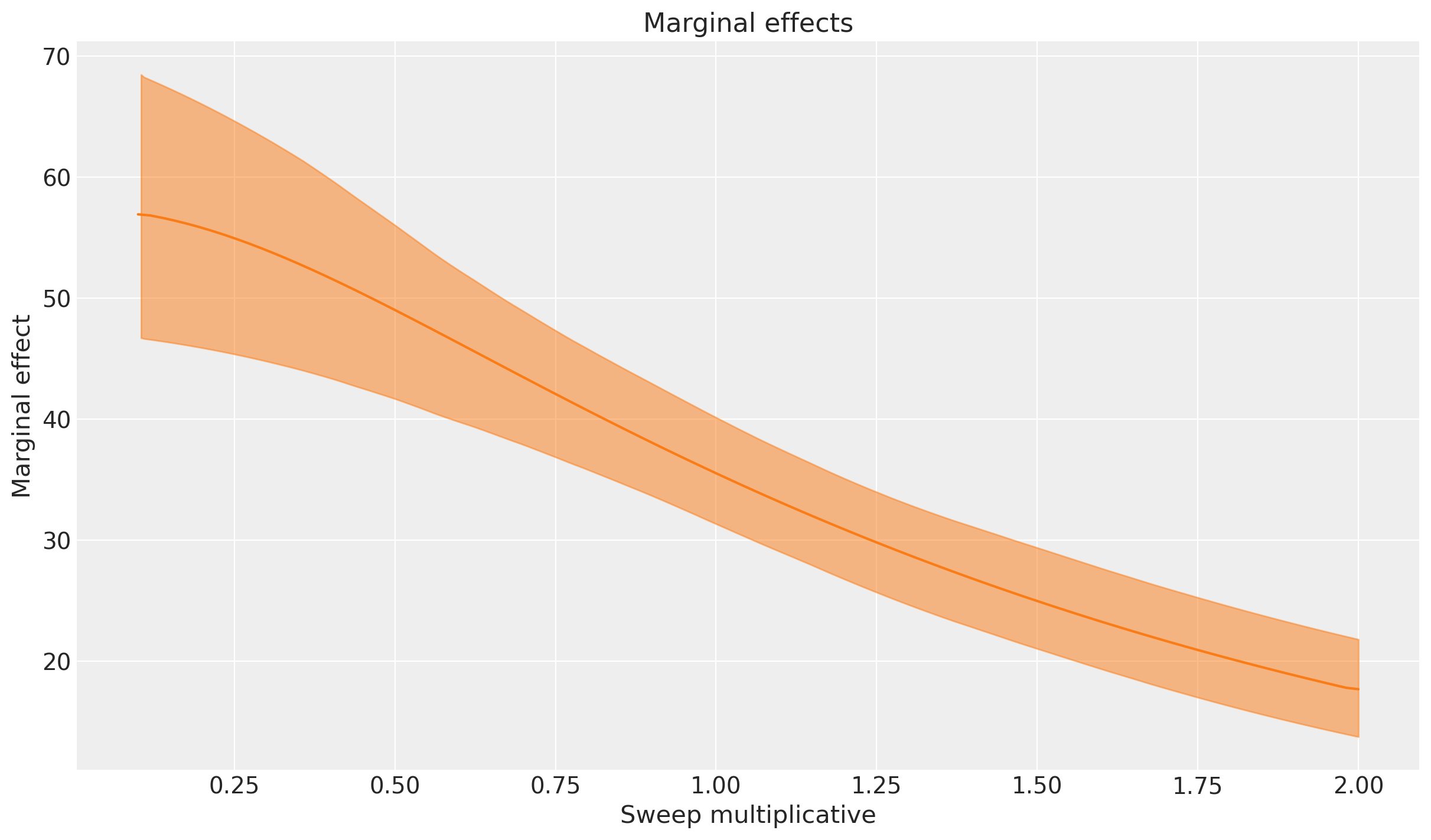
Este gráfico muestra la tasa de cambio instantánea en la variable de resultado a medida que ajustamos el gasto en influencers. El eje y representa el efecto marginal, que nos indica cuánto aumento adicional en ventas esperamos por un pequeño incremento en el gasto en influencers en cada punto a lo largo de los valores de barrido.
Podemos ver que los efectos marginales más altos ocurren en el lado izquierdo del gráfico, donde la influencia del gasto es cero o muy baja. Los efectos incrementales/marginales más altos se obtienen cuando pasamos de no gastar a gastar algo. Como esperaríamos del gráfico anterior, todavía obtenemos retornos incrementales en los niveles actuales de gasto (cambio multiplicativo de 1.0), y estamos bastante lejos de saturar completamente este canal; el gasto marginal no se reduce a cerca de cero incluso si consideramos un aumento del gasto de 2x.
Un control absoluto sobre el gasto en influencers#
El análisis de sensibilidad que realizamos anteriormente involucró un barrido multiplicativo de la variable de gasto de influencers, lo que significa que la variamos multiplicándola por un conjunto de valores. Sin embargo, también podemos realizar un barrido absoluto. Aquí, establecemos todos los valores históricos de la variable de gasto de influencers en valores fijos (dados en el argumento sweep_values) y luego calculamos el resultado esperado y los efectos marginales.
mmm.sensitivity.run_sweep(
sweep_values=sweeps,
var_input="channel_data",
var_names="channel_contribution",
sweep_type="absolute",
extend_idata=True,
);
ref_value = (
mmm.idata.posterior.channel_contribution.sum(["channel", "date"])
.mean(["chain", "draw"])
.item()
)
mmm.sensitivity.compute_uplift_curve_respect_to_base(
results=mmm.idata.sensitivity_analysis["x"],
ref=ref_value,
extend_idata=True,
)
mmm.sensitivity.compute_marginal_effects(
results=mmm.idata.sensitivity_analysis["uplift_curve"], extend_idata=True
)
_ = mmm.plot.uplift_curve(
aggregation={"sum": ("channel",)},
xlabel="Sweep absolute",
ylabel="Total uplift respect to historical contribution",
)
_ = mmm.plot.marginal_curve(aggregation={"sum": ("channel",)}, xlabel="Sweep absolute");
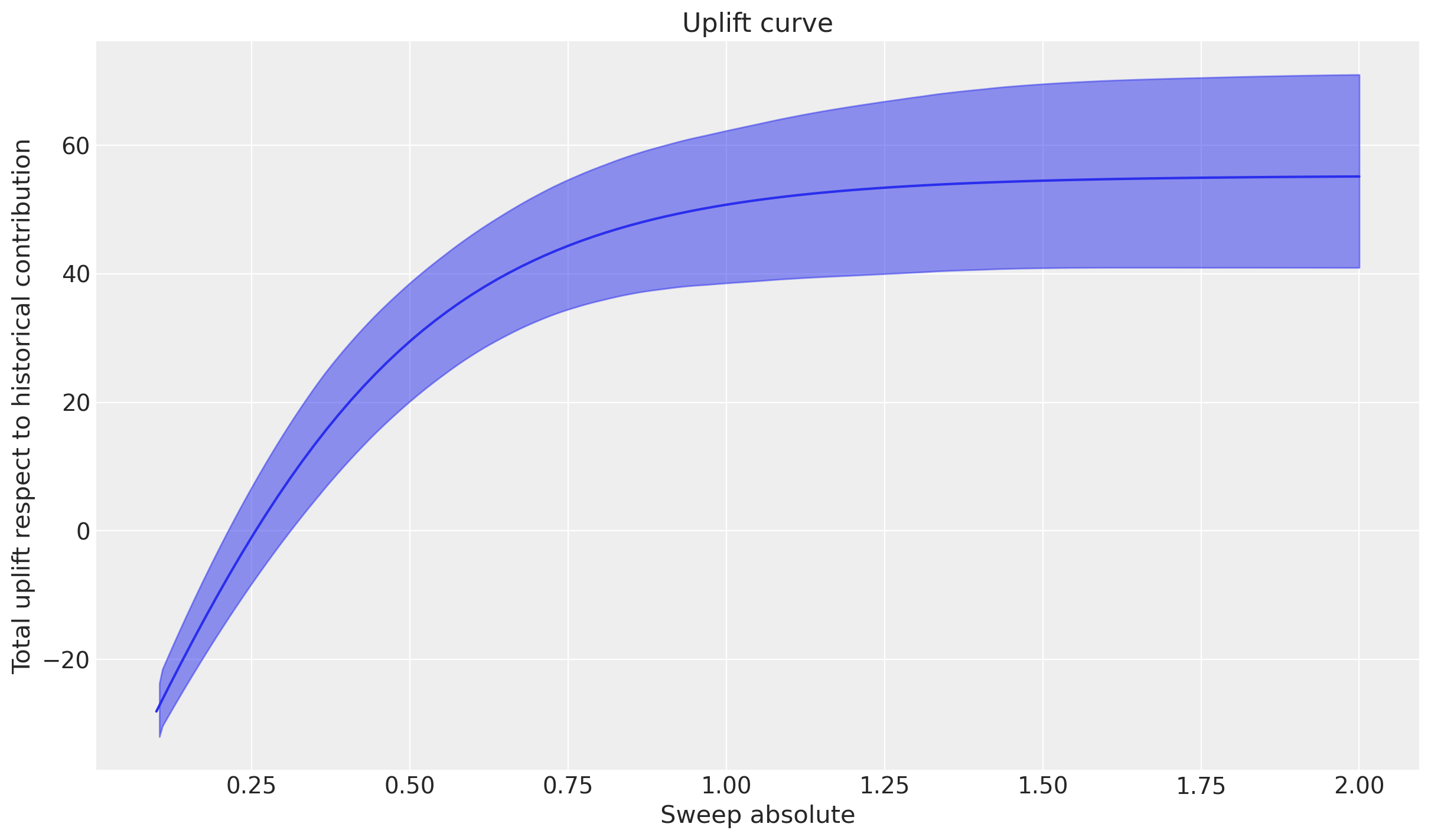
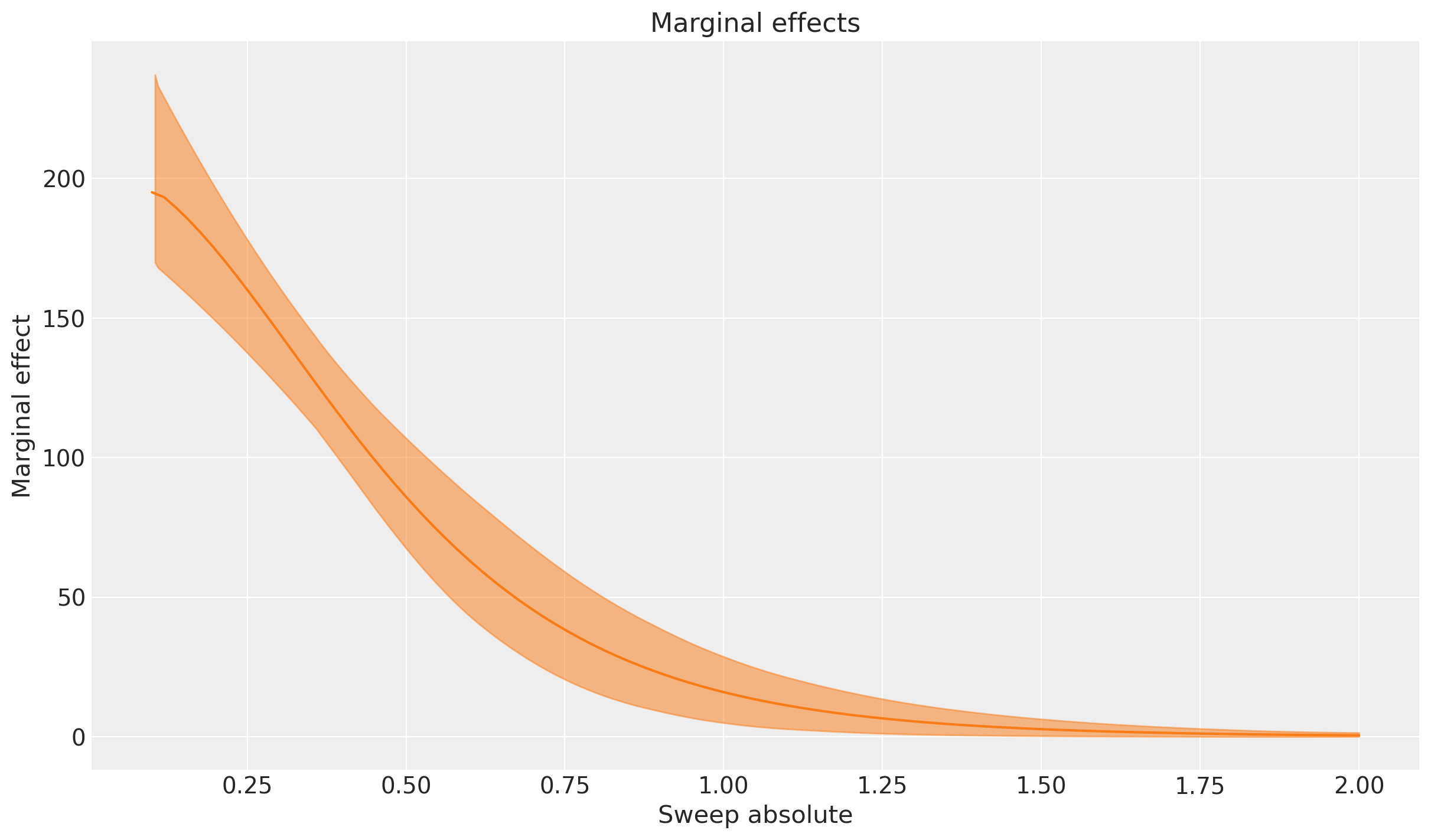
Los resultados del barrido absoluto son comparables a (pero no iguales a) los del barrido multiplicativo. La diferencia clave en lo que estamos haciendo es que sobrescribimos los valores de gasto de influenciadores históricos con un valor de gasto constante (un valor para cada punto en el barrido). Esto significa que no estamos considerando un escenario “realista” donde el gasto fluctúa a lo largo del tiempo, sino más bien un escenario hipotético donde establecemos el gasto a un valor fijo para todas las semanas en el conjunto de datos.
Podemos ver el cambio en los gráficos también. El gráfico superior es similar a, pero no exactamente igual a la curva de saturación del gasto en influencers. Observe que hay un cierto nivel de gasto fijo donde el aumento es aproximadamente cero. Esto es interesante: podemos interpretar esto como que las ventas totales en el escenario actual también habrían sido aproximadamente las mismas si hubiéramos gastado esa cantidad (constantemente a lo largo del tiempo) en marketing de influencers.
El gráfico superior muestra claramente la calidad de saturación de la función de saturación, y el gráfico inferior muestra que a medida que nos acercamos a la saturación, los efectos marginales caen a casi cero.
Un barrido aditivo sobre el gasto en influencers#
También podemos considerar un barrido de cambios aditivos en la variable de gasto de influencers. Esto significa que ajustamos los valores históricos del gasto de influencers añadiendo una cantidad fija (dada en el argumento sweep_values) y luego calculamos el resultado esperado y los efectos marginales.
Advertencia
Tenga en cuenta que se debe tener cuidado con un barrido aditivo. Sería fácil aplicar una perturbación negativa que luego resulte en valores de gasto negativos que no tienen una interpretación significativa. Por lo tanto, vale la pena explorar los valores de gasto reales antes de decidir sobre los valores de barrido que se utilizarán.
En nuestro caso, el valor mínimo de gasto es $0, por lo que no consideraremos valores en la barrida.
df["influencer_spend"].min()
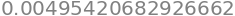
mmm.sensitivity.run_sweep(
sweep_values=sweeps,
var_input="channel_data",
var_names="channel_contribution",
sweep_type="additive",
posterior_sample_fraction=0.98,
extend_idata=True,
);
Truco
The posterior_sample_fraction parameter cuts your posterior, reducing the computational burden in the process. If you have large models, this can help you to compute your sweep more efficiently because you don’t need the full posterior to get the estimate. A random subsmaple of the posterior should be enough if your posterior has not longer tails or skewness.
ref_value = (
mmm.idata.posterior.channel_contribution.sum(["channel", "date"])
.mean(["chain", "draw"])
.item()
)
mmm.sensitivity.compute_uplift_curve_respect_to_base(
results=mmm.idata.sensitivity_analysis["x"],
ref=ref_value,
extend_idata=True,
)
mmm.sensitivity.compute_marginal_effects(
results=mmm.idata.sensitivity_analysis["uplift_curve"], extend_idata=True
)
_ = mmm.plot.uplift_curve(
aggregation={"sum": ("channel",)},
xlabel="Sweep additive",
ylabel="Total uplift respect to historical contribution",
)
_ = mmm.plot.marginal_curve(aggregation={"sum": ("channel",)}, xlabel="Sweep additive");
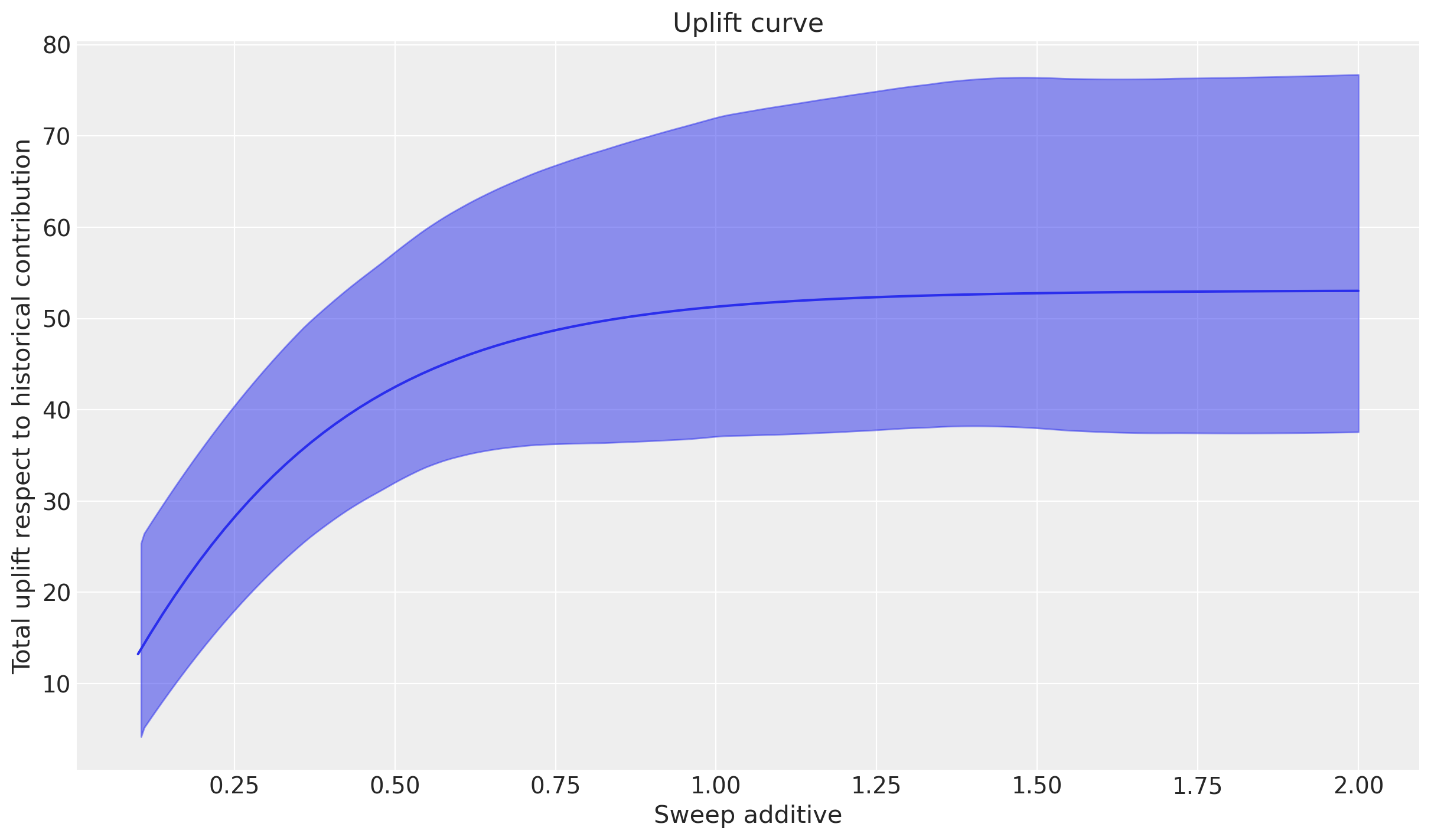
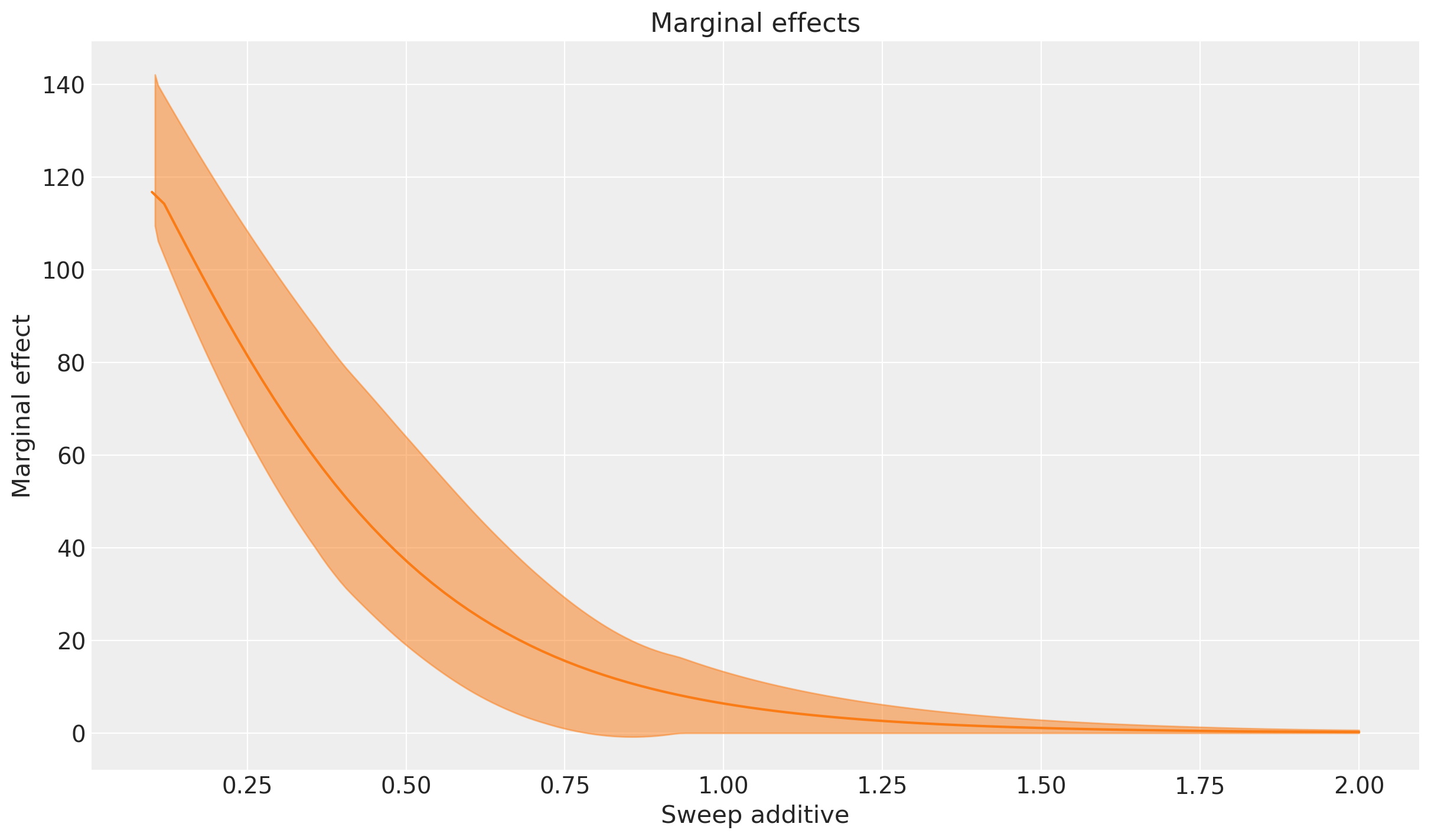
Estos gráficos muestran el aumento esperado y los efectos marginales. Obtenemos un patrón general de resultados similar: si consideramos escenarios en los que hemos gastado progresivamente más, obtendríamos un aumento positivo, pero a medida que alcanzamos un cierto nivel de gasto, el canal publicitario se satura y los efectos marginales caen cerca de cero.
Análisis de sensibilidad sobre el umbral de envío gratuito#
Hemos examinado detenidamente la variable de gasto en influencers y hemos obtenido algunas ideas interesantes sobre cómo afecta el resultado (ventas) en diferentes escenarios contrafactuales.
Pero también podemos hacer lo mismo para el controlador del umbral de envío gratuito. La razón por la que esto es interesante en nuestro ejemplo es porque se asume que este controlador tiene efectos lineales en el resultado, sin que se aplique ninguna función de saturación o adstock.
No vamos a repasar exhaustivamente todos los diferentes barridos que podemos realizar, pero solo demostraremos un barrido absoluto.
mmm.sensitivity.run_sweep(
sweep_values=sweeps,
var_input="control_data",
var_names="control_contribution",
sweep_type="absolute",
extend_idata=True,
);
Because we make the sweep for all variables in the control contribution container, then we can plot actually all of them automatically. In this case, we have trend and shipping_threshold.
ref_value = mmm.idata.posterior.control_contribution.sum(["date"]).mean(
["chain", "draw"]
)
mmm.sensitivity.compute_uplift_curve_respect_to_base(
results=mmm.idata.sensitivity_analysis["x"],
ref=ref_value,
extend_idata=True,
)
mmm.sensitivity.compute_marginal_effects(
results=mmm.idata.sensitivity_analysis["uplift_curve"], extend_idata=True
)
_ = mmm.plot.uplift_curve(
subplot_kwargs={"figsize": (16, 8)},
xlabel="Sweep absolute",
ylabel="Total uplift respect to historical contribution",
)
_ = mmm.plot.marginal_curve(
subplot_kwargs={"figsize": (16, 8)}, xlabel="Sweep absolute"
);
/Users/carlostrujillo/Documents/GitHub/pymc-marketing/pymc_marketing/mmm/plot.py:1717: UserWarning: The figure layout has changed to tight
fig.tight_layout()
/Users/carlostrujillo/Documents/GitHub/pymc-marketing/pymc_marketing/mmm/plot.py:1717: UserWarning: The figure layout has changed to tight
fig.tight_layout()
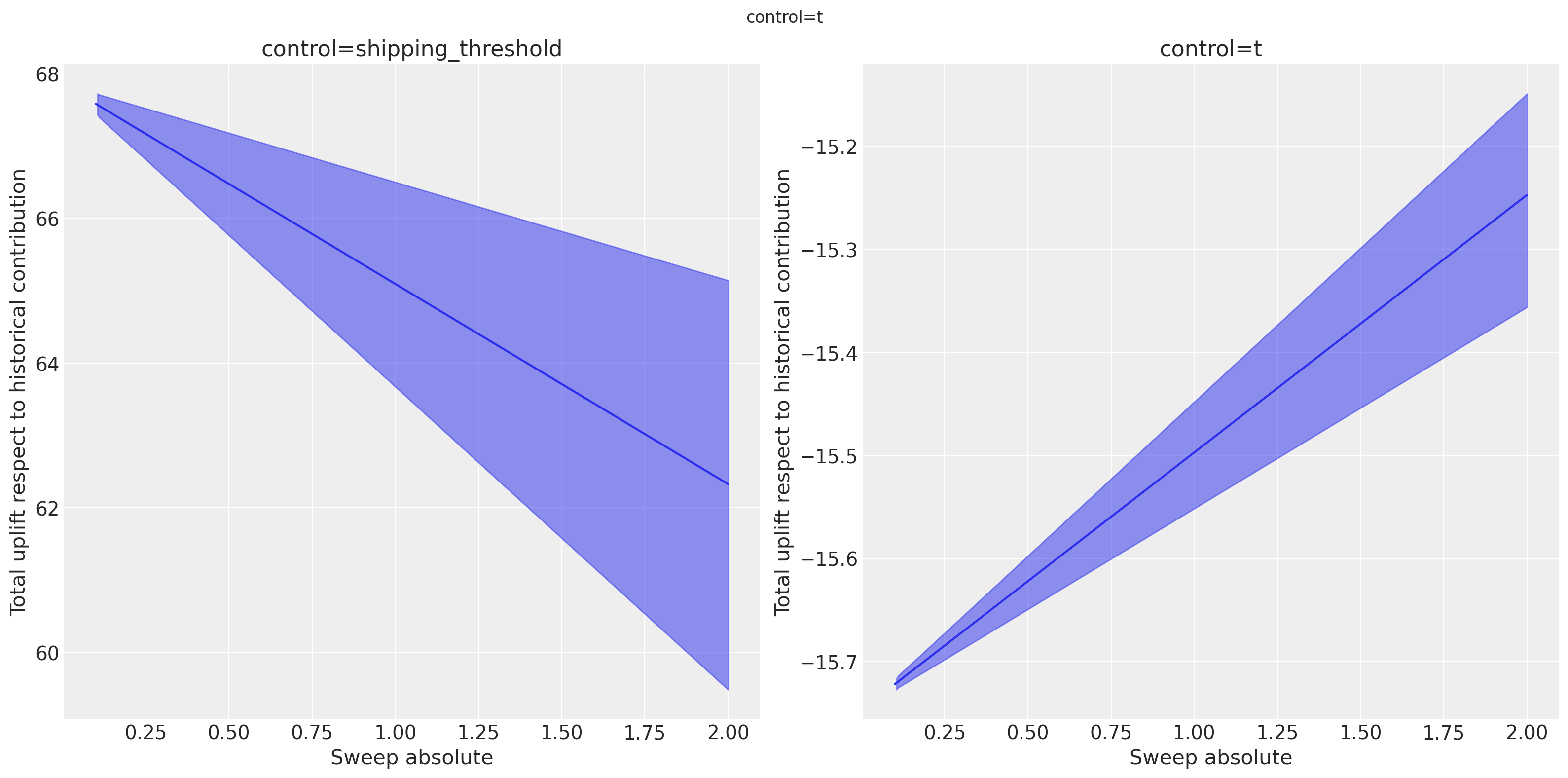
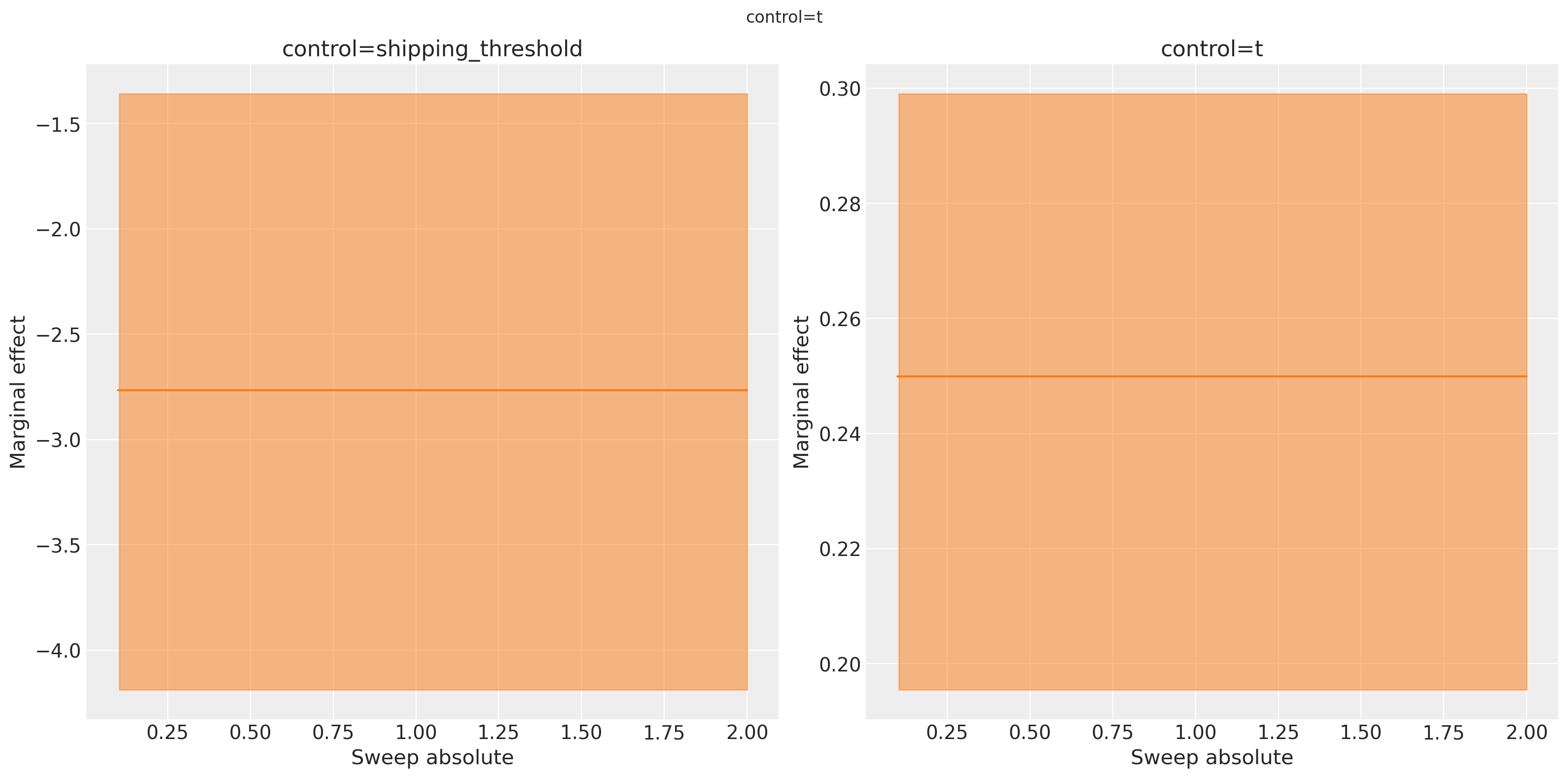
We can select only one and plot as well if thats what we want.
ref_value = (
mmm.idata.posterior.control_contribution.sel(control="shipping_threshold")
.sum(["date"])
.mean(["chain", "draw"])
)
mmm.sensitivity.compute_uplift_curve_respect_to_base(
results=mmm.idata.sensitivity_analysis["x"].sel(control="shipping_threshold"),
ref=ref_value,
extend_idata=True,
)
mmm.sensitivity.compute_marginal_effects(
results=mmm.idata.sensitivity_analysis["uplift_curve"], extend_idata=True
)
_ = mmm.plot.uplift_curve(
subplot_kwargs={"figsize": (16, 8)},
xlabel="Sweep absolute",
ylabel="Total uplift respect to historical contribution",
)
_ = mmm.plot.marginal_curve(
subplot_kwargs={"figsize": (16, 8)}, xlabel="Sweep absolute"
);
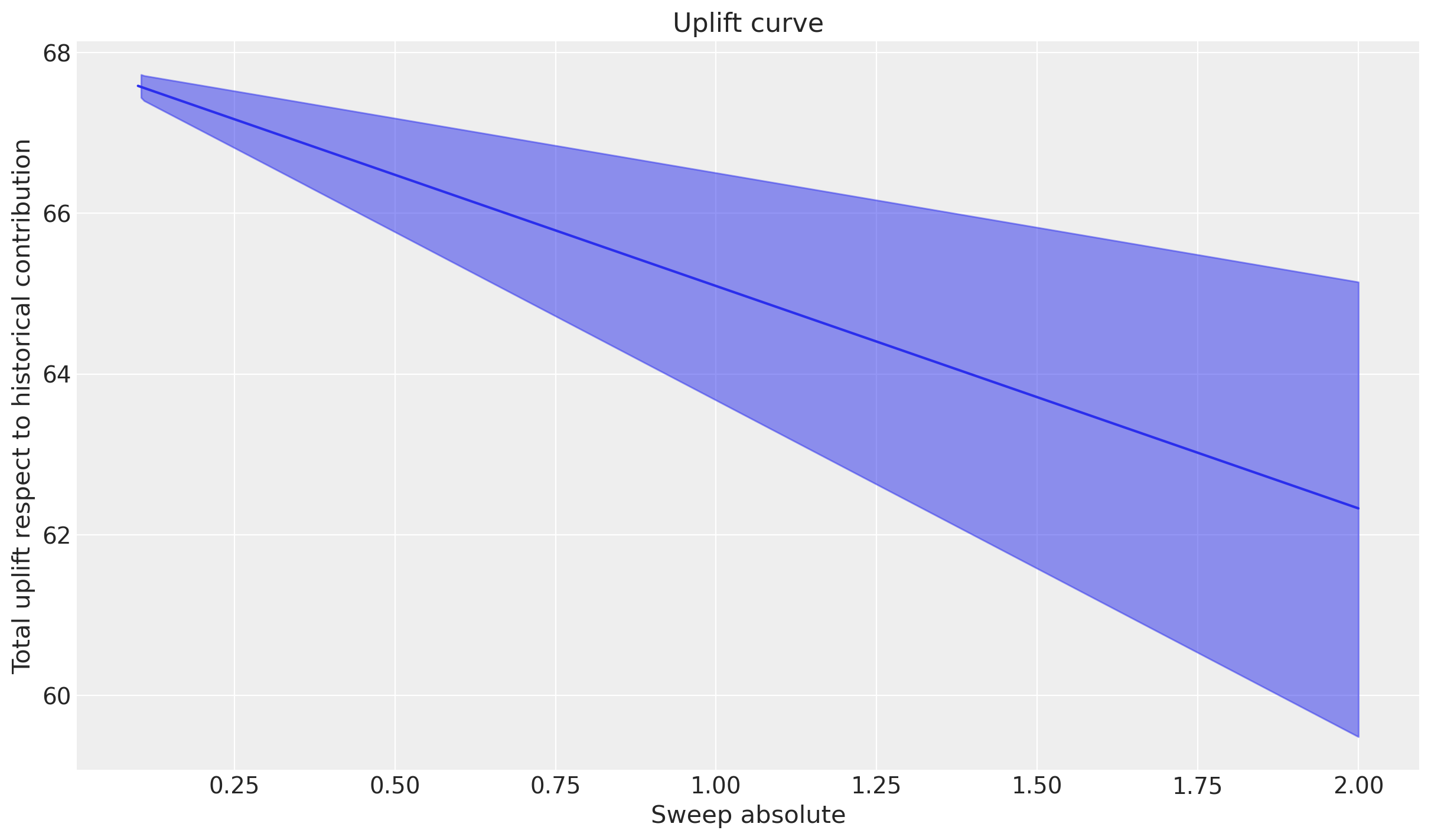
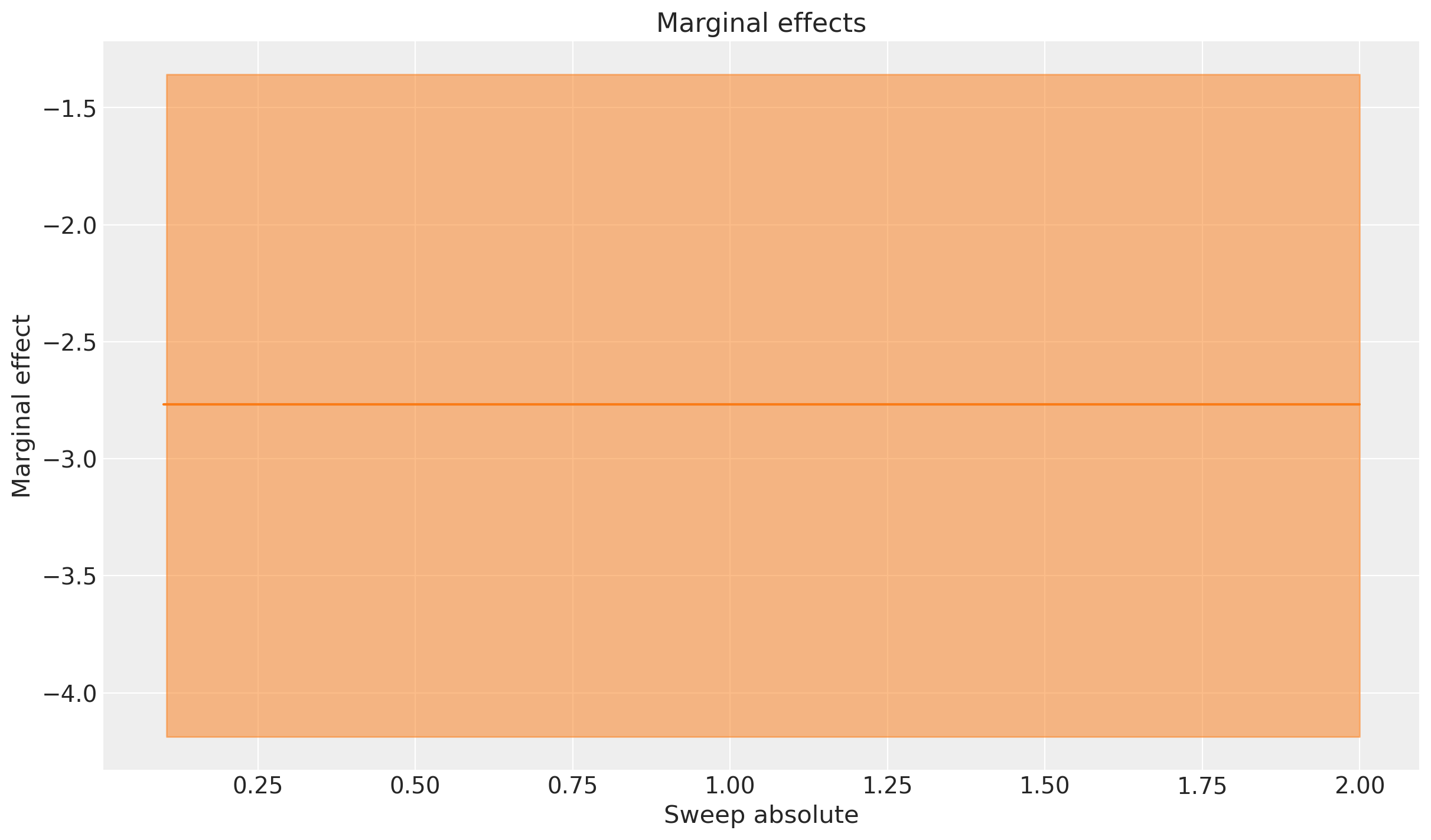
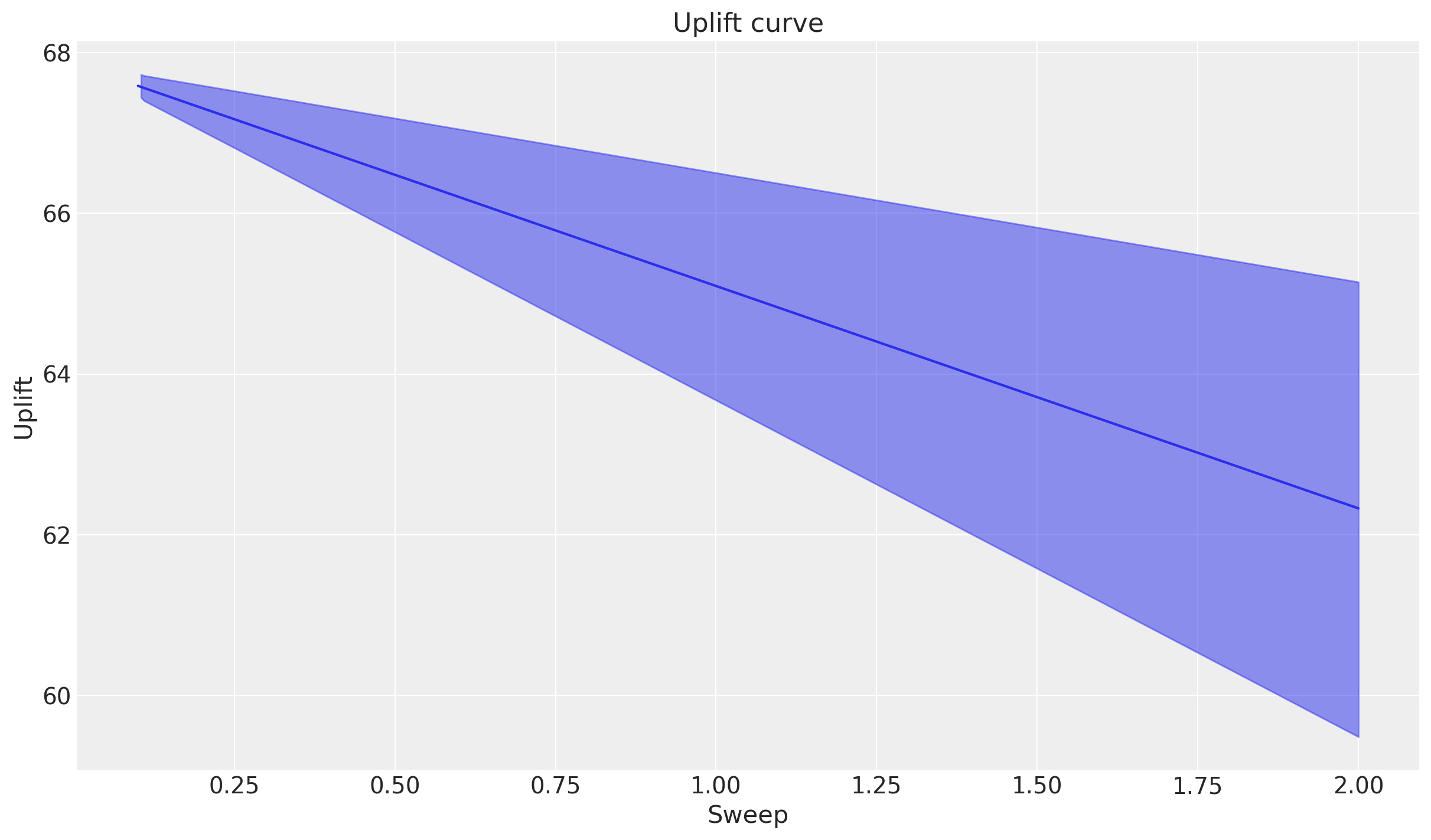
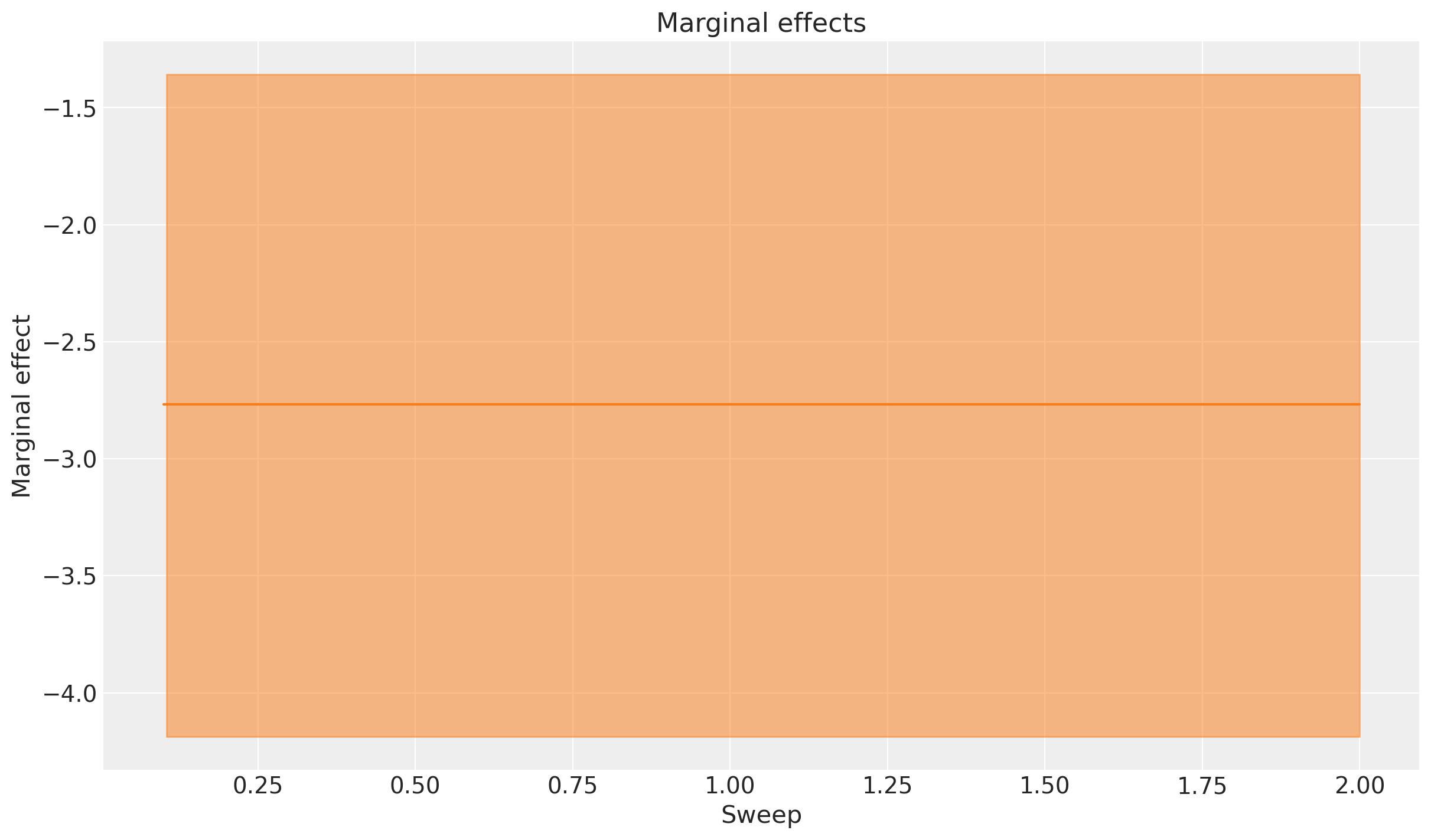
Podemos observar la naturaleza lineal de los efectos del umbral de envío gratuito en la variable de resultado. El aumento esperado es positivo cuando disminuimos el umbral (las personas compran más cuando el envío es gratuito), y los efectos marginales son constantes a lo largo de los valores de barrido. Esto se debe a que asumimos una relación lineal entre el umbral de envío gratuito y las ventas, por lo que el efecto marginal no cambia a medida que ajustamos el umbral. El valor negativo constante es igual al cambio en el aumento a medida que incrementamos el umbral de envío en $1.
Podemos verificar esto cambiando el tamaño del paso de barrido y observando que obtenemos estimaciones de efectos marginales idénticas (aunque con error de estimación numérica).
mmm.sensitivity.run_sweep(
sweep_values=sweeps,
var_input="control_data",
var_names="control_contribution",
sweep_type="absolute",
extend_idata=True,
);
ref_value = (
mmm.idata.posterior.control_contribution.sel(control="shipping_threshold")
.sum(["date"])
.mean(["chain", "draw"])
.item()
)
mmm.sensitivity.compute_uplift_curve_respect_to_base(
results=mmm.idata.sensitivity_analysis["x"].sel(control="shipping_threshold"),
ref=ref_value,
extend_idata=True,
)
mmm.sensitivity.compute_marginal_effects(
results=mmm.idata.sensitivity_analysis["uplift_curve"], extend_idata=True
)
_ = mmm.plot.uplift_curve(aggregation={"sum": ("channel",)})
_ = mmm.plot.marginal_curve(aggregation={"sum": ("channel",)});
Truco
¿Por qué debería interesarme en una línea recta y una línea plana? Estos son los tipos de gráficos que puede utilizar para verificar si el modelo se comporta como se esperaba.
Quizás usted (o un cliente) se da cuenta de que una relación lineal negativa entre el umbral de envío y las ventas es demasiado simplista. Esto puede impulsar la iteración y mejora del modelo; por ejemplo, podría explorar formas funcionales alternativas.
Resumen#
Hemos introducido una herramienta simple pero poderosa para profundizar en sus resultados de MMM. Puede explorar una serie de perturbaciones en una o más variables de control y calcular los resultados esperados y los efectos marginales para cada escenario. Puede considerar diferentes formas de perturbación; aquí hemos mostrado barridos multiplicativos, absolutos y aditivos.
Esto le permite responder preguntas de «qué pasaría si» con precisión y claridad, proporcionando información útil sobre cómo diferentes palancas afectan los resultados de su negocio. Puede producir gráficos simples e interpretables que puede utilizar para comunicar cómo funciona el modelo y obtener verificaciones de sentido sobre el comportamiento y las suposiciones del modelo.
%load_ext watermark
%watermark -n -u -v -iv -w -p pymc_marketing,pytensor
Last updated: Mon Oct 27 2025
Python implementation: CPython
Python version : 3.12.11
IPython version : 9.6.0
pymc_marketing: 0.16.0
pytensor : 2.31.7
pymc_marketing: 0.16.0
graphviz : 0.21
arviz : 0.22.0
matplotlib : 3.10.6
numpy : 2.3.3
pandas : 2.3.3
Watermark: 2.5.0