Custom Models with MMM components#
The underlying components used in the MMM class provide flexibility to build other, custom models. With a little knowledge of PyMC and how to customize these PyMC-Marketing components, a lot of different use-cases can be covered.
This notebook is not an introduction but rather an advance example for those trying to understand the PyMC-Marketing internals for flexibility for custom use-cases.
Overview#
This notebook will cover the currently exposed model components from the PyMC-Marketing API. At the moment, this includes:
media transformations
adstock: how today’s media has an effect in the future
saturation: the diminishing returns for media
For each of these, the flexibility and customization will be showcased and combined together in a toy model.
Setup#
from functools import partial
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import xarray as xr
from pymc_marketing import mmm
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
%config InlineBackend.figure_format = "retina"
seed = sum(map(ord, "PyMC-Marketing provides flexible model components"))
rng = np.random.default_rng(seed)
draw = partial(pm.draw, random_seed=rng)
Media Transformations#
There are classes for each of the adstock and saturation transformations. They can be imported from the pymc_marketing.mmm module.
saturation = mmm.MichaelisMentenSaturation()
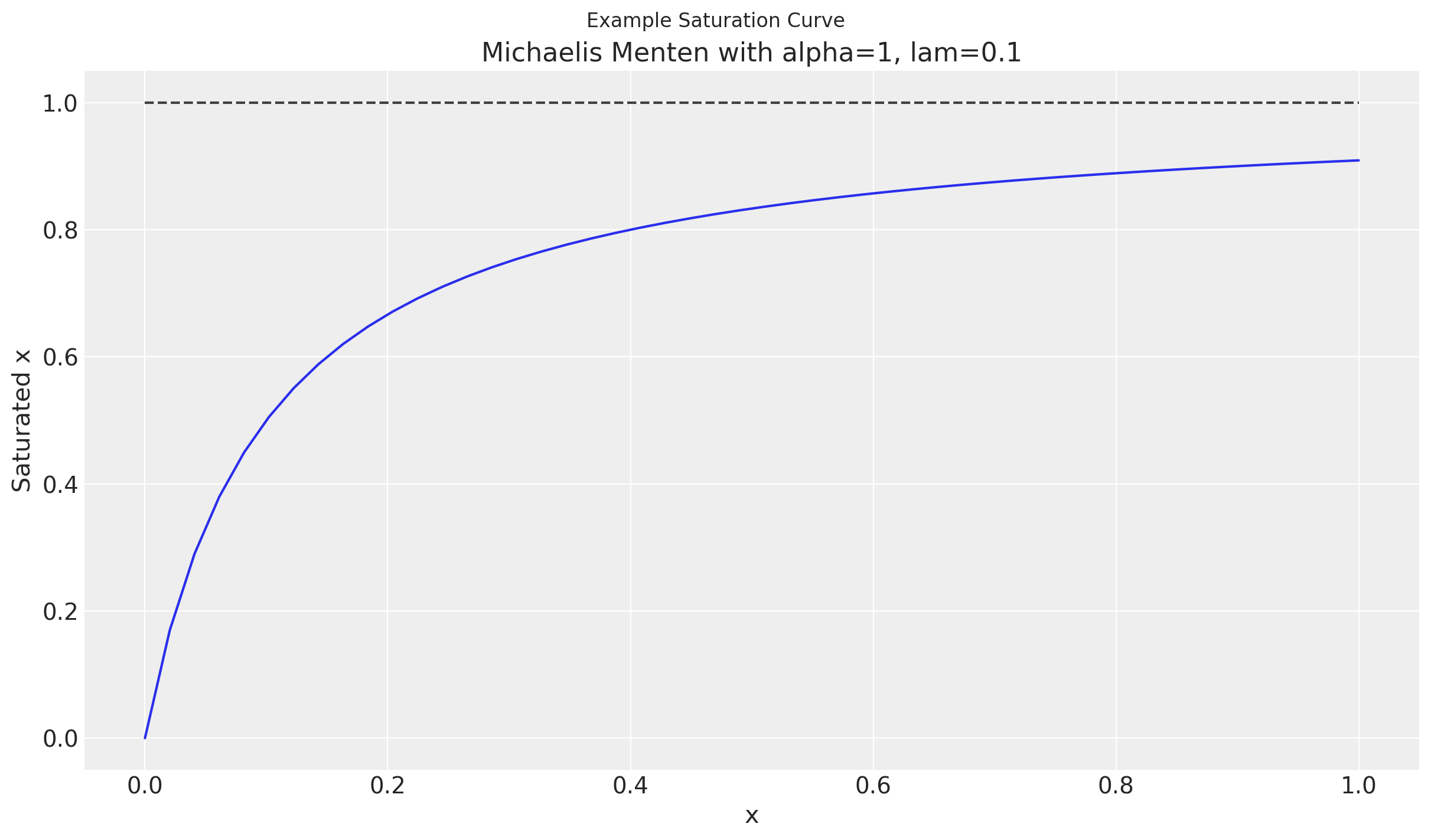
Saturation curves can take many different forms. In this example, we will use the Michaelis Menten curve which we provide in the MichaelisMentenSaturation class.
This curve has two parameters, alpha and lam.
A characteristic of these curves are diminishing returns in order to indicate saturation of a media variable. This can be seen in the plateauing as x increases.
Show code cell source
xx = np.linspace(0, 1)
alpha = 1
lam = 1 / 10
yy = saturation.function(xx, alpha=alpha, lam=lam)
fig, ax = plt.subplots()
fig.suptitle("Example Saturation Curve")
ax.plot(xx, yy)
ax.plot(xx, np.ones_like(xx) * alpha, color="black", linestyle="dashed", alpha=0.75)
ax.set(
xlabel="x",
ylabel="Saturated x",
title=f"Michaelis Menten with {alpha=}, {lam=}",
);
Sampling Transformation Function#
Each of the transformation will have a set of default priors. These can be altered at initialization with the priors parameter but will ultimately be stored in the function_priors attribute of the instance. There will be a prior for each of the estimated parameters used in the function.
saturation.function_priors
{'alpha': {'dist': 'Gamma', 'kwargs': {'mu': 2, 'sigma': 1}},
'lam': {'dist': 'HalfNormal', 'kwargs': {'sigma': 1}}}
The sample_prior method can be used to sample the parameters of the functions.
Note
There is the prefix saturation_ on each of the parameters in order to not clash with the larger model. This is the default but can be changed as well.
parameters = saturation.sample_prior(random_seed=rng)
parameters
Sampling: [saturation_alpha, saturation_lam]
<xarray.Dataset> Size: 12kB
Dimensions: (chain: 1, draw: 500)
Coordinates:
* chain (chain) int64 8B 0
* draw (draw) int64 4kB 0 1 2 3 4 5 6 ... 494 495 496 497 498 499
Data variables:
saturation_alpha (chain, draw) float64 4kB 2.114 0.8256 ... 2.056 2.347
saturation_lam (chain, draw) float64 4kB 0.7597 0.09256 ... 0.8022 0.8724
Attributes:
created_at: 2024-06-18T07:24:51.831207
arviz_version: 0.17.0
inference_library: pymc
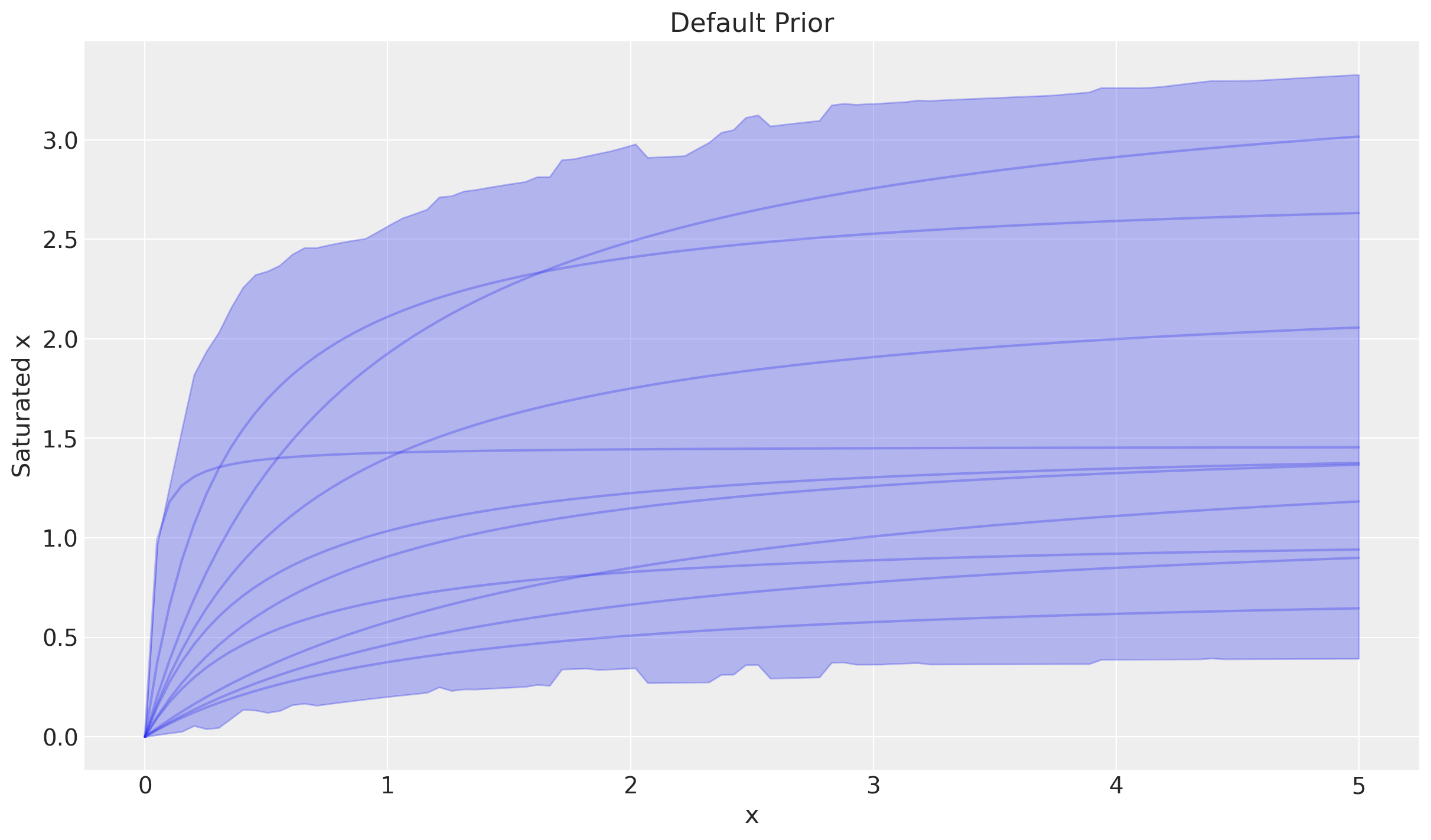
inference_library_version: 5.14.0With parameters for the function, the curve can be sampled as well. Combining sample_curve and plot_curve together can provide good insight into the shape the curve makes!
This shows the most likely curves under the prior distributions.
curve = saturation.sample_curve(parameters, max_value=5)
_, axes = saturation.plot_curve(curve)
axes[0].set(
ylabel="Saturated x",
title="Default Prior",
);
Sampling: []
Tip
The posterior can be used instead of the prior in both the sample_curve and plot_curve methods. Any additional coordinates from the parameters will be handled automatically!
Adding Parameter Dimensions#
In most cases, a separate saturation function will be estimated for each media channel. A dimension needs to be added to the prior of the function parameters to account for this.
Let’s create some example data to work toward this transformation.
Show code cell source
def random_spends(coords) -> xr.DataArray:
"""Create random spends that turn off and on."""
size = tuple([len(values) for values in coords.values()])
dims = list(coords.keys())
amount_rv = pm.HalfNormal.dist(size=size)
stopped_rv = pm.Normal.dist(size=size).cumsum(axis=0) <= 0
spends_rv = amount_rv * stopped_rv
return xr.DataArray(
draw(spends_rv),
coords=coords,
dims=dims,
name="spends",
)
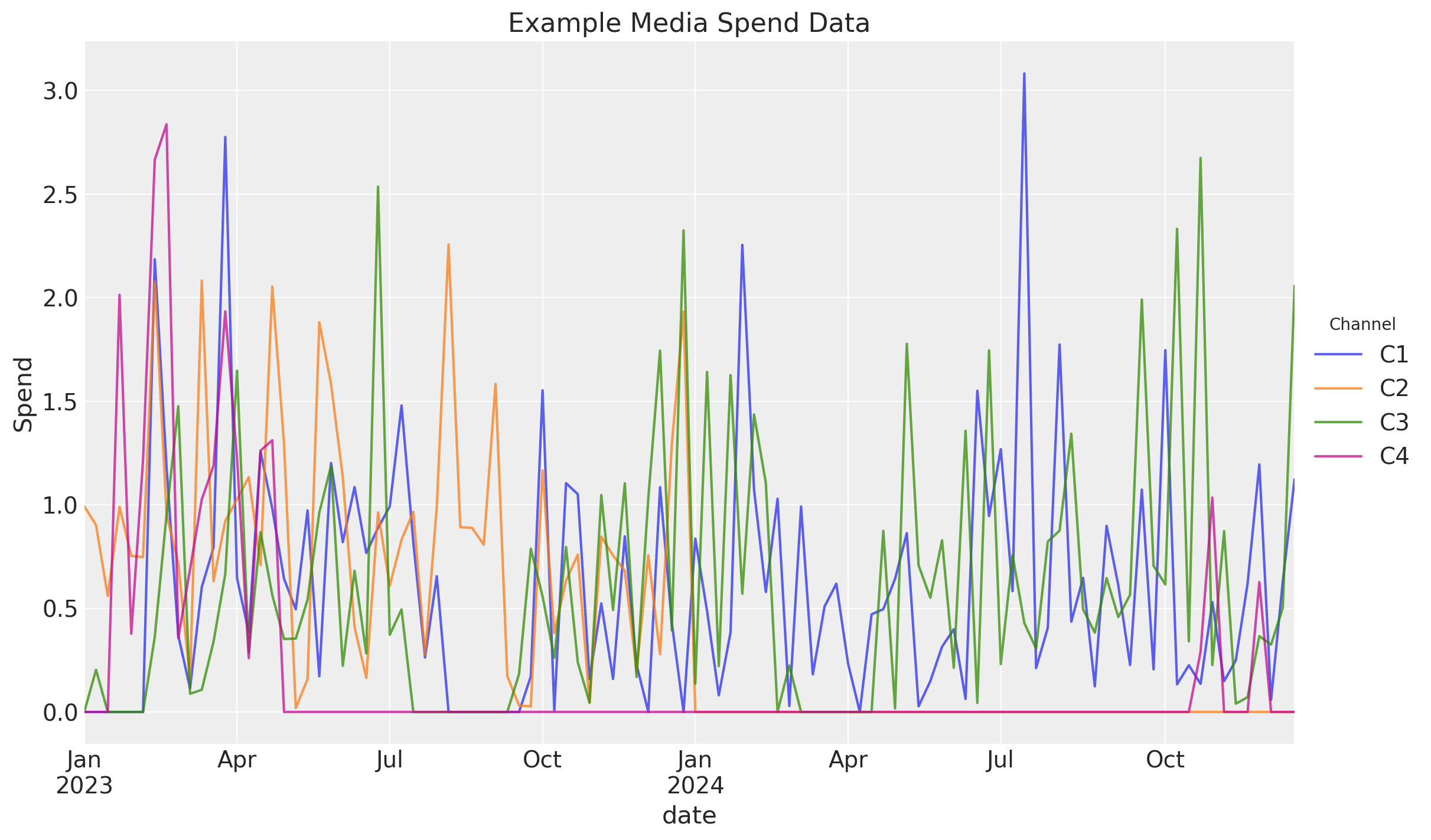
For this example, we will have 2 years of media spend for 4 channels
n_dates = 52 * 2
dates = pd.date_range("2023-01-01", periods=n_dates, freq="W-MON")
channels = ["C1", "C2", "C3", "C4"]
coords = {
"date": dates,
"channel": channels,
}
df_spends = random_spends(coords=coords).to_pandas()
df_spends.head()
| channel | C1 | C2 | C3 | C4 |
|---|---|---|---|---|
| date | ||||
| 2023-01-02 | 0.0 | 0.992756 | 0.000000 | 0.000000 |
| 2023-01-09 | 0.0 | 0.902103 | 0.203395 | 0.000000 |
| 2023-01-16 | 0.0 | 0.559487 | 0.000000 | 0.000000 |
| 2023-01-23 | 0.0 | 0.990124 | 0.000000 | 2.013755 |
| 2023-01-30 | 0.0 | 0.753384 | 0.000000 | 0.377570 |
Show code cell source
ax = df_spends.plot(title="Example Media Spend Data", ylabel="Spend", alpha=0.75)
ax.legend(title="Channel", loc="center left", bbox_to_anchor=(1, 0.5));
As mentioned, the default priors do not have a channel dimension. In order to use with the in our model with “channel” dim, we have to add the dims to each of the function priors.
for config in saturation.function_priors.values():
config["dims"] = "channel"
saturation.function_priors
{'alpha': {'dist': 'Gamma',
'kwargs': {'mu': 2, 'sigma': 1},
'dims': 'channel'},
'lam': {'dist': 'HalfNormal', 'kwargs': {'sigma': 1}, 'dims': 'channel'}}
The previous workflow can be used to understand our priors still. Just pass the coords to the sample_prior method in order to add dims to the appropriate variables.
prior = saturation.sample_prior(coords=coords, random_seed=rng)
prior
Sampling: [saturation_alpha, saturation_lam]
<xarray.Dataset> Size: 36kB
Dimensions: (chain: 1, draw: 500, channel: 4)
Coordinates:
* chain (chain) int64 8B 0
* draw (draw) int64 4kB 0 1 2 3 4 5 6 ... 494 495 496 497 498 499
* channel (channel) <U2 32B 'C1' 'C2' 'C3' 'C4'
Data variables:
saturation_alpha (chain, draw, channel) float64 16kB 1.348 2.211 ... 2.639
saturation_lam (chain, draw, channel) float64 16kB 0.6277 ... 1.778
Attributes:
created_at: 2024-06-18T07:24:58.214452
arviz_version: 0.17.0
inference_library: pymc
inference_library_version: 5.14.0Since each channel prior is the same, there will just be some noise between the HDI and curve samples.
curve = saturation.sample_curve(prior)
saturation.plot_curve(curve, subplot_kwargs={"sharey": True});
Sampling: []

Using in PyMC Model#
When using the transformation in a larger PyMC model, the apply method will be used.
This method will:
create distributions based on prior specification of the instance
apply the transformation to the data
The dims parameter is the shape of parameters and not the data. The data has a different shape but will need to be broadcastable with the parameters!
with pm.Model(coords=coords) as model:
saturated_spends = saturation.apply(df_spends, dims="channel")
Since independent alpha and lam were specified, we see that in the model graph below:
pm.model_to_graphviz(model)

Note
Neither the df_spends nor saturated_spends show in the model. If needed, use pm.Data and pm.Deterministic to save off.
Our variable will be (date, channel) dims.
saturated_spends.type.shape
(104, 4)
We can manipulate this in anyway we’d like to connect it in with the larger model.
Changing Assumptions#
As hinted above, the priors for the function parameters are customizable which can lead to many different models. Change the priors, change the model.
The prior distributions just need to follow the distribution API here.
Instead of the defaults, we can use:
hierarchical parameter for
lamparametercommon
alphaparameter
lam_distribution = {
"dist": "HalfNormal",
"kwargs": {
"sigma": {
"dist": "HalfNormal",
"kwargs": {"sigma": 1},
}
},
"dims": "channel",
}
priors = {
"lam": lam_distribution,
}
saturation = mmm.MichaelisMentenSaturation(priors=priors)
saturation.function_priors
{'alpha': {'dist': 'Gamma', 'kwargs': {'mu': 2, 'sigma': 1}},
'lam': {'dist': 'HalfNormal',
'kwargs': {'sigma': {'dist': 'HalfNormal', 'kwargs': {'sigma': 1}}},
'dims': 'channel'}}
Then this can be used in a new PyMC model which leads to a much different model graph than before!
with pm.Model(coords=coords) as model:
saturated_spends = saturation.apply(df_spends, dims="channel")
pm.model_to_graphviz(model)

The shape of the output will still be (date, channel) even though some of the parameter’s dims has changed.
saturated_spends.type.shape
(104, 4)
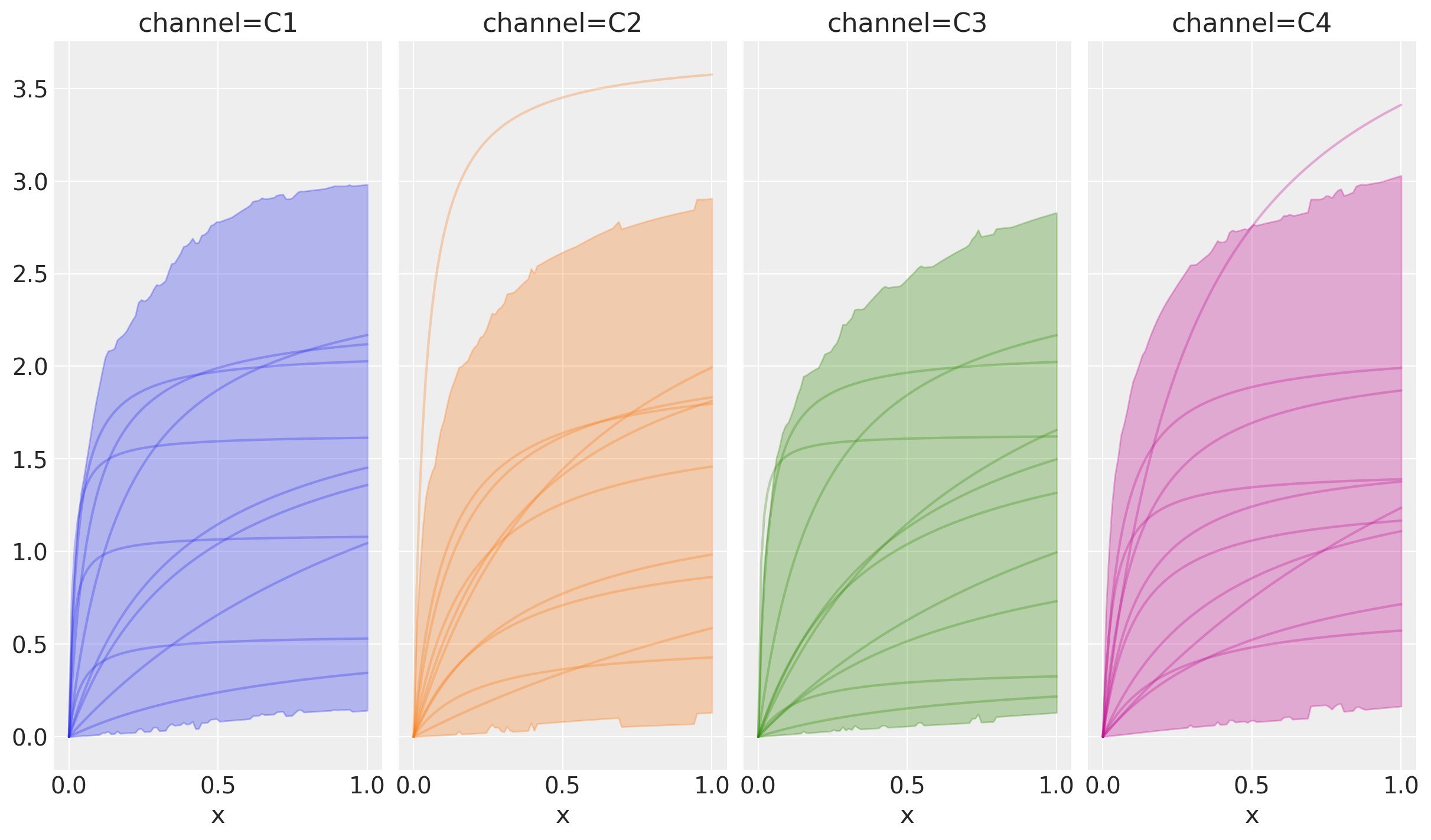
The previous workflow still helps us understand the produced curves:
sample_priorsample_curveplot_curve
prior = saturation.sample_prior(coords=coords, random_seed=rng)
Sampling: [saturation_alpha, saturation_lam, saturation_lam_sigma]
Though they all look the same in the prior, the data generation process is indeed different as seen in the model graph.
curve = saturation.sample_curve(prior)
saturation.plot_curve(curve, subplot_kwargs={"sharey": True});
Sampling: [saturation_lam, saturation_lam_sigma]
Geo Hierarchical Model#
The dimensions of the parameters are not limited to 1D so additional hierarchies can be defined.
Below defines:
alpha which is hierarchical across channels
lam which is common across all geos but different channels
# For reference
mmm.MichaelisMentenSaturation.default_priors
{'alpha': {'dist': 'Gamma', 'kwargs': {'mu': 2, 'sigma': 1}},
'lam': {'dist': 'HalfNormal', 'kwargs': {'sigma': 1}}}
priors = {
"alpha": {
"dist": "Gamma",
"kwargs": {
"mu": {"dist": "HalfNormal", "kwargs": {"sigma": 1}, "dims": "geo"},
"sigma": {"dist": "HalfNormal", "kwargs": {"sigma": 1}, "dims": "geo"},
},
"dims": ("channel", "geo"),
},
"lam": {
"dist": "HalfNormal",
"kwargs": {"sigma": 1},
"dims": "channel",
},
}
saturation = mmm.MichaelisMentenSaturation(priors=priors)
Our new data set needs to have information for geo now. This is channel spends by date and geo. This is stored in an xarray.DataArray which can be converted to a 3D numpy.ndarray.
Displaying the data is easy with pandas.
geo_coords = {
**coords,
"geo": ["Region1", "Region2", "Region3"],
}
geo_spends = random_spends(coords=geo_coords)
geo_spends.to_series().unstack("channel").head(6)
| channel | C1 | C2 | C3 | C4 | |
|---|---|---|---|---|---|
| date | geo | ||||
| 2023-01-02 | Region1 | 0.000000 | 0.000000 | 0.541483 | 0.0 |
| Region2 | 0.213863 | 0.000000 | 0.000000 | 0.0 | |
| Region3 | 1.100906 | 0.692670 | 1.493263 | 0.0 | |
| 2023-01-09 | Region1 | 0.309415 | 0.614882 | 0.818824 | 0.0 |
| Region2 | 2.264686 | 0.930828 | 0.028902 | 0.0 | |
| Region3 | 0.433401 | 0.660699 | 1.318996 | 0.0 |
As long as the dims argument of apply can broadcast with the data going in, then the media transformations can be used!
Here, the data is in the shape (date, channel, geo) so it can broadcast with the parameters in shape (channel, geo) to create the saturated spends.
with pm.Model(coords=geo_coords) as geo_model:
geo_data = pm.Data(
"geo_data",
geo_spends.to_numpy(),
dims=("date", "channel", "geo"),
)
saturated_geo_spends = pm.Deterministic(
"saturated_geo_spends",
saturation.apply(geo_data, dims=("channel", "geo")),
dims=("date", "channel", "geo"),
)
The saturation assumptions can be seen in the model graph:
pm.model_to_graphviz(geo_model)

Tip
The PyMC model context will stay the same but changing model assumptions will happen with input data and prior configuration!
Example Custom MMM#
Lots of flexibility by combining them together. This will build off the example above and now include an adstock transformation of the data as well.
def create_media_transformation(adstock, saturation, adstock_first: bool = True):
"""Flexible media transformation which allows for order to transformations."""
first, second = (adstock, saturation) if adstock_first else (saturation, adstock)
def media_transformation(x, dims):
return second.apply(first.apply(x, dims=dims), dims=dims)
return media_transformation
Our adstock function will have a hierarchical parameter for each geo. Our configuration is flexible enough to change this as long as the final dims will broadcast with the data!
# For reference
mmm.GeometricAdstock.default_priors
{'alpha': {'dist': 'Beta', 'kwargs': {'alpha': 1, 'beta': 3}}}
These are also hierarchical parameters but across a different dimensions than the saturation transformation.
priors = {
"alpha": {
"dist": "Beta",
"kwargs": {
"alpha": {"dist": "HalfNormal", "kwargs": {"sigma": 1}, "dims": "channel"},
"beta": {"dist": "HalfNormal", "kwargs": {"sigma": 1}, "dims": "channel"},
},
"dims": ("channel", "geo"),
},
}
adstock = mmm.GeometricAdstock(l_max=10, priors=priors)
media_transformation = create_media_transformation(
adstock, saturation, adstock_first=True
)
with pm.Model(coords=geo_coords) as geo_model:
geo_data = pm.Data(
"geo_data",
geo_spends.to_numpy(),
dims=("date", "channel", "geo"),
)
saturated_geo_spends = pm.Deterministic(
"channel_contributions",
media_transformation(geo_data, dims=("channel", "geo")),
dims=("date", "channel", "geo"),
)
The combined data generation process can be seen below:
pm.model_to_graphviz(geo_model)

Summary#
Custom models are possible using the components that build up the MMM class. With some prior distribution configuration and the components that PyMC-Marketing provides, novel models can be built up to fit various use-cases and various model assumptions.
Much of the flexibility will come from the prior distribution configuration rather then the transformation themselves. This is meant to keep a standard interface while working with them regardless what their role is.
If there is any suggestions or feedback on how to make better custom models with the package, create a GitHub Issue or chime into the various discussions.
Though models can be built up like this, the prebuilt structures provide many benefits as well. For instance, the MMM class provides:
scaling of input and output data
plotting methods for parameters, predictive data, contributions, etc
customized adstock and saturation transformations
out of sample predictions
lift test integration
budget optimization
Our recommendation is to start with the prebuilt models and work up from there.
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Tue Jun 18 2024
Python implementation: CPython
Python version : 3.10.13
IPython version : 8.22.2
pytensor: 2.20.0
matplotlib : 3.8.3
numpy : 1.26.4
xarray : 2024.2.0
pymc : 5.14.0
pandas : 2.2.1
pymc_marketing: 0.6.0
arviz : 0.17.0
Watermark: 2.4.3