Midiendo el impacto en la parte superior del embudo con PyMC‑Marketing#
Este cuaderno es una guía práctica y completa para cuantificar el impacto de los canales de embudo superior en un resultado comercial posterior utilizando Modelado de Mezcla de Marketing Bayesiano (MMM). Combinaremos un DAG causal, un proceso generador de datos transparente y una implementación de PyMC-Marketing que respeta las dinámicas temporales (adstock) y la respuesta no lineal (saturación). El énfasis está en el razonamiento causal primero, el modelado segundo.
Lo que construirás (a simple vista)#
Un PyMC-Marketing MMM con Adstock Geométrico y saturación Michaelis–Menten para el resultado.
Un modelo de mediador que vincula la actividad de la parte superior del embudo con la exposición posterior.
Un estimador de efectos basado en simulaciones que convierte los cambios de «qué pasaría si» en la parte superior del embudo en deltas de resultados, con incertidumbre.
Por qué esto es importante#
Las señales de embudo superior rara vez actúan de manera instantánea o directa sobre nuestra variable objetivo. Tratarles como características simples en una única regresión colapsa la mediación, ignora el arrastre y oscurece el punto operativo donde residen los rendimientos marginales. Un MMM causal-prioritario aclara dónde se originan los efectos.
Para quién es esto#
Analistas y científicos de datos que necesitan una forma defendible de atribuir inversiones en la parte superior del embudo a resultados, y que se sienten cómodos con la inferencia bayesiana, la estructura de series temporales y diagramas causales básicos.
Al final, tendrás una plantilla repetible para responder a la “pregunta eterna” de la medición en la parte superior del embudo, no pidiendo a MMM que lo haga todo, sino alineando MMM con tu comprensión causal del sistema de marketing.
Lo que cubre este cuaderno#
Enmarcando el problema: Por qué la medición en la parte superior del embudo es difícil y cómo las regresiones ingenuas atribuyen erróneamente el aumento.
Andamiaje causal: Un DAG mínimo que separa conductores, mediadores y resultados, aclarando lo que significa el efecto total.
Modelado de respuesta dinámica: Cómo el adstock (arrastre) y la saturación (rendimientos decrecientes) moldean el rendimiento observable.
Two-block estimation strategy:
Un bloque de mediador para traducir los cambios en la parte superior del embudo en impresiones en la parte inferior del embudo.
Un bloque de resultados para traducir esas impresiones en impacto empresarial.
Pensamiento contrafactual: Convertir intervenciones en canales de embudo superior en cambios predichos en el resultado (g-cálculo).
Verificación de modelos: Comprobaciones predictivas posteriores y pruebas de cordura que previenen la autoengaño.
Efectos de informes: Respuestas al impulso, aumento acumulativo y elasticidades dependientes del estado que los tomadores de decisiones pueden utilizar.
Business Challenge: Untangling Upper → Mid → Lower Funnel Effects#
Una marca de consumo invierte fuertemente en la concienciación (video, influencers, relaciones públicas). La dirección observa que las ventas a corto plazo se estancan y pregunta: “¿Están nuestros dólares de la parte superior del embudo haciendo algo?” Los paneles de control estándar muestran relaciones contemporáneas débiles, y los equipos de canal argumentan que “todo se recupera más tarde.” Necesitamos una forma defendible de cuantificar cómo la exposición en la parte superior del embudo se propaga a través del compromiso en la parte media del embudo hasta las conversiones en la parte inferior del embudo—sin depender únicamente de sentimientos u opiniones.
Comenzamos esbozando el mundo en el que creemos que operamos: una pequeña historia causal que guiará cada decisión de modelado que siga.

El ecosistema basado en el DAG causal#
El DAG anterior muestra tres tipos de efectos sobre él.
\(X1\) Parte superior del embudo (Impresiones de conocimiento): Medios de amplio alcance (por ejemplo, video en línea, display, ráfagas de influencers). Genera consideración latente y memoria de marca, no compras inmediatas.
\(X2\) & \(X3\) Mid funnel (Consideration touchpoints):
\(X2\): Social media impressions / site landings (people start looking).
\(X3\): Impresiones de remarketing (personas que vuelven a involucrarse después de un primer contacto). Estos son mediadores—traducen la conciencia en una intención accionable.
\(X4\) Embudo inferior (Exposiciones de alta intención): Búsqueda de marca. Estos son los impulsores proximales del resultado comercial.
U1, U4 Choques exógenos: Los movimientos de los competidores, los presupuestos asignados a los equipos o los cambios en la dinámica del mercado pueden perturbar cada nodo por separado.
Los MMM tradicionales a menudo combinan todos los canales en una sola regresión y buscan un ajuste global. Para los canales de la parte superior del embudo, ese enfoque puede:
Subcrédito X1 (porque su efecto es indirecto y retrasado)
Sobreajustar a X4 (porque es el más cercano al resultado)
Las Preguntas Empresariales#
Q1. ¿Cuánto cambia un cambio marginal en conciencia (X1) el resultado, a través del embudo?
Q2. ¿Dónde estamos en la curva de respuesta (¿estamos cerca de la saturación)?
Q3. ¿Cuál es el incremento acumulado esperado de una campaña planificada en la parte superior del embudo?
Nevertheless solve those business questions will not be easy if you don’t know anything about causality, as soon you will learn.
Imports#
Trabajaremos con PyMC-Marketing para los componentes de MMM, ArviZ para diagnósticos y Pytensor para mantener nuestro simulador honesto.
import warnings
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import preliz as pz
import pytensor.xtensor as ptx
import xarray as xr
from pymc_extras.prior import Censored, Prior
from pymc_marketing.mmm import (
GeometricAdstock,
MichaelisMentenSaturation,
NoAdstock,
NoSaturation,
)
from pymc_marketing.mmm.multidimensional import MMM
Notebook settings#
Para mantener las cifras consistentes y las ejecuciones reproducibles, bloqueamos una semilla y un estilo de trazado.
SEED = 142
n_observations = 1050
rng = np.random.default_rng(SEED)
warnings.filterwarnings("ignore")
# Set the style
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [8, 4]
plt.rcParams["figure.dpi"] = 100
plt.rcParams["axes.labelsize"] = 6
plt.rcParams["xtick.labelsize"] = 6
plt.rcParams["ytick.labelsize"] = 6
%config InlineBackend.figure_format = "retina"
Data generation process#
Basado en el DAG anterior, comenzaremos a simular datos utilizando pytensor; durante la simulación necesitaremos indicar cómo se representan las relaciones precisas (flechas entre nodos) y, como consecuencia, entenderlas por el modelo.
Aquí, asumiremos un modelo completamente aditivo y entenderemos las interacciones entre canales como modelos aditivos también; por consecuencia, la ecuación causal estructural que se construirá será:
Data generation process#
Basado en el DAG anterior, simularemos datos en pytensor. Hacemos que las relaciones sean aditivas en cada nodo y permitimos una respuesta no lineal solo en el mapeo final de la exposición de embudo inferior al resultado. El tiempo está indexado por \(t=1,\dots,T\).
Structural causal equations#
Let \(X_1\) (upper funnel), \(X_2,X_3\) (mid funnel), \(X_4\) (lower funnel), \(E_t\) (event), and \(Y\) (business outcome). Exogenous shocks \(U_j\) enter additively.
\(\mu_{j,t}\) son los componentes exógenos de las impresiones (por ejemplo: aquellos cambios que no dependen de otros nodos).
Outcome variable#
Sea \(f(\cdot)\) la función de respuesta no lineal (por ejemplo, Geometric Adstock, Michaelis–Menten). El resultado combina la presión transformada del embudo inferior con controles aditivos:
\(\text{Trend}_t\): smooth baseline evolution.
\(\text{Events}_t\): superposición de funciones base de eventos localizados.
\(\theta\): parámetros de la función de respuesta no lineal (por ejemplo, saturación/adstock).
Resumen: Asumimos una estructura aditiva en cada nodo, mediación lineal \(X_1\!\to\!(X_2,X_3)\!\to\!X_4\), transferencia dinámica en \(X_4\) a través de adstock, y un mapeo no lineal \(f\) de la exposición adstocked a \(Y\), además de una tendencia/eventos aditivos y ruido.
Nuestra historia se desarrolla día a día; creamos una línea de tiempo diaria con algunas características de calendario simples.
min_date = pd.to_datetime("2022-01-01")
max_date = min_date + pd.Timedelta(days=n_observations)
date_range = pd.date_range(start=min_date, end=max_date, freq="D")
df = pd.DataFrame(data={"date_week": date_range}).assign(
year=lambda x: x["date_week"].dt.year,
month=lambda x: x["date_week"].dt.month,
dayofyear=lambda x: x["date_week"].dt.dayofyear,
)
Using PyTensor, we can symbolically represent the causal Directed Acyclic Graph (DAG) in an abstract way before diving into any actual computation.
Truco
What is PyTensor?
PyTensor is a Python library that allows one to define, optimize, and efficiently evaluate mathematical expressions involving multi-dimensional arrays. It provides the computational backend for PyMC.
In essence, PyTensor allow us to define static computational graphs, that can be compiled into different backends, like Numba or JAX.
This framework allows us to clearly define the relationships that our data generation process must adhere to. PyTensor simplifies this task and enables us to visualize the resulting graphical model—though it’s a computational DAG rather than a causal one—helping us to confirm that the entire process aligns with our expectations.
# Trend
trend = ptx.xtensor("trend", dims=("date",))
# Noise
global_noise = ptx.xtensor("global_noise", dims=("date",))
# Events
pt_event_signal = ptx.xtensor("event_signal", dims=("date",)) # raw signal
pt_event_contributions = ptx.xtensor(
"event_contributions", dims=("date",)
) # contribution to y
# Outcome
y = trend + global_noise + pt_event_contributions
y.dprint();
Add [id A]
├─ Add [id B]
│ ├─ trend [id C]
│ └─ global_noise [id D]
└─ event_contributions [id E]
Echemos un vistazo rápido al gráfico computacional para no engañarnos: los ingredientes se combinan exactamente como se pretende. A continuación, anotamos cómo la conciencia se transforma en consideración y luego en exposiciones de alta intención. Estos vínculos son simples—por diseño—para que podamos centrarnos en la ruta causal en lugar de ajustar curvas.
beta_event_x1 = ptx.xtensor("beta_event_x1", dims=())
e_x1 = ptx.xtensor("e_x1", dims=("date",))
impressions_x1 = (
ptx.xtensor("impressions_x1", dims=("date",))
+ (pt_event_signal * beta_event_x1)
+ e_x1
)
beta_x1_x2 = ptx.xtensor("beta_x1_x2", dims=())
beta_x1_x3 = ptx.xtensor("beta_x1_x3", dims=())
e_x2 = ptx.xtensor("e_x2", dims=("date",))
e_x3 = ptx.xtensor("e_x3", dims=("date",))
impressions_x2 = (
ptx.xtensor("impressions_x2", dims=("date",)) + (impressions_x1 * beta_x1_x2) + e_x2
)
impressions_x3 = (
ptx.xtensor("impressions_x3", dims=("date",)) + (impressions_x1 * beta_x1_x3) + e_x3
)
beta_x2_x4 = ptx.xtensor("beta_x2_x4", dims=())
beta_x3_x4 = ptx.xtensor("beta_x3_x4", dims=())
e_x4 = ptx.xtensor("e_x4", dims=("date",))
impressions_x4 = (
ptx.xtensor("impressions_x4", dims=("date",))
+ (impressions_x2 * beta_x2_x4)
+ (impressions_x3 * beta_x3_x4)
+ e_x4
)
impressions_x4.dprint();
Add [id A]
├─ Add [id B]
│ ├─ Add [id C]
│ │ ├─ impressions_x4 [id D]
│ │ └─ Mul [id E]
│ │ ├─ Add [id F]
│ │ │ ├─ Add [id G]
│ │ │ │ ├─ impressions_x2 [id H]
│ │ │ │ └─ Mul [id I]
│ │ │ │ ├─ Add [id J]
│ │ │ │ │ ├─ Add [id K]
│ │ │ │ │ │ ├─ impressions_x1 [id L]
│ │ │ │ │ │ └─ Mul [id M]
│ │ │ │ │ │ ├─ event_signal [id N]
│ │ │ │ │ │ └─ ExpandDims{axis=0} [id O]
│ │ │ │ │ │ └─ beta_event_x1 [id P]
│ │ │ │ │ └─ e_x1 [id Q]
│ │ │ │ └─ ExpandDims{axis=0} [id R]
│ │ │ │ └─ beta_x1_x2 [id S]
│ │ │ └─ e_x2 [id T]
│ │ └─ ExpandDims{axis=0} [id U]
│ │ └─ beta_x2_x4 [id V]
│ └─ Mul [id W]
│ ├─ Add [id X]
│ │ ├─ Add [id Y]
│ │ │ ├─ impressions_x3 [id Z]
│ │ │ └─ Mul [id BA]
│ │ │ ├─ Add [id J]
│ │ │ │ └─ ···
│ │ │ └─ ExpandDims{axis=0} [id BB]
│ │ │ └─ beta_x1_x3 [id BC]
│ │ └─ e_x3 [id BD]
│ └─ ExpandDims{axis=0} [id BE]
│ └─ beta_x3_x4 [id BF]
└─ e_x4 [id BG]
Creando los datos para nuestros marcadores de posición simbólicos.#
Primero, comenzamos a llenar los valores para nuestras variables de evento y tendencia. Luego, creamos una línea base que sube suavemente, añadimos pulsos de evento gaussianos y agregamos un susurro de ruido.
Colocamos las piezas antes de mezclarlas.
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(pz_global_noise, label="Global Noise")
ax.plot(np_trend, label="Trend")
ax.plot(np_event_signal, label="Event Contributions")
ax.set_title("Components of the Time Series Model")
ax.set_xlabel("Time (days)")
ax.set_ylabel("Value")
ax.legend(loc="center left", bbox_to_anchor=(1, 0.5))
ax.grid(True, alpha=0.3)
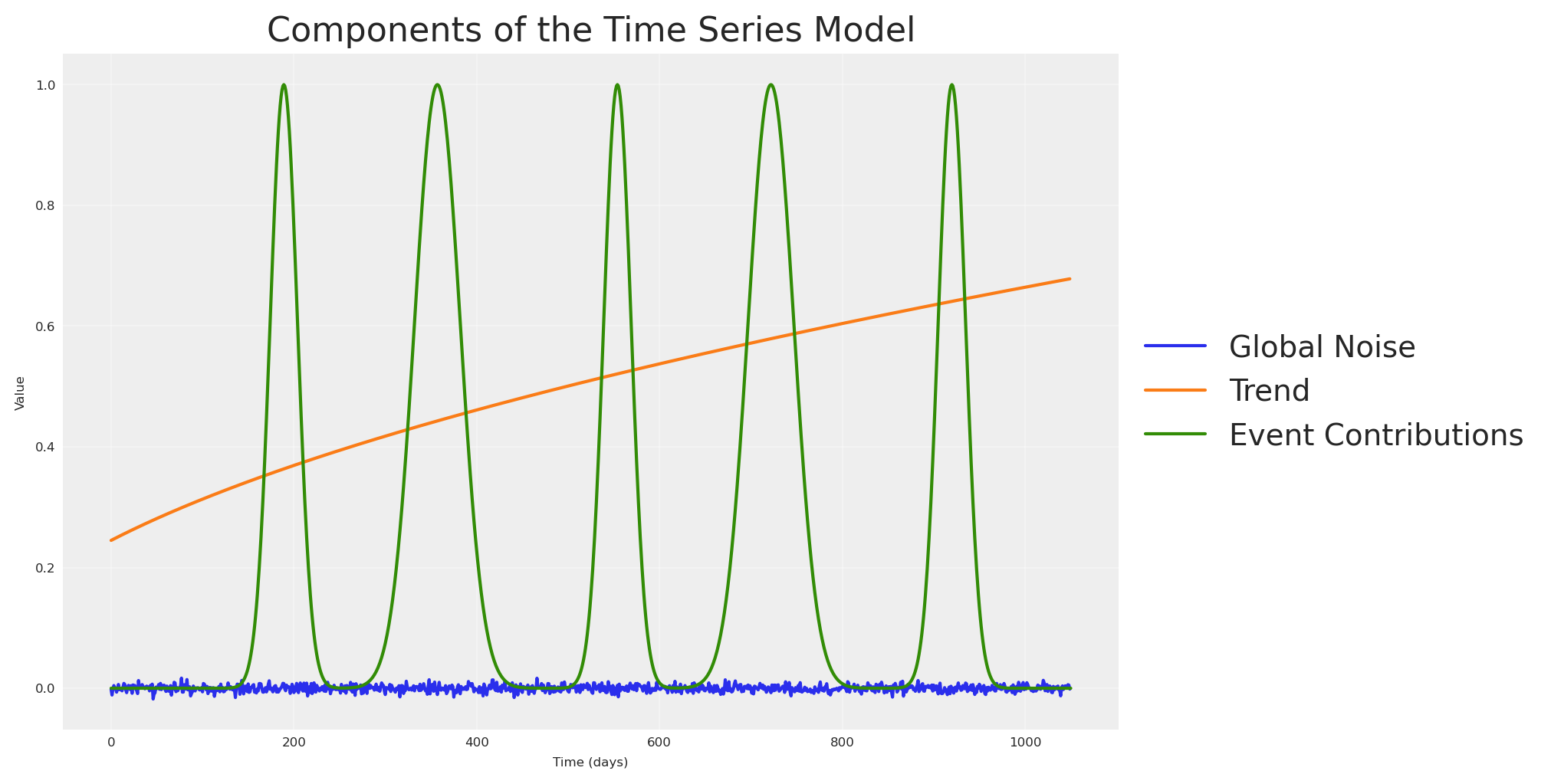
Simularemos nuestras variables de medios (por ejemplo: Impresiones) como caminatas aleatorias. Las exposiciones en la parte superior, media e inferior del embudo no suelen saltar aleatoriamente; se deslizan alrededor de un valor consistente. Una caminata aleatoria acotada captura esa inercia.
Dejamos que cada flujo deambule dentro de los límites y eche un primer vistazo al comportamiento.
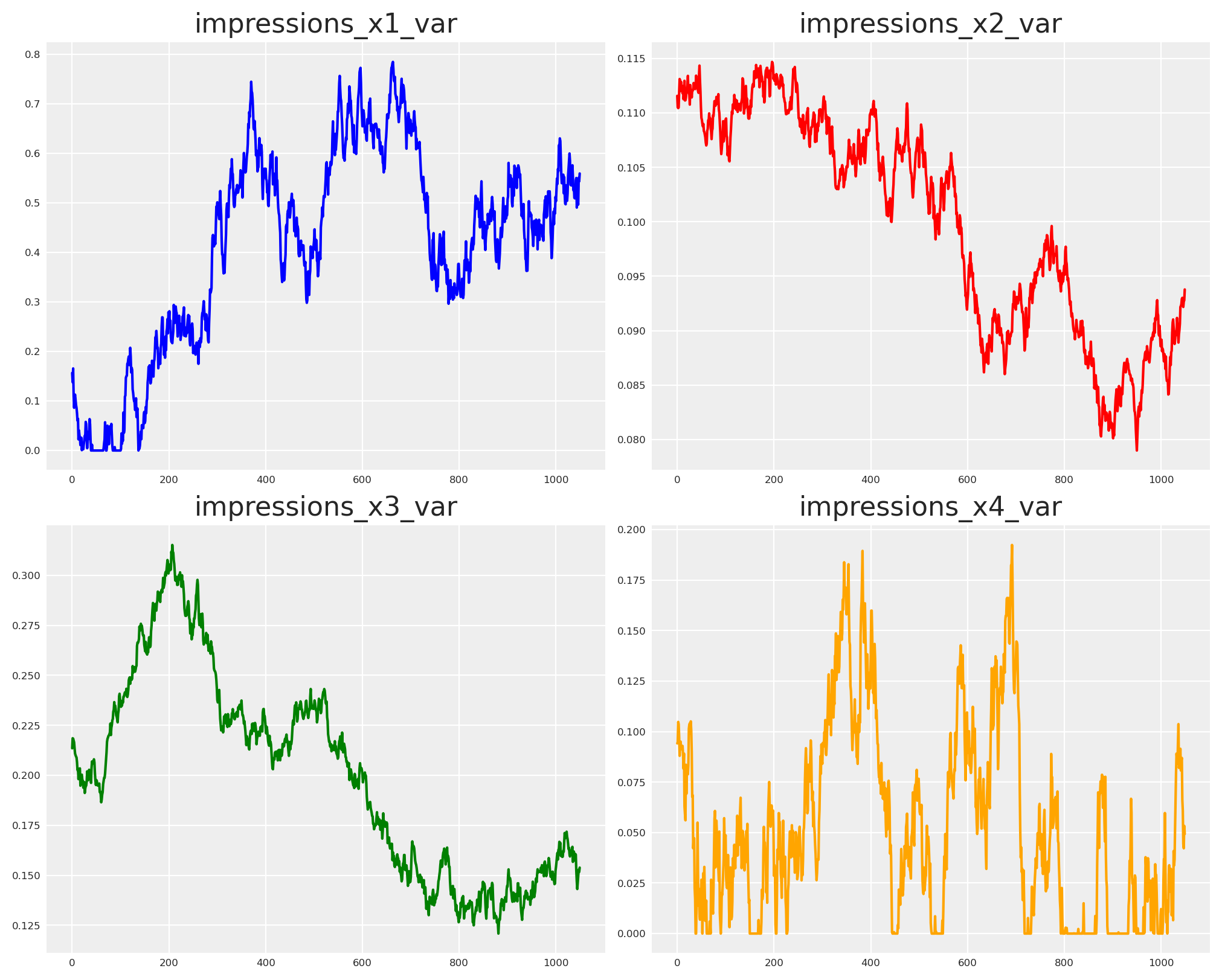
Ahora, necesitamos definir la fuerza de las relaciones, esas serán las betas de cada variable sobre las otras. Al hacerlo, podemos crear todos los nodos que faltan.
Solo X4 alcanza el resultado en nuestra historia. Ahí es donde añadimos memoria (adstock) y rendimientos decrecientes (saturación).
fig, axs = plt.subplots(2, 2, figsize=(10, 8))
axs[0, 0].plot(impressions_x1_eval, color="blue")
axs[0, 0].set_title("impressions_x1_eval")
axs[0, 1].plot(impressions_x2_eval, color="red")
axs[0, 1].set_title("impressions_x2_eval")
axs[1, 0].plot(impressions_x3_eval, color="green")
axs[1, 0].set_title("impressions_x3_eval")
axs[1, 1].plot(impressions_x4_eval, color="orange")
axs[1, 1].set_title("impressions_x4_eval");
# Creating forward pass for impressions
def forward_pass(x, adstock_alpha, saturation_lam, saturation_alpha):
# return type pytensor.xtensor.type.XTensorVariable
return MichaelisMentenSaturation.function(
MichaelisMentenSaturation,
x=GeometricAdstock(l_max=24, normalize=False).function(
x=x,
alpha=adstock_alpha,
dim="date",
),
lam=saturation_lam,
alpha=saturation_alpha,
)
x4_sat_lam = 0.2
x4_sat_alpha = 0.7
x4_adstock_alpha = 0.3
x4_sat_lam_scalar = ptx.xtensor("x4_sat_lam", dims=())
x4_sat_alpha_scalar = ptx.xtensor("x4_sat_alpha", dims=())
x4_adstock_alpha_scalar = ptx.xtensor("x4_adstock_alpha", dims=())
# Apply forward pass to impressions
impressions_x4_forward = forward_pass(
ptx.as_xtensor(impressions_x4, dims=("date",)),
x4_adstock_alpha_scalar,
x4_sat_lam_scalar,
x4_sat_alpha_scalar,
)
y += impressions_x4_forward
y.dprint();
Add [id A]
├─ Add [id B]
│ ├─ Add [id C]
│ │ ├─ trend [id D]
│ │ └─ global_noise [id E]
│ └─ event_contributions [id F]
└─ True_div [id G]
├─ Mul [id H]
│ ├─ ExpandDims{axis=0} [id I]
│ │ └─ x4_sat_alpha [id J]
│ └─ Blockwise{Convolve1d, (n0),(k0),()->(o0)} [id K]
│ ├─ Join [id L]
│ │ ├─ 0 [id M]
│ │ ├─ Alloc [id N]
│ │ │ ├─ 0.0 [id O]
│ │ │ └─ Sub [id P]
│ │ │ ├─ Subtensor{i} [id Q]
│ │ │ │ ├─ Shape [id R]
│ │ │ │ │ └─ Pow [id S]
│ │ │ │ │ ├─ ExpandDims{axis=0} [id T]
│ │ │ │ │ │ └─ Check{0 <= alpha <= 1} [id U]
│ │ │ │ │ │ ├─ x4_adstock_alpha [id V]
│ │ │ │ │ │ └─ ScalarFromTensor [id W]
│ │ │ │ │ │ └─ All{axes=None} [id X]
│ │ │ │ │ │ └─ MakeVector{dtype='bool'} [id Y]
│ │ │ │ │ │ └─ All{axes=None} [id Z]
│ │ │ │ │ │ └─ MakeVector{dtype='bool'} [id BA]
│ │ │ │ │ │ ├─ Ge [id BB]
│ │ │ │ │ │ │ ├─ x4_adstock_alpha [id V]
│ │ │ │ │ │ │ └─ 0 [id BC]
│ │ │ │ │ │ └─ Le [id BD]
│ │ │ │ │ │ ├─ x4_adstock_alpha [id V]
│ │ │ │ │ │ └─ 1 [id BE]
│ │ │ │ │ └─ ARange{dtype='float64'} [id BF]
│ │ │ │ │ ├─ 0 [id BG]
│ │ │ │ │ ├─ 24 [id BH]
│ │ │ │ │ └─ 1 [id BI]
│ │ │ │ └─ -1 [id BJ]
│ │ │ └─ 1 [id BK]
│ │ └─ Add [id BL]
│ │ ├─ Add [id BM]
│ │ │ ├─ Add [id BN]
│ │ │ │ ├─ impressions_x4 [id BO]
│ │ │ │ └─ Mul [id BP]
│ │ │ │ ├─ Add [id BQ]
│ │ │ │ │ ├─ Add [id BR]
│ │ │ │ │ │ ├─ impressions_x2 [id BS]
│ │ │ │ │ │ └─ Mul [id BT]
│ │ │ │ │ │ ├─ Add [id BU]
│ │ │ │ │ │ │ ├─ Add [id BV]
│ │ │ │ │ │ │ │ ├─ impressions_x1 [id BW]
│ │ │ │ │ │ │ │ └─ Mul [id BX]
│ │ │ │ │ │ │ │ ├─ event_signal [id BY]
│ │ │ │ │ │ │ │ └─ ExpandDims{axis=0} [id BZ]
│ │ │ │ │ │ │ │ └─ beta_event_x1 [id CA]
│ │ │ │ │ │ │ └─ e_x1 [id CB]
│ │ │ │ │ │ └─ ExpandDims{axis=0} [id CC]
│ │ │ │ │ │ └─ beta_x1_x2 [id CD]
│ │ │ │ │ └─ e_x2 [id CE]
│ │ │ │ └─ ExpandDims{axis=0} [id CF]
│ │ │ │ └─ beta_x2_x4 [id CG]
│ │ │ └─ Mul [id CH]
│ │ │ ├─ Add [id CI]
│ │ │ │ ├─ Add [id CJ]
│ │ │ │ │ ├─ impressions_x3 [id CK]
│ │ │ │ │ └─ Mul [id CL]
│ │ │ │ │ ├─ Add [id BU]
│ │ │ │ │ │ └─ ···
│ │ │ │ │ └─ ExpandDims{axis=0} [id CM]
│ │ │ │ │ └─ beta_x1_x3 [id CN]
│ │ │ │ └─ e_x3 [id CO]
│ │ │ └─ ExpandDims{axis=0} [id CP]
│ │ │ └─ beta_x3_x4 [id CQ]
│ │ └─ e_x4 [id CR]
│ ├─ Pow [id S]
│ │ └─ ···
│ └─ TensorFromScalar [id CS]
│ └─ False [id CT]
└─ Add [id CU]
├─ ExpandDims{axis=0} [id CV]
│ └─ x4_sat_lam [id CW]
└─ Blockwise{Convolve1d, (n0),(k0),()->(o0)} [id K]
└─ ···
Con todo en su lugar, podemos evaluar la variable objetivo.
# Eval target_var and plot
target_var_eval = y.eval(
{
"impressions_x1": impressions_x1_var,
"event_signal": np_event_signal[:-1],
"beta_event_x1": beta_event_x1_var,
"e_x1": e_x1_var,
"e_x2": e_x2_var,
"e_x3": e_x3_var,
"e_x4": e_x4_var,
"impressions_x2": impressions_x2_var,
"impressions_x3": impressions_x3_var,
"impressions_x4": impressions_x4_var,
"beta_x1_x2": beta_x1_x2_var,
"beta_x1_x3": beta_x1_x3_var,
"beta_x2_x4": beta_x2_x4_var,
"beta_x3_x4": beta_x3_x4_var,
"x4_adstock_alpha": x4_adstock_alpha,
"x4_sat_lam": x4_sat_lam,
"x4_sat_alpha": x4_sat_alpha,
"event_contributions": np_event_contributions[:-1],
"trend": np_trend,
"global_noise": pz_global_noise,
}
)
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(target_var_eval, linewidth=2)
ax.set_title("Target Variable Over Time", fontsize=14)
ax.set_xlabel("Time Period", fontsize=12)
ax.set_ylabel("Target Value", fontsize=12);
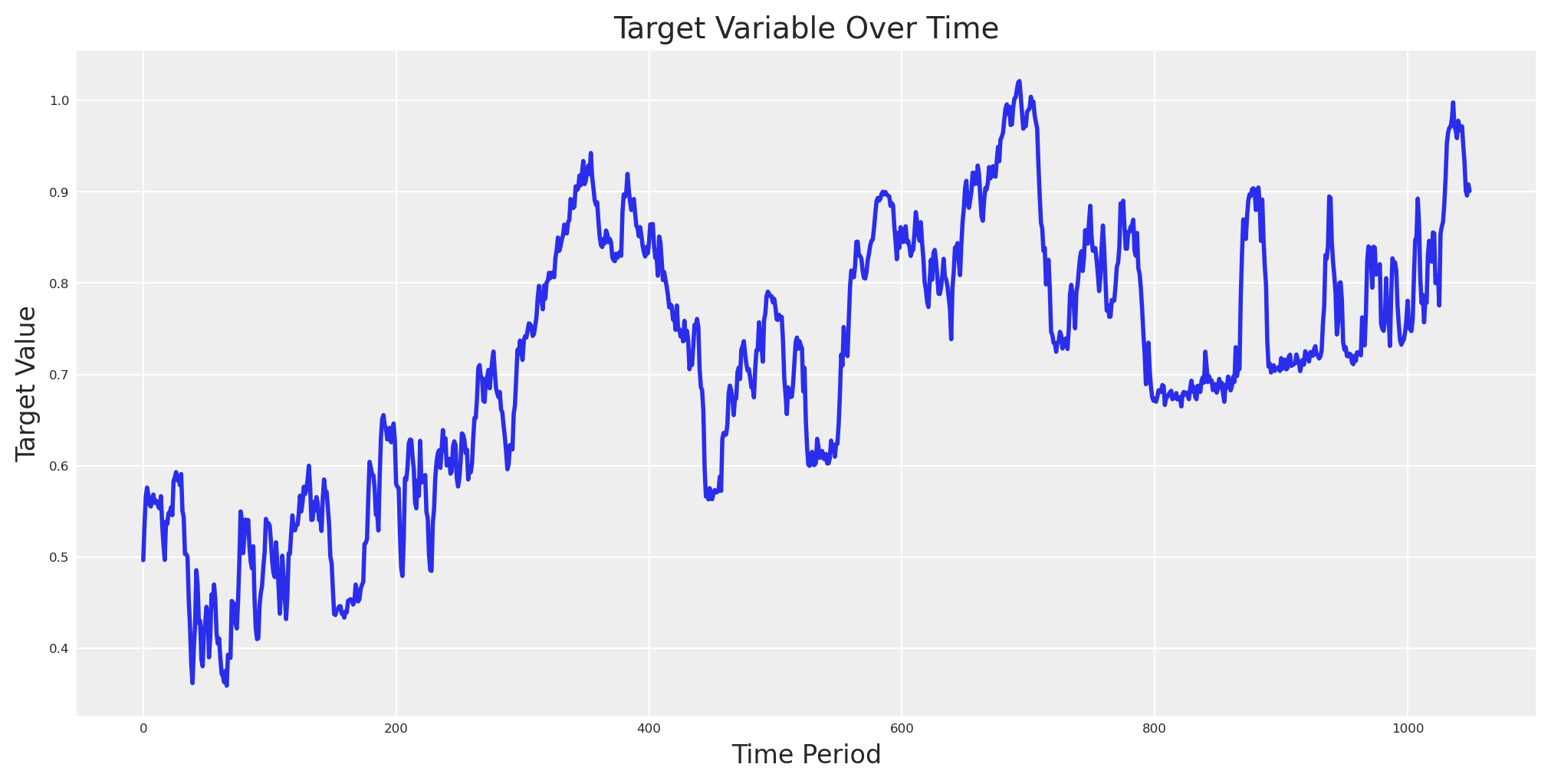
Empacamos nuestra historia en un único dataframe de pandas con características, controles y el resultado.
data = pd.DataFrame(
{
"date": date_range[:-1],
"target_var": np.round(target_var_eval, 4),
"impressions_x1": np.round(impressions_x1_eval, 4),
"impressions_x2": np.round(impressions_x2_eval, 4),
"impressions_x3": np.round(impressions_x3_eval, 4),
"impressions_x4": np.round(impressions_x4_eval, 4),
"event_2020_09": np.round(signals_independent[0][:-1], 4),
"event_2020_12": np.round(signals_independent[1][:-1], 4),
"event_2021_09": np.round(signals_independent[2][:-1], 4),
"event_2021_12": np.round(signals_independent[3][:-1], 4),
"event_2022_09": np.round(signals_independent[4][:-1], 4),
}
)
data["trend"] = data.index
data.head()
| date | target_var | impressions_x1 | impressions_x2 | impressions_x3 | impressions_x4 | event_2020_09 | event_2020_12 | event_2021_09 | event_2021_12 | event_2022_09 | trend | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022-01-01 | 0.4966 | 0.1577 | 0.1194 | 0.2208 | 0.1134 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 |
| 1 | 2022-01-02 | 0.5341 | 0.1394 | 0.1169 | 0.2263 | 0.1157 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1 |
| 2 | 2022-01-03 | 0.5659 | 0.1712 | 0.1177 | 0.2268 | 0.1240 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2 |
| 3 | 2022-01-04 | 0.5761 | 0.1175 | 0.1163 | 0.2247 | 0.1221 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 3 |
| 4 | 2022-01-05 | 0.5679 | 0.0927 | 0.1177 | 0.2209 | 0.1156 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 4 |
Train & Test split#
Mantenemos un grupo de retención para probar si nuestra historia contrafactual se extiende más allá de la ventana de entrenamiento.
# Split data into train and test sets
train_idx = 879
X_train = data.iloc[:train_idx].drop(columns=["target_var"])
X_test = data.iloc[train_idx:].drop(columns=["target_var"])
y_train = data.iloc[:train_idx]["target_var"]
y_test = data.iloc[train_idx:]["target_var"]
MMM causal todo en uno#
Qué es esto. Un único MMM con todos los canales modelados como si afectaran directamente a \(Y\). Cada canal utiliza Adstock Geométrico + saturación de Michaelis–Menten; la probabilidad es Normal censurada. Esta estrategia es muy común, reflejando básicamente el enfoque de mezclarlo todo en la licuadora.
control_columns = [
"event_2020_09",
"event_2020_12",
"event_2021_09",
"event_2021_12",
"event_2022_09",
"trend",
]
channel_columns = [
col for col in X_train.columns if col not in control_columns and col != "date"
]
Model configuration#
Podemos definir los priors del modelo para cada parte, saturación y adstock como es habitual en los modelos de pymc-marketing.
# Building priors for adstock and saturation
adstock_priors = {
"alpha": Prior("Beta", alpha=1, beta=1, dims="channel"),
}
adstock = GeometricAdstock(l_max=24, priors=adstock_priors)
saturation_priors = {
"lam": Prior(
"Gamma",
mu=2,
sigma=2,
dims="channel",
),
"alpha": Prior(
"Gamma",
mu=1,
sigma=1,
dims="channel",
),
}
saturation = MichaelisMentenSaturation(priors=saturation_priors)
Haciendo lo mismo, podemos definir el Prior para la verosimilitud. Establecemos una verosimilitud Normal censurada (sin negativos) y valores predeterminados de muestreo que se comportan bien en la práctica.
# Model config
model_config = {
"likelihood": Censored(
Prior(
"Normal",
sigma=Prior("HalfNormal", sigma=1),
dims="date",
),
lower=0,
)
}
# sampling options for PyMC
sample_kwargs = {
"tune": 1000,
"draws": 500,
"chains": 4,
"random_seed": SEED,
"target_accept": 0.84,
}
Con la configuración lista, construimos el modelo integral y extraemos de su posterior.
allin_mmm = MMM(
date_column="date",
target_column="target_var",
channel_columns=channel_columns,
control_columns=control_columns,
adstock=adstock,
saturation=saturation,
model_config=model_config,
sampler_config=sample_kwargs,
)
allin_mmm.build_model(X_train, y_train)
allin_mmm.add_original_scale_contribution_variable(var=["channel_contribution", "y"])
Fit model#
También generamos predicciones posteriores para vislumbrar los efectos de recuperación en la muestra.
allin_mmm.fit(
X_train,
y_train,
)
allin_mmm.sample_posterior_predictive(X_train, extend_idata=True, combined=True)
<xarray.Dataset> Size: 28MB
Dimensions: (date: 879, sample: 2000)
Coordinates:
* date (date) datetime64[ns] 7kB 2022-01-01 ... 2024-05-28
* sample (sample) object 16kB MultiIndex
* chain (sample) int64 16kB 0 0 0 0 0 0 0 0 0 ... 3 3 3 3 3 3 3 3
* draw (sample) int64 16kB 0 1 2 3 4 5 ... 495 496 497 498 499
Data variables:
y (date, sample) float64 14MB 0.4706 0.466 ... 0.8808 0.8961
y_original_scale (date, sample) float64 14MB 0.4806 0.4759 ... 0.9152
Attributes:
created_at: 2026-02-21T16:23:19.103288+00:00
arviz_version: 0.23.1
inference_library: pymc
inference_library_version: 5.27.0+22.g51fe965feOh! Podemos ver que el modelo ya está teniendo problemas para explorar el espacio de parámetros y está divergiendo.
Sin embargo, vayamos directamente a la pregunta: ¿Puede el modelo recuperar la verdadera contribución si no estuviéramos gastando nada en X1?
Podemos utilizar plot.contributions_over_time y obtener la salida de contribuciones para averiguarlo. Si el mezclador fue suficiente, recuperaría la verdadera contribución X1. Verifiquemos.
fig, ax = allin_mmm.plot.contributions_over_time(
var=["channel_contribution_original_scale"], hdi_prob=0.95
) # subplot 1 col, N rows = len(channel_columns)
# Keep only the first subplot (row 0, col 0) and hide the rest
for i in range(1, len(ax)):
ax[i, 0].set_visible(False)
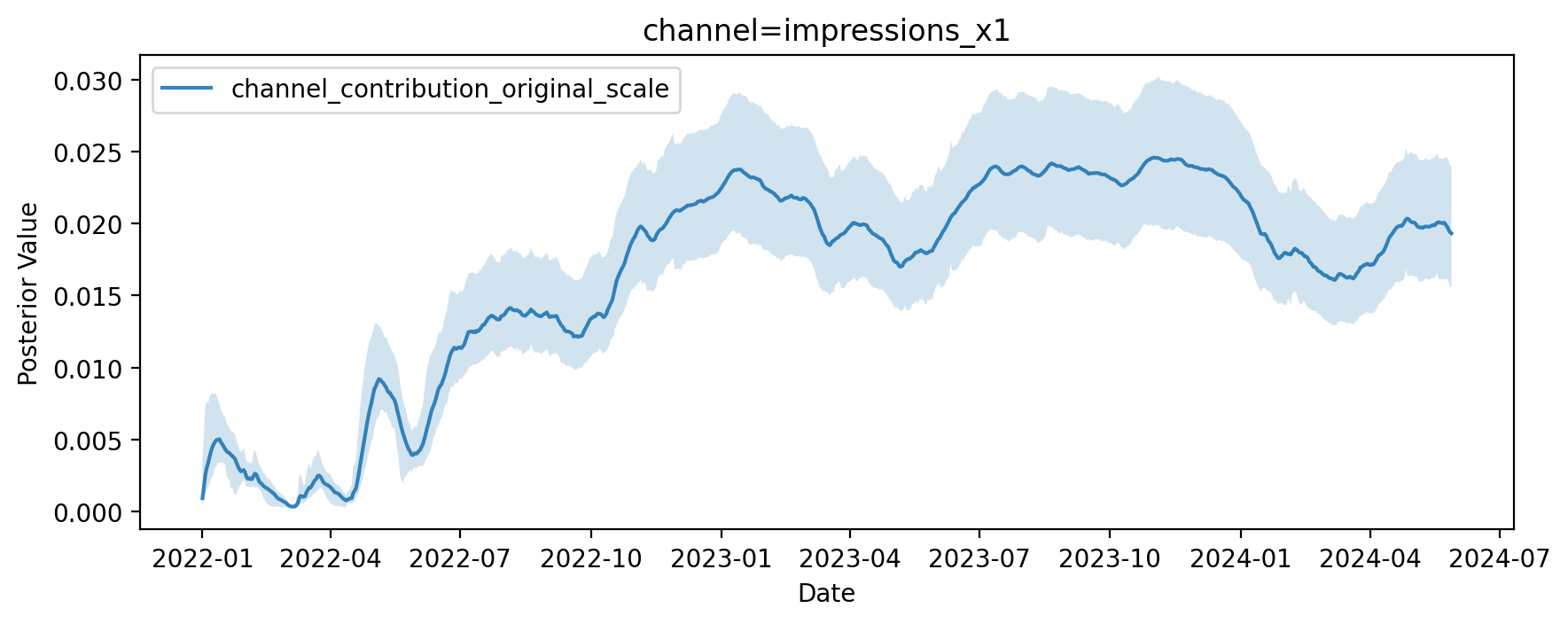
Esto es genial, pero necesitamos obtener la contribución real si x1 (Podemos calcularlo a partir de nuestro gráfico de pytensor, asumiendo que era cero y tomando eso del objetivo).
impressions_x1_zero_var = np.zeros_like(impressions_x1_var)
target_var_do_x1_eval = y.eval(
{
"impressions_x1": impressions_x1_zero_var,
"event_signal": np_event_signal[:-1],
"beta_event_x1": beta_event_x1_var,
"e_x1": e_x1_var,
"e_x2": e_x2_var,
"e_x3": e_x3_var,
"e_x4": e_x4_var,
"impressions_x2": impressions_x2_var,
"impressions_x3": impressions_x3_var,
"impressions_x4": impressions_x4_var,
"beta_x1_x2": beta_x1_x2_var,
"beta_x1_x3": beta_x1_x3_var,
"beta_x2_x4": beta_x2_x4_var,
"beta_x3_x4": beta_x3_x4_var,
"x4_adstock_alpha": x4_adstock_alpha,
"x4_sat_lam": x4_sat_lam,
"x4_sat_alpha": x4_sat_alpha,
"event_contributions": np_event_contributions[:-1],
"trend": np_trend,
"global_noise": pz_global_noise,
}
)
x1_real_contribution = target_var_eval - target_var_do_x1_eval
Ahora que tenemos ambos, podemos comparar.
fig, ax = allin_mmm.plot.contributions_over_time(
var=["channel_contribution_original_scale"], hdi_prob=0.95
) # subplot 1 col, N rows = len(channel_columns)
# Keep only the first subplot (row 0, col 0) and hide the rest
for i in range(1, len(ax)):
ax[i, 0].set_visible(False)
# pick only the first row don't plot the rest
ax[0, 0].plot(
date_range[:train_idx],
x1_real_contribution[:train_idx],
label="True Contribution",
color="black",
linewidth=2,
)
ax[0, 0].legend();
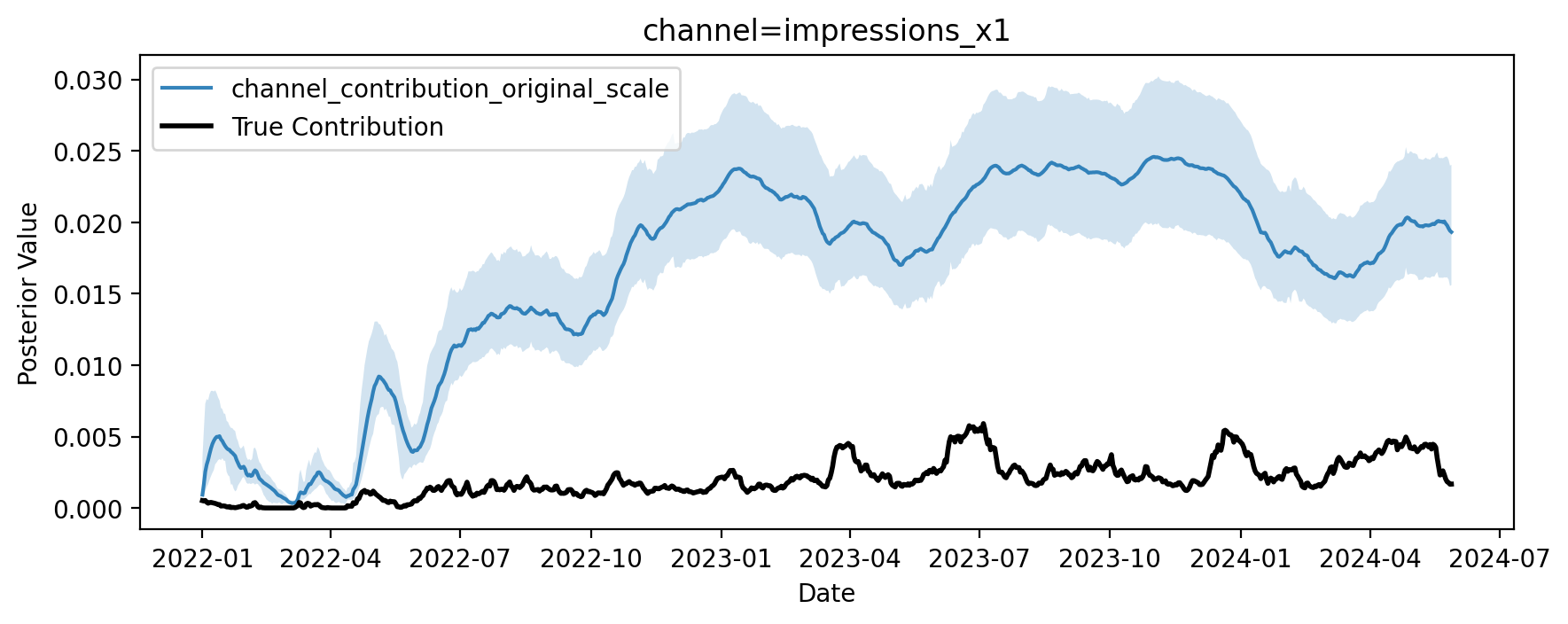
Como era de esperar, poner-todo-en-la-licuadora sobreestima los efectos del embudo superior. Pero, ¿por qué falla el enfoque ingenuo?
Learning about regression assumptions#
Cuando ajustamos un modelo que incluye todas las variables (\(X_1, X_2, X_3, X_4, Y\)), observamos que el coeficiente que vincula \(X_1\) con \(Y\) era demasiado grande. Esto sucede porque el modelo no respeta la estructura causal definida por nuestras ecuaciones estructurales.
El verdadero mecanismo causal#
En nuestro proceso de generación de datos, \(X_1\) no afecta directamente a \(Y\). Su influencia pasa completamente a través de la secuencia:
Cada enlace añade su contribución, y el paso final (\(X_4 \to Y\)) puede ser no lineal (por ejemplo, mostrando efectos de saturación o adstock).
El efecto total real de \(X_1\) sobre \(Y\) depende de cuánto \(X_1\) cambie \(X_4\) y de cuán sensible sea \(Y\) a \(X_4\). Simbólicamente,
Una regresión que incluye tanto \(X_1\) como \(X_4\) como predictores de \(Y\) rompe la lógica del gráfico causal. Porque una regresión estándar asume implícitamente que cada predictor explica la variación en \(Y\) condicional a los otros, sin respetar la dirección causal. Matemáticamente, los coeficientes estimados \((\hat\beta_1, \hat\beta_4)\) en
proviene de minimizar la varianza residual conjunta, es decir, resolver las ecuaciones normales:
Estas ecuaciones dependen no solo de la relación entre cada \(X_j\) y \(Y\), sino también de la covarianza entre los predictores \(\operatorname{Cov}(X_1,X_4)\). Por lo tanto, la regresión está influenciada por correlaciones por pares entre las covariables mismas.
Porque \(X_1\) y \(X_4\) están fuertemente correlacionados (debido a la cadena causal \(X_1 \to X_4\)), y porque \(Y\) responde no lineal o dinámicamente a \(X_4\), la regresión no puede representar la verdadera relación \(Y = f(X_4)\). Los residuos de esta especificación incorrecta se correlacionan con \(X_1\), y parte de la estructura no lineal de \(f(X_4)\) se atribuye erróneamente a \(X_1\).
En efecto:
\(X_4\) es un mediador del efecto de \(X_1\).
Condicionar sobre \(X_4\) bloquea el verdadero camino de \(X_1\) a \(Y\).
Debido a que la regresión también equilibra las correlaciones entre los predictores, cualquier patrón no lineal o rezagado en \(Y\) que dependa de \(X_4\) pero que no esté modelado correctamente se redistribuye entre los predictores correlacionados, principalmente \(X_1\).
Truco
Intuición matemática: El coeficiente de regresión de \(X_1\) es proporcional a la covarianza parcial
y dado que \(Y\) depende de manera no lineal de \(X_4\) mientras que \(X_1\) y \(X_4\) son colineales, \(\operatorname{Cov}(X_1,\,Y \mid X_4)\) permanece positivo incluso si el verdadero efecto directo \(X_1\!\to\!Y\) es cero. Esto crea la ilusión de una gran influencia directa de \(X_1\).
El criterio de puerta trasera#
Toda la lógica anterior se enmarca bajo el criterio de puerta trasera que nos indica qué variables debemos (y no debemos) ajustar para estimar correctamente un efecto causal.
What it means?#
Un conjunto de variables \(Z\) satisface el criterio de puerta trasera para el efecto de \(X\) sobre \(Y\) si:
Ninguna de las variables en \(Z\) son efectos de \(X\) (no deben estar en la parte posterior).
Una vez que controlamos por \(Z\), no hay caminos desbloqueados que comiencen con una flecha hacia \(X\) (estos son «caminos de puerta trasera» que representan confusión).
Si se cumplen estas dos condiciones, podemos identificar el efecto causal de \(X\) sobre \(Y\) comparando unidades con diferentes valores de \(X\) pero el mismo \(Z\).
En nuestro caso#
Para estimar el efecto causal de \(X_1\) sobre \(Y\):
Debemos ajustar los factores de fondo que afectan tanto a \(X_1\) como a \(Y\) (por ejemplo, \(\mathrm{Trend}_t\) o \(\mathrm{Events}_t\)).
No debemos ajustar por mediadores como \(X_2\), \(X_3\) o \(X_4\), porque estos son efectos de \(X_1\).
Matemáticamente, el efecto causal puede expresarse como:
donde \(Z_t\) contiene únicamente las variables de puerta trasera válidas (causas comunes, no descendientes).
En este caso, esto implicará estimar el efecto de \(X4\) en \(Y\). Luego podríamos estimar el efecto de \(X1\) en \(X4\) y obtener la propagación del efecto de \(X1\) en \(Y\) después.
Mediator model#
Pensemos una vez más en nuestro diagrama, \(X1\) es el canal superior del embudo. \(X4\) es el canal inferior del embudo. \(Y\) es el resultado. Esto significa que \(X1\) no tiene un efecto directo sobre \(Y\), pero sí tiene un efecto indirecto a través de \(X4\). Esto significa que \(X4\) media el efecto de \(X1\) sobre \(Y\).
The minimal adjustment set based on backdoor paths dictates that we need to estimate the effect of \(X4\) on \(Y\) easily, a simple linear or nonlinear model \(Y = f(\theta, X4) + \varepsilon\) would be enough because \(X4\) will block all backdoor paths for the rest of variables.
first_causal_mmm = MMM(
date_column="date",
target_column="target_var",
channel_columns=["impressions_x4"],
control_columns=control_columns,
adstock=adstock,
saturation=saturation,
model_config=model_config,
sampler_config=sample_kwargs,
)
first_causal_mmm.build_model(X_train, y_train)
first_causal_mmm.add_original_scale_contribution_variable(
var=["channel_contribution", "y"]
)
first_causal_mmm.fit(
X_train,
y_train,
)
first_causal_mmm.sample_posterior_predictive(X_train, extend_idata=True, combined=True)
<xarray.Dataset> Size: 28MB
Dimensions: (date: 879, sample: 2000)
Coordinates:
* date (date) datetime64[ns] 7kB 2022-01-01 ... 2024-05-28
* sample (sample) object 16kB MultiIndex
* chain (sample) int64 16kB 0 0 0 0 0 0 0 0 0 ... 3 3 3 3 3 3 3 3
* draw (sample) int64 16kB 0 1 2 3 4 5 ... 495 496 497 498 499
Data variables:
y (date, sample) float64 14MB 0.5422 0.4857 ... 0.8644
y_original_scale (date, sample) float64 14MB 0.5538 0.4961 ... 0.8828
Attributes:
created_at: 2026-02-21T16:23:44.334434+00:00
arviz_version: 0.23.1
inference_library: pymc
inference_library_version: 5.27.0+22.g51fe965feVeamos si podemos recuperar la verdadera contribución de \(X4\) en \(Y\). Este será el paso más esencial para recuperar la verdadera contribución de \(X1\) en \(Y\) después. Aquí, al igual que antes, podemos tomar nuestro gráfico de pytensor y evaluarlo con los valores de \(X4\) y obtener la verdadera contribución.
real_contribution_x4 = impressions_x4_forward.eval(
{
"impressions_x1": impressions_x1_var,
"event_signal": np_event_signal[:-1],
"beta_event_x1": beta_event_x1_var,
"e_x1": e_x1_var,
"e_x2": e_x2_var,
"e_x3": e_x3_var,
"e_x4": e_x4_var,
"impressions_x2": impressions_x2_var,
"impressions_x3": impressions_x3_var,
"impressions_x4": impressions_x4_var,
"beta_x1_x2": beta_x1_x2_var,
"beta_x1_x3": beta_x1_x3_var,
"beta_x2_x4": beta_x2_x4_var,
"beta_x3_x4": beta_x3_x4_var,
"x4_adstock_alpha": x4_adstock_alpha,
"x4_sat_lam": x4_sat_lam,
"x4_sat_alpha": x4_sat_alpha,
}
)
Si este bloque de resultado es fiel, sus contribuciones deberían seguir la verdad simulada.
fig, ax = first_causal_mmm.plot.contributions_over_time(
var=["channel_contribution_original_scale"], hdi_prob=0.95
) # subplot 1 col, N rows = len(channel_columns) = 1
ax[0, 0].plot(
date_range[:train_idx],
real_contribution_x4[:train_idx],
label="True Contribution",
color="black",
linewidth=2,
)
ax[0, 0].legend();
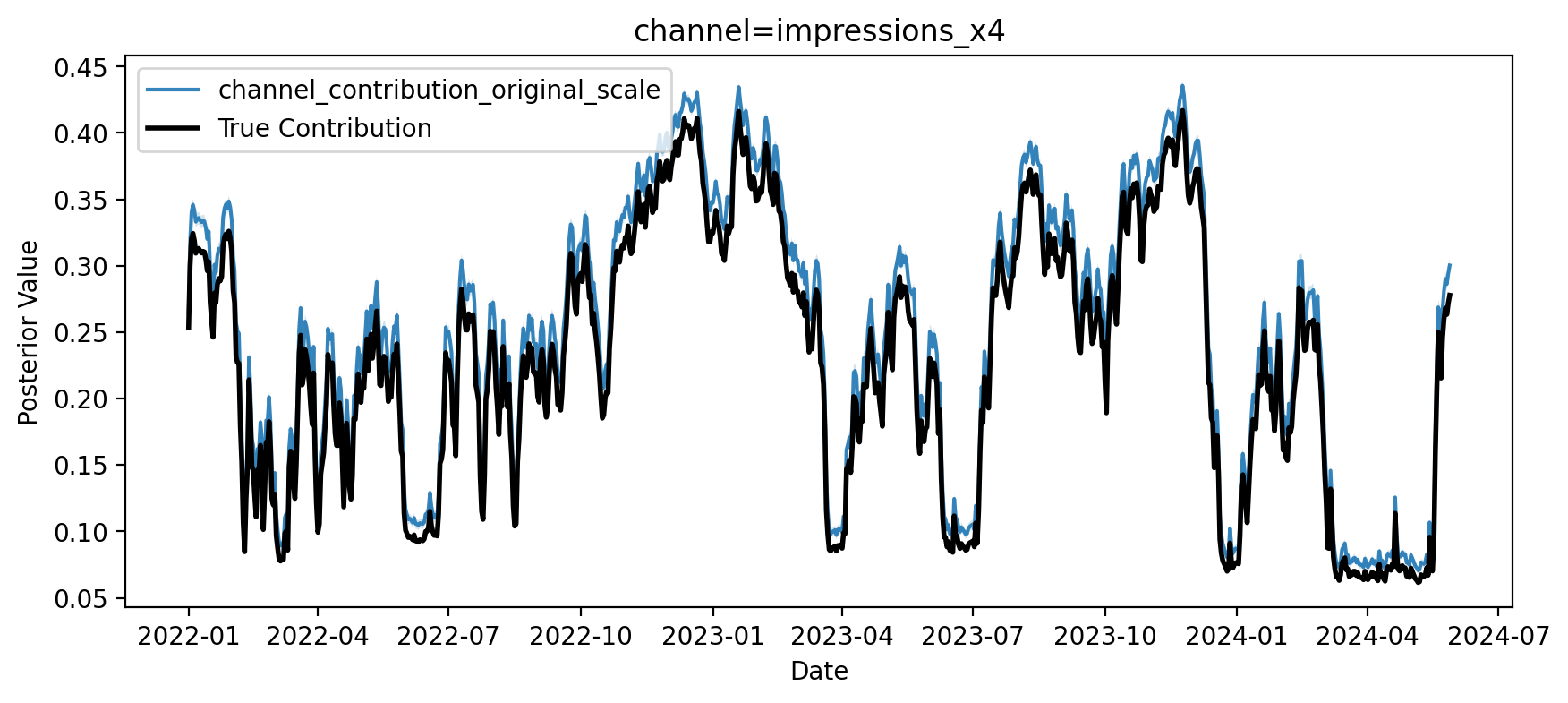
Excelente, podemos observar que se recuperó el valor verdadero. Ahora podemos avanzar y estimar el efecto de \((X_1)\) en \((X_4)\). Este es el segundo paso esencial antes de cuantificar la contribución de \((X_1)\) a \((Y)\).
Ahora, en la vida real no conoces la verdadera forma estructural que genera tus datos, aquí estoy tomando dos elecciones.
Modeling choices.
Elimino temporalmente el adstock y la saturación para que la relación \((X_1 \to X_4)\) sea lineal.
Evito una regresión de niveles sobre niveles como \((X_{4,t} = \beta\,X_{1,t} + \varepsilon_t)\).
This could be translate to I don’t think effect of \(X1\) saturates or adstock before impact \(X4\).
Construyamos este modelo para ver si podemos recuperar el valor verdadero.
X_train["impressions_x1_diff"] = X_train["impressions_x1"].diff()
X_train["impressions_x4_diff"] = X_train["impressions_x4"].diff()
second_causal_mmm = MMM(
date_column="date",
target_column="impressions_x4_diff",
channel_columns=["impressions_x1_diff"],
adstock=NoAdstock(
l_max=1
), # We remove the adstock because we want to estimate the causal effect of x1 on x4 which is purely linear
saturation=NoSaturation(
priors={"beta": Prior("Gamma", mu=0.7, sigma=0.4, dims=())}
), # linear beta, pooled over channels
sampler_config=sample_kwargs,
)
second_causal_mmm.build_model(
X_train.drop(columns=["impressions_x4_diff"]),
X_train["impressions_x4_diff"],
)
second_causal_mmm.add_original_scale_contribution_variable(
var=["channel_contribution", "y"]
)
second_causal_mmm.fit(
X_train.drop(columns=["impressions_x4_diff"]),
X_train["impressions_x4_diff"],
)
second_causal_mmm.sample_posterior_predictive(
X_train.drop(columns=["impressions_x4_diff"]),
extend_idata=True,
combined=True,
)
<xarray.Dataset> Size: 28MB
Dimensions: (date: 879, sample: 2000)
Coordinates:
* date (date) datetime64[ns] 7kB 2022-01-01 ... 2024-05-28
* sample (sample) object 16kB MultiIndex
* chain (sample) int64 16kB 0 0 0 0 0 0 0 0 0 ... 3 3 3 3 3 3 3 3
* draw (sample) int64 16kB 0 1 2 3 4 5 ... 495 496 497 498 499
Data variables:
y (date, sample) float64 14MB 0.006032 0.08319 ... 0.1773
y_original_scale (date, sample) float64 14MB 0.0002678 ... 0.007874
Attributes:
created_at: 2026-02-21T16:23:46.931674+00:00
arviz_version: 0.23.1
inference_library: pymc
inference_library_version: 5.27.0+22.g51fe965feNota
¿Por qué construir un modelo utilizando la diferencia entre variables? Si \((X_{1,t})\) y \((X_{4,t})\) son \((I(1))\) y no están cointegrados, el residuo de \((X_{4,t} - \beta X_{1,t})\) permanece \((I(1))\). OLS en niveles produce inferencias inválidas y un \((\hat\beta)\) que se desvía. La diferenciación primera elimina raíces unitarias y produce una relación estacionaria:
donde \((\eta_t)\) es \((I(0))\). Bajo la exogeneidad estándar de las innovaciones, OLS estima consistentemente el efecto instantáneo total \((\beta)\) de \((X_1)\) sobre \((X_4)\). En la práctica, \(\alpha eq 0\) porque las derivadas en los procesos de nivel se traducen en una media no nula en las diferencias.
Podemos trazar la distribución posterior del beta para ver si se recuperó el valor verdadero. Dado que el proceso de generación de datos es lineal, podemos calcular el coeficiente verdadero de \(x1\) sobre \(x4\) haciendo ( \(\beta_{1,2} * \beta_{2,4} * \beta_{1,3} * \beta_{3,4}\) )
true_beta_x1_x4 = beta_x1_x2_var * beta_x2_x4_var + beta_x1_x3_var * beta_x3_x4_var
az.plot_posterior(
second_causal_mmm.fit_result * second_causal_mmm.scalers._target.item(),
var_names=[
"saturation_beta",
],
figsize=(12, 4),
ref_val=(true_beta_x1_x4),
);
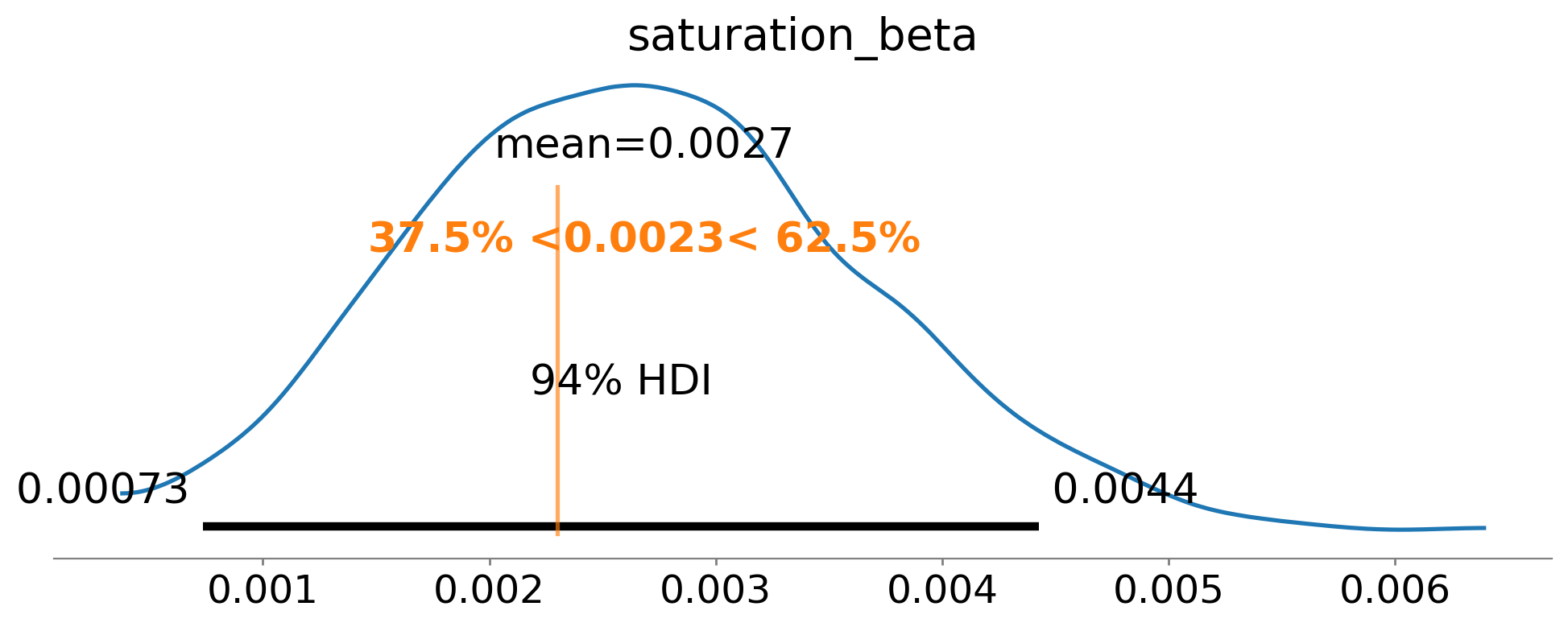
El posterior se establece cerca de la verdad fundamental, que es lo que esperaríamos si nuestra historia es coherente. Ahora, ¿qué? Armados con la beta mediada, traducimos la conciencia en presión descendente a lo largo del tiempo, dentro de la muestra y más allá.
Creemos el xarray con la difusión adecuada para las dimensiones de cadena, dibujo y fecha.
# Create xarray with proper broadcasting for chain, draw, date dimensions
impressions_x1 = xr.DataArray(X_train["impressions_x1"], dims=("date",))
saturation_beta_scaled = (
second_causal_mmm.idata.posterior.saturation_beta
* second_causal_mmm.scalers._target.item()
)
posterior_contribution_x1_over_x4 = (impressions_x1 * saturation_beta_scaled).transpose(
"chain", "draw", "date"
)
Ahora, tenemos la contribución estimada de \(X1\) sobre \(X4\). Vamos a graficar en comparación con la verdadera contribución de \(X1\) sobre \(X4\).
# Get HDI for the posterior contribution
hdi_data = az.hdi(posterior_contribution_x1_over_x4, hdi_prob=0.94)
# Plot HDI and mean in the same plot
fig, ax = plt.subplots(figsize=(12, 4))
# Plot HDI
az.plot_hdi(
X_train.index,
posterior_contribution_x1_over_x4,
color="C0",
fill_kwargs={"alpha": 0.3},
smooth=False,
ax=ax,
)
# Plot mean
posterior_contribution_x1_over_x4.mean(dim=["draw", "chain"]).plot(
ax=ax, label="Estimated Contribution", color="blue", linestyle="--"
)
# Plot true contribution
ax.plot(
X_train.index,
(impressions_x1 * true_beta_x1_x4),
label="True Contribution",
color="black",
linewidth=2,
)
ax.set_title("Estimated vs True Contribution of X1 on X4")
ax.set_ylabel("Estimated Contribution")
ax.legend();
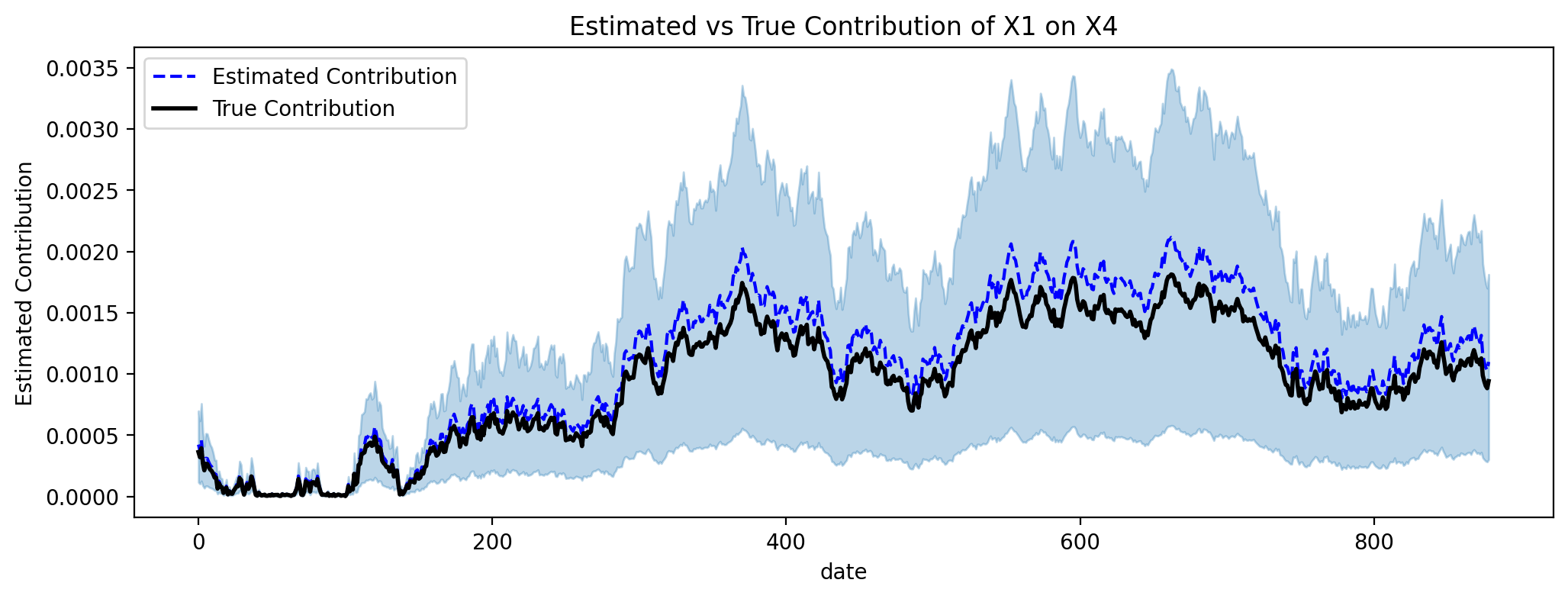
Excelente, podemos ver que la contribución estimada está muy cerca de la verdadera contribución en el período de muestra. Podemos hacer lo mismo para el período fuera de muestra, y utilizando el período fuera de muestra, podemos verificar si recuperamos el efecto causal de \(X1\) sobre \(Y\).
oos_impressions_x1 = xr.DataArray(X_test["impressions_x1"], dims=("date",))
# Broadcast to create (chain, draw, date) output
oos_posterior_contribution_x1_over_x4 = (
oos_impressions_x1 * saturation_beta_scaled
).transpose("chain", "draw", "date")
Estas estimaciones nos indican cuánto está contribuyendo \(X1\) a \(X4\) en el período fuera de muestra. Si queremos plantear la pregunta causal, necesitamos un contrafactual: ¿Qué habría sido \(X4\) si la concienciación hubiera llegado a cero? Podemos hacer esto tomando el valor original de \(X4\) y restando la contribución estimada de \(X1\) sobre \(X4\).
oos_x4_counterfactual = (
# we need impressions_x4_eval to be in the same scale as the model
xr.DataArray(impressions_x4_eval[train_idx:], dims=("date",))
- oos_posterior_contribution_x1_over_x4
)
Enviamos ese contrafactual \(X_4\) bajo \(do(X_1=0)\) a través del modelo de resultados para obtener \(Y\) bajo \(do(X_1=0)\) como consecuencia. Entonces, el efecto causal será \(Y|do(X_1=1) - Y|do(X_1=0)\).
Calcularemos la verdadera influencia de \(X_1\) sobre \(Y\) mediante nuestro verdadero gráfico de pytensor y, finalmente, compararemos el efecto recuperado con el efecto verdadero.
X_test_x1_zero = X_test.copy()
quantiles = [0.05, 0.15, 0.25, 0.5, 0.75, 0.85, 0.95]
posteriors_y_do_x1_zero = []
for quantile in quantiles:
X_test_x1_zero["impressions_x4"] = oos_x4_counterfactual.quantile(
quantile, dim=["draw", "chain"]
).values
_temp = first_causal_mmm.sample_posterior_predictive(
X_test_x1_zero,
extend_idata=False,
include_last_observations=True,
combined=False,
random_seed=SEED,
var_names=["channel_contribution_original_scale", "y_original_scale"],
)
posteriors_y_do_x1_zero.append(_temp)
y_do_x1_zero = (
xr.concat(posteriors_y_do_x1_zero, dim="quantile")
.rename({"chain": "chain_orig"})
.stack(chain=("quantile", "chain_orig"))
.reset_index("chain", drop=True)
.transpose("chain", "draw", "date", "channel")
).sel(chain=slice(None, None, len(quantiles)))
y_do_x1 = first_causal_mmm.sample_posterior_predictive(
X_test,
extend_idata=False,
include_last_observations=True,
combined=False,
random_seed=SEED,
var_names=["channel_contribution_original_scale", "y_original_scale"],
)
# Estimated effect of x1 in Y
x1_causal_effect = (y_do_x1_zero - y_do_x1).channel_contribution_original_scale.sum(
dim="channel"
)
# Estimate real effect of x1 in Y
impressions_x1_var_intervention = impressions_x1_var.copy()
impressions_x1_var_intervention[train_idx:] = 0
# Eval target_var and plot
target_var_x1_intervention_eval = y.eval(
{
"impressions_x1": impressions_x1_var_intervention,
"event_signal": np_event_signal[:-1],
"beta_event_x1": beta_event_x1_var,
"e_x1": e_x1_var,
"e_x2": e_x2_var,
"e_x3": e_x3_var,
"e_x4": e_x4_var,
"impressions_x2": impressions_x2_var,
"impressions_x3": impressions_x3_var,
"impressions_x4": impressions_x4_var,
"beta_x1_x2": beta_x1_x2_var,
"beta_x1_x3": beta_x1_x3_var,
"beta_x2_x4": beta_x2_x4_var,
"beta_x3_x4": beta_x3_x4_var,
"x4_adstock_alpha": x4_adstock_alpha,
"x4_sat_lam": x4_sat_lam,
"x4_sat_alpha": x4_sat_alpha,
"event_contributions": np_event_contributions[:-1],
"trend": np_trend,
"global_noise": pz_global_noise,
}
)
causal_effect_x1_over_y = target_var_x1_intervention_eval - target_var_eval
Vamos a trazar el efecto recuperado frente al efecto verdadero, uno al lado del otro.
dates = x1_causal_effect.coords["date"].values[:100] # Take only first 100 days
mean_effect = x1_causal_effect.mean(dim=["draw", "chain"]).sel(
date=slice(dates[0], dates[-1])
)
fig, ax = plt.subplots(figsize=(12, 4))
ax.plot(dates, mean_effect, label="Recovered Effect", color="blue", linestyle="--")
ax.plot(
dates,
causal_effect_x1_over_y[train_idx:][:100],
label="Real Effect",
color="black",
linewidth=2,
)
az.plot_hdi(
dates,
x1_causal_effect.sel(date=slice(dates[0], dates[-1])),
color="blue",
smooth=False,
fill_kwargs={"alpha": 0.3},
ax=ax,
)
plt.legend();
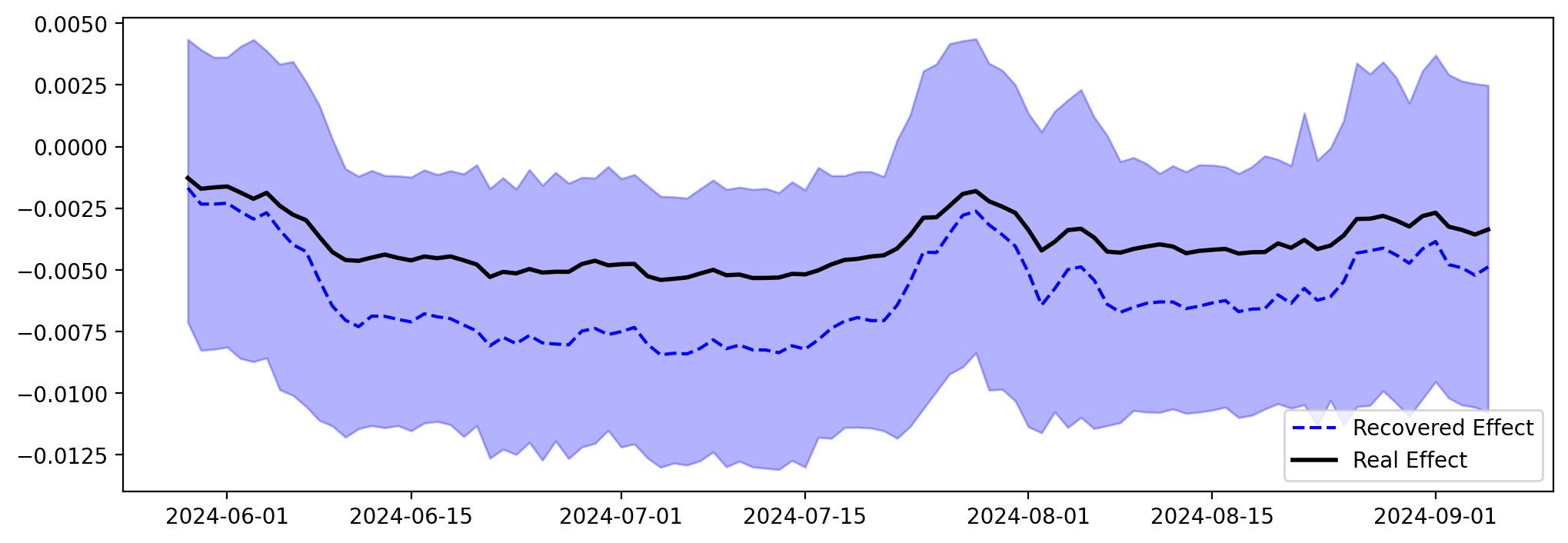
Esto es excelente, podemos ver que el efecto recuperado está muy cerca del efecto verdadero en el período de muestra. Podemos hacer lo mismo para el período fuera de muestra, y utilizando el período fuera de muestra, observamos que el efecto causal de \(X1\) sobre \(Y\) fue correctamente recuperado.
Conclusion#
En este tutorial mostramos que es posible recuperar impactos de alto nivel y de embudo superior incluso cuando el objetivo observado es un KPI de embudo inferior. Al modelar explícitamente la mediación y luego propagar esa señal a través del modelo de resultados, capturamos la contribución causal de la actividad de embudo superior a partir de objetivos de bajo nivel.
Efecto mediado estimado: cuantificar el vínculo desde la conciencia hasta un mediador posterior y recuperar su contribución.
Propagar a resultados: traducir el efecto mediado en la presión esperada sobre el objetivo final a través del MMM.
Contrafactuales causales: comparar con contrafactuales del operador do para medir de manera creíble el aumento en la parte superior del embudo.
Esto hace que el valor del embudo superior sea medible junto con los canales de rendimiento, mejorando la atribución, la previsión y las decisiones presupuestarias, mientras mantiene el modelo fundamentado en una estructura causal.
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,pymc,pymc_marketing,numpyro
Last updated: Sat, 21 Feb 2026
Python implementation: CPython
Python version : 3.13.11
IPython version : 9.9.0
pytensor : 2.36.3+35.gd87027768
pymc : 5.27.0+22.g51fe965fe
pymc_marketing: 0.17.1
numpyro : unknown
arviz : 0.23.1
graphviz : 0.21
matplotlib : 3.10.8
numpy : 2.3.5
pandas : 2.3.3
preliz : 0.23.0
pymc_extras : 0.6.1.dev9+g828353dcd
pymc_marketing: 0.17.1
pytensor : 2.36.3+35.gd87027768
xarray : 2025.12.0
Watermark: 2.6.0