Modelos de series de tiempo interrumpidas multivariantes#
Un enfoque de modelado que podríamos utilizar para el análisis causal de la incrementalidad del producto es el modelo de series temporales interrumpidas multivariadas (MV-ITS). Este modelo es una generalización del modelo de series temporales interrumpidas (ITS), que es un enfoque común en la inferencia causal. El modelo MV-ITS nos permite estimar el impacto causal de una intervención (por ejemplo, la introducción de un nuevo producto) en múltiples resultados (por ejemplo, las ventas de múltiples productos) simultáneamente.
Una de las diferencias entre este modelo y el enfoque estándar de modelado ITS es que, en lugar de tener una intervención binaria de apagado/encendido, la serie temporal de ventas del nuevo producto puede considerarse como una intervención graduada.
Construyendo nuestra intuición#
A continuación, describimos la versión más simple posible del modelo para desarrollar nuestra intuición antes de pasar a versiones más complejas.
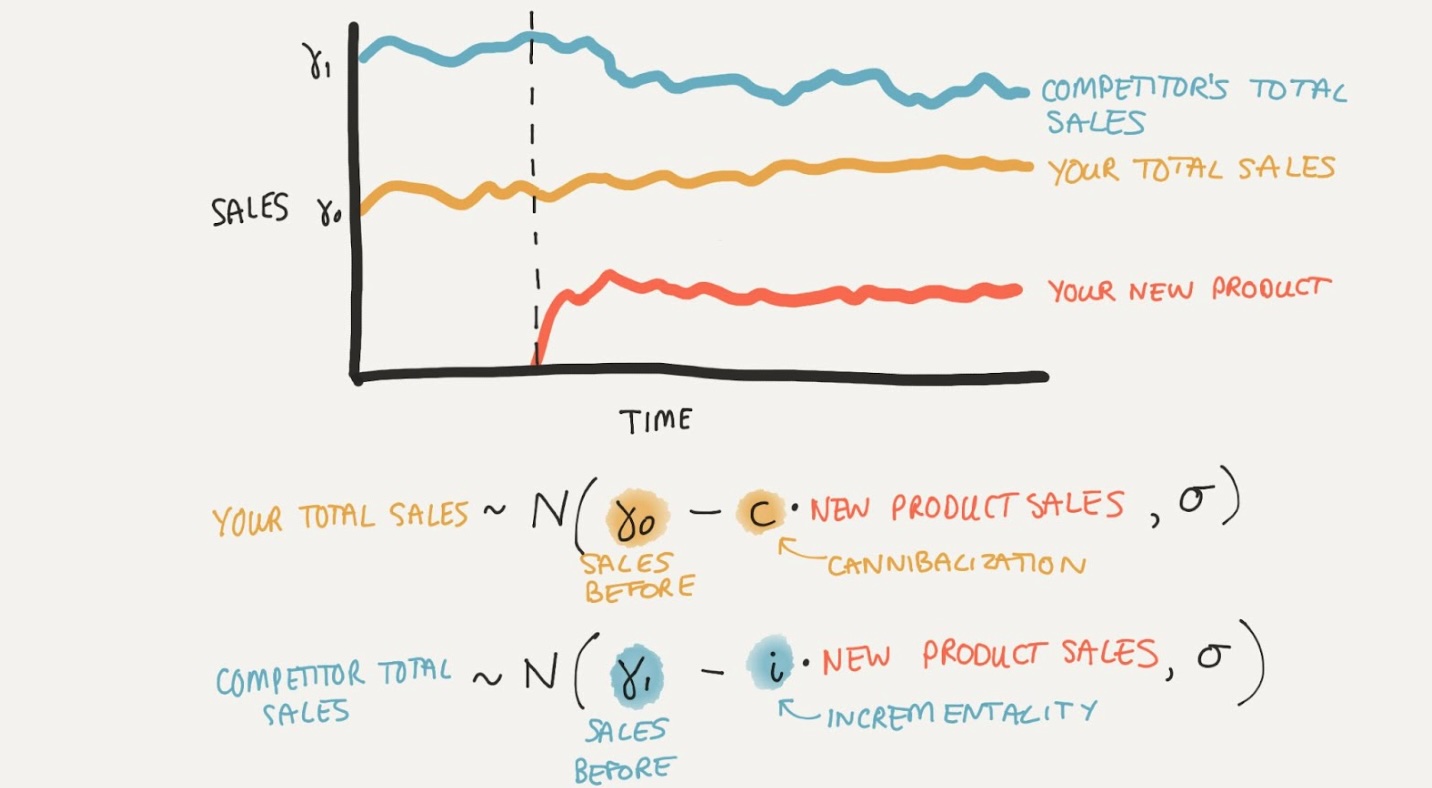
En este ejemplo, agregamos los datos de ventas en las ventas totales de su empresa y las ventas totales de sus competidores. Luego tenemos una serie temporal de datos de ventas para su empresa y sus competidores. Podemos ver que cuando lanzamos un nuevo producto, nuestras ventas no se ven realmente afectadas, pero las ventas totales de nuestros competidores disminuyen. Así que una respuesta intuitivamente correcta aquí es que nuestro nuevo producto tiene un alto nivel de incrementalidad.
El enfoque MV-ITS
El enfoque MV-ITS modela los trabajos de la siguiente manera:
Modela la serie temporal de datos de ventas para tu empresa y tus competidores.
Estas ventas se modelan como distribuidas normalmente alrededor de un valor esperado con cierto grado de ruido de observación.
La expectativa del modelo podría estar compuesta por múltiples componentes, como una tendencia, estacionalidad y el impacto de las campañas de marketing. Sin embargo, para este ejemplo simple, tenemos un modelo solo con intercepto.
Es importante destacar que la expectativa descrita anteriormente se reduce por una fracción de las ventas del nuevo producto. Esta fracción (a través de múltiples resultados de ventas) determina de dónde provienen las ventas del nuevo producto. A partir de esto, podemos calcular el nivel de incrementalidad del nuevo producto.
El modelo de mercado saturado más simple#
Empecemos con el caso más simple:
La descripción del modelo a continuación asume un mercado saturado. Es decir, las ventas de nuevos productos deben tomarse de las ventas existentes y no hay crecimiento del tamaño total del mercado.
Operamos con datos de ventas agregados en el sentido de que tenemos las ventas totales de todos tus productos y de todos los productos de tus competidores. También tenemos todos los datos de ventas del nuevo producto que lanzaste.
Comenzaremos definiendo los términos de verosimilitud del modelo:
donde \(\vec{sales}_{your}\), \(\vec{sales}_{comp}\), y \(\vec{sales}_{new}\) son las series temporales observadas de ventas de todos tus productos, los productos de tus competidores y tu nuevo producto, respectivamente.
El parámetro \(c \in [0, 1]\) es la proporción de ventas de nuevos productos que son canibalísticas, es decir, que han sido tomadas de tus productos existentes. Entonces \(1-c\) es la proporción de ventas de nuevos productos que son incrementales, es decir, que han sido tomadas de los productos de tus competidores. Podemos colocar un prior Beta sobre \(c\) para reflejar nuestras creencias previas sobre el nivel de incrementalidad del nuevo producto, por ejemplo.
Los parámetros \(\sigma_{your}\) y \(\sigma_{comp}\) son las desviaciones estándar del ruido de observación para tus ventas y las ventas de tus competidores, respectivamente. También podemos colocar priors en estos parámetros para reflejar nuestras creencias previas sobre el nivel de ruido en los datos.
Esto deja los términos \(\gamma_{your}\) y \(\gamma_{comp}\), que son términos que modelan las ventas de tus productos y los productos de tus competidores en ausencia del nuevo producto (que desde una perspectiva causal también podríamos llamar la “intervención”). Una forma de pensar en esto sería construir un modelo para las ventas antes del lanzamiento del nuevo producto. Esto podría ser un modelo simple con un término de intercepto, o un modelo más complejo con términos de tendencia y estacionalidad. En este momento solo usaremos un término de intercepto para mantener las cosas simples en este primer modelo. En este caso, \(\gamma_{your}\) y \(\gamma_{comp}\) son simplemente parámetros, términos de intercepto para tus ventas y las ventas de tus competidores, respectivamente. Nuevamente, podemos colocar priors sobre estos parámetros para reflejar nuestras creencias previas sobre el nivel de ventas en ausencia del nuevo producto, pero la forma exacta no es crucial en este momento.
Modelando productos#
Podríamos relajar una de las simplificaciones: en lugar de modelar las ventas agregadas de tus productos o de los productos de tus competidores, podríamos modelar las ventas de cada producto individualmente. Esto nos permitiría ver qué productos están más afectados por el lanzamiento del nuevo producto. Podríamos escribir los nuevos términos de probabilidad como:
TEXT: Así que ahora tenemos productos \(p=1, \ldots, P\) y podríamos modelar las ventas de cada producto individualmente. Ahora tenemos un nuevo parámetro \(\beta_i\) para cada producto, que es la proporción de ventas de nuevos productos que son canibalísticas para ese producto. Esto nos permite ver qué productos están más afectados por el lanzamiento del nuevo producto. Debido a que tenemos la suposición de que el mercado está saturado, podemos ver que la suma de los \(\beta_i\) debe ser igual a 1. Así que podría ser natural colocar un Dirichlet previo sobre los \(\beta_i\):
donde todos los \(\alpha\) hiperparámetros podrían ser 1, por ejemplo.
Mientras tengamos una lista de cuáles productos son tus productos y cuáles son los productos de tus competidores, simplemente podemos sumar los \(\beta_i\) apropiados para obtener las ventas canibalísticas e incrementales de tus productos y de los productos de tus competidores.
La forma normal multivariante
Tenga en cuenta que podría reescribir este modelo de manera equivalente como:
Podemos encarnar la suposición de que todas las ventas de productos son independientes entre sí al establecer los elementos fuera de la diagonal de la matriz de covarianza \(\Sigma\) en cero. Los elementos diagonales de la matriz de covarianza son las varianzas del ruido de observación para cada producto \([ \sigma_1, \sigma_2 \ldots, \sigma_P ]\). Así que la matriz de covarianza se vería así:
Relajando las suposiciones de independencia#
Podríamos relajar la suposición de que las ventas de tus productos y los productos de tus competidores son independientes. Podríamos modelar las ventas de tus productos y los productos de tus competidores como una distribución normal multivariante (ver cuadro arriba).
La diferencia clave sería estimar además los elementos fuera de la diagonal de la matriz de covarianza. Esto nos permitiría modelar la correlación entre las ventas de todos los productos. Esto podría requerir que pongamos más esfuerzo en especificar el prior sobre la matriz de covarianza, pero en algunas situaciones los beneficios de este enfoque podrían valer la pena. La matriz de covarianza ahora se vería así:
La desventaja de este modelo es que tendríamos muchos parámetros que estimar. Por ejemplo, si hay \(P\) productos, entonces podríamos tener que estimar \(P\) \(\beta_i\)’s y \(P\) desviaciones estándar y \(P(P-1)/2\) covarianzas. Esto no tiene por qué ser un problema; podríamos colocar priors jerárquicos sobre los \(\beta_i\)’s y las desviaciones estándar, por ejemplo, pero podría ser problemático con las covarianzas si tenemos un gran número de productos.
Moviéndose a un mercado no saturado#
Hasta ahora hemos considerado el mercado como saturado. Es decir, se asume que las ventas totales de los productos existentes se reducen en la misma cantidad que las ventas del nuevo producto.
Podríamos relajar esta suposición y considerar un mercado no saturado. Más específicamente, podríamos modelar que la reducción de ventas de los productos existentes es menor que las ventas del nuevo producto. Dicho de otra manera, la introducción de un nuevo producto conduce a una reducción en las ventas de los productos existentes pero hay ventas adicionales del nuevo producto que no provienen de una reducción en las ventas de los productos existentes.
Esto requiere solo un cambio menor en la forma normal multivariante del modelo.
Específicamente, en lugar de tener \(P\) productos que son la fuente de nuevas ventas de productos, podríamos simplemente agregar un pseudo-producto que represente nuevas ventas. Los primeros \(P\) productos son como de costumbre, todos los productos existentes. El último pseudo producto representaría el crecimiento del mercado. Podríamos simplemente agregar un parámetro adicional \(\beta\) y especificar el previo como:
El resto del modelo permanece sin cambios.
Anteriormente, la suma de los parámetros \(\beta\) sería 1, lo que significa que todas las ventas de nuevos productos provienen de productos existentes. Ahora la suma de los parámetros \(\beta\) relacionados con productos existentes (\(\beta_1, \beta_2, \ldots, \beta_P\)) podría ser menor que 1. Cuando \(\beta_{P+1}>0\), significa que el nuevo producto ha hecho que el mercado crezca: algunas de las ventas del nuevo producto no provienen de reducciones en las ventas de productos existentes.