Despliegue del modelo#
Uno de los principales objetivos de PyMC-Marketing es facilitar el despliegue de sus modelos.
Esto se logra construyendo nuestros modelos sobre ModelBuilder que ofrece una API similar a scikit-learn y facilita el despliegue de modelos PyMC.
Los modelos de PyMC-marketing heredan 2 métodos fáciles de usar: save y load que se pueden utilizar después de que el modelo ha sido ajustado. Todos los modelos se pueden configurar con dos diccionarios estándar: model_config y sampler_config que se serializan durante save y se persisten después de load, permitiendo la reutilización del modelo a través de flujos de trabajo.
Ilustraremos esta funcionalidad con el modelo de ejemplo descrito en el Cuaderno de Ejemplo MMM. Por el bien de la generalidad, omitimos la mayoría de los detalles técnicos aquí.
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pymc_extras.prior import Prior
from pymc_marketing.mmm import MMM, GeometricAdstock, LogisticSaturation
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
%config InlineBackend.figure_format = "retina"
seed = sum(map(ord, "mmm"))
rng = np.random.default_rng(seed=seed)
Carguemos el conjunto de datos:
url = "https://raw.githubusercontent.com/pymc-labs/pymc-marketing/main/data/mmm_example.csv"
df = pd.read_csv(url, parse_dates=["date_week"])
columns_to_keep = [
"date_week",
"y",
"x1",
"x2",
"event_1",
"event_2",
"dayofyear",
]
data = df[columns_to_keep].copy()
data["t"] = np.arange(df.shape[0])
data.head()
| date_week | y | x1 | x2 | event_1 | event_2 | dayofyear | t | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2018-04-02 | 3984.662237 | 0.318580 | 0.0 | 0.0 | 0.0 | 92 | 0 |
| 1 | 2018-04-09 | 3762.871794 | 0.112388 | 0.0 | 0.0 | 0.0 | 99 | 1 |
| 2 | 2018-04-16 | 4466.967388 | 0.292400 | 0.0 | 0.0 | 0.0 | 106 | 2 |
| 3 | 2018-04-23 | 3864.219373 | 0.071399 | 0.0 | 0.0 | 0.0 | 113 | 3 |
| 4 | 2018-04-30 | 4441.625278 | 0.386745 | 0.0 | 0.0 | 0.0 | 120 | 4 |
Pero para nuestro modelo necesitamos un conjunto de datos mucho más pequeño, muchas de las características anteriores estaban contribuyendo a la generación de otras, ahora que nuestra variable objetivo se ha calculado podemos filtrar las columnas que no son necesarias:
Configuración del modelo y muestreo#
Configuración del modelo#
Primero ilustramos el uso de model_config para definir priors personalizados dentro del modelo.
Porque hay potencialmente muchas variables que se pueden configurar, cada modelo proporciona un atributo default_model_config. Esto te permitirá ver qué configuraciones están disponibles por defecto y solo definir las que necesitas cambiar.
Necesitamos crear un modelo ficticio para poder ver el diccionario de configuración.
adstock = GeometricAdstock(l_max=8)
saturation = LogisticSaturation()
dummy_model = MMM(
date_column="date_week",
channel_columns=["x1", "x2"],
adstock=adstock,
saturation=saturation,
control_columns=[
"event_1",
"event_2",
"t",
],
yearly_seasonality=2,
)
dummy_model.default_model_config
{'intercept': Prior("Normal", mu=0, sigma=2),
'likelihood': Prior("Normal", sigma=Prior("HalfNormal", sigma=2)),
'gamma_control': Prior("Normal", mu=0, sigma=2, dims="control"),
'gamma_fourier': Prior("Laplace", mu=0, b=1, dims="fourier_mode"),
'adstock_alpha': Prior("Beta", alpha=1, beta=3, dims="channel"),
'saturation_lam': Prior("Gamma", alpha=3, beta=1, dims="channel"),
'saturation_beta': Prior("HalfNormal", sigma=2, dims="channel")}
Podemos cambiar los parámetros que se utilizan en la distribución de cada término. En este caso, simplemente reemplazaremos el sigma por saturation_beta con uno personalizado:
n_channels = 2
total_spend_per_channel = data[["x1", "x2"]].sum(axis=0)
spend_share = total_spend_per_channel / total_spend_per_channel.sum()
# The scale necessary to make a HalfNormal distribution have unit variance
HALFNORMAL_SCALE = 1 / np.sqrt(1 - 2 / np.pi)
prior_sigma = HALFNORMAL_SCALE * n_channels * spend_share.to_numpy()
prior_sigma
array([2.1775326 , 1.14026088])
saturation_beta = Prior("HalfNormal", sigma=prior_sigma, dims="channel")
my_model_config = {"saturation_beta": saturation_beta}
my_model_config
{'saturation_beta': Prior("HalfNormal", sigma=[2.1775326 1.14026088], dims="channel")}
Como se mencionó en el cuaderno original: «Para la especificación previa no hay una respuesta correcta o incorrecta. Todo depende de los datos, el contexto y las suposiciones que estés dispuesto a hacer. Siempre se recomienda hacer un muestreo predictivo previo y un análisis de sensibilidad para verificar el impacto de las priors en el posterior. Saltamos esto aquí por el bien de la simplicidad. Si no estás seguro sobre priors específicos, la clase MMM tiene algunos priors predeterminados que puedes usar como punto de partida.»
Configuración de muestreo#
La segunda característica que podemos personalizar es sampler_config. Similar a model_config, es un diccionario que se guarda y contiene cosas que normalmente pasarías a los kwargs de fit(). No es obligatorio crear tu propio sampler_config. El MMM.sampler_config por defecto está vacío porque los parámetros de muestreo por defecto suelen ser suficientes para comenzar.
dummy_model.default_sampler_config
{}
my_sampler_config = {
"tune": 1000,
"draws": 1000,
"chains": 4,
"target_accept": 0.91,
"nuts_sampler": "numpyro",
}
¡Finalmente ensamblamos nuestro modelo!
mmm = MMM(
model_config=my_model_config,
sampler_config=my_sampler_config,
date_column="date_week",
channel_columns=["x1", "x2"],
adstock=adstock,
saturation=saturation,
control_columns=[
"event_1",
"event_2",
"t",
],
yearly_seasonality=2,
)
Podemos confirmar que se están utilizando nuestras configuraciones.
mmm.model_config["saturation_beta"]
Prior("HalfNormal", sigma=[2.1775326 1.14026088], dims="channel")
mmm.sampler_config
{'tune': 1000,
'draws': 1000,
'chains': 4,
'target_accept': 0.91,
'nuts_sampler': 'numpyro'}
Ajuste del modelo#
Nota que no pasamos el conjunto de datos al constructor de la clase en sí. Esto se hace para imitar la API de scikit-learn y facilitar el inicio en los modelos de PyMC-Marketing.
# Split X, and y
X = data.drop("y", axis=1)
y = data["y"]
Todo lo que queda ahora es finalmente ajustar el modelo:
Como puedes ver a continuación, aún puedes pasar los kwargs del muestreador directamente al método fit(). Sin embargo, solo aquellos kwargs pasados usando sampler_config serán guardados y reutilizados después de cargar el modelo.
mmm.fit(X=X, y=y, random_seed=rng)
-
- chain: 4
- draw: 1000
- control: 3
- fourier_mode: 4
- channel: 2
- date: 179
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 5 ... 995 996 997 998 999
array([ 0, 1, 2, ..., 997, 998, 999])
- control(control)<U7'event_1' 'event_2' 't'
array(['event_1', 'event_2', 't'], dtype='<U7')
- fourier_mode(fourier_mode)<U5'sin_1' 'sin_2' 'cos_1' 'cos_2'
array(['sin_1', 'sin_2', 'cos_1', 'cos_2'], dtype='<U5')
- channel(channel)<U2'x1' 'x2'
array(['x1', 'x2'], dtype='<U2')
- date(date)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', '2019-01-07T00:00:00.000000000', '2019-01-14T00:00:00.000000000', '2019-01-21T00:00:00.000000000', '2019-01-28T00:00:00.000000000', '2019-02-04T00:00:00.000000000', '2019-02-11T00:00:00.000000000', '2019-02-18T00:00:00.000000000', '2019-02-25T00:00:00.000000000', '2019-03-04T00:00:00.000000000', '2019-03-11T00:00:00.000000000', '2019-03-18T00:00:00.000000000', '2019-03-25T00:00:00.000000000', '2019-04-01T00:00:00.000000000', '2019-04-08T00:00:00.000000000', '2019-04-15T00:00:00.000000000', '2019-04-22T00:00:00.000000000', '2019-04-29T00:00:00.000000000', '2019-05-06T00:00:00.000000000', '2019-05-13T00:00:00.000000000', '2019-05-20T00:00:00.000000000', '2019-05-27T00:00:00.000000000', '2019-06-03T00:00:00.000000000', '2019-06-10T00:00:00.000000000', '2019-06-17T00:00:00.000000000', '2019-06-24T00:00:00.000000000', '2019-07-01T00:00:00.000000000', '2019-07-08T00:00:00.000000000', '2019-07-15T00:00:00.000000000', '2019-07-22T00:00:00.000000000', '2019-07-29T00:00:00.000000000', '2019-08-05T00:00:00.000000000', '2019-08-12T00:00:00.000000000', '2019-08-19T00:00:00.000000000', '2019-08-26T00:00:00.000000000', '2019-09-02T00:00:00.000000000', '2019-09-09T00:00:00.000000000', '2019-09-16T00:00:00.000000000', '2019-09-23T00:00:00.000000000', '2019-09-30T00:00:00.000000000', '2019-10-07T00:00:00.000000000', '2019-10-14T00:00:00.000000000', '2019-10-21T00:00:00.000000000', '2019-10-28T00:00:00.000000000', '2019-11-04T00:00:00.000000000', '2019-11-11T00:00:00.000000000', '2019-11-18T00:00:00.000000000', '2019-11-25T00:00:00.000000000', '2019-12-02T00:00:00.000000000', '2019-12-09T00:00:00.000000000', '2019-12-16T00:00:00.000000000', '2019-12-23T00:00:00.000000000', '2019-12-30T00:00:00.000000000', '2020-01-06T00:00:00.000000000', '2020-01-13T00:00:00.000000000', '2020-01-20T00:00:00.000000000', '2020-01-27T00:00:00.000000000', '2020-02-03T00:00:00.000000000', '2020-02-10T00:00:00.000000000', '2020-02-17T00:00:00.000000000', '2020-02-24T00:00:00.000000000', '2020-03-02T00:00:00.000000000', '2020-03-09T00:00:00.000000000', '2020-03-16T00:00:00.000000000', '2020-03-23T00:00:00.000000000', '2020-03-30T00:00:00.000000000', '2020-04-06T00:00:00.000000000', '2020-04-13T00:00:00.000000000', '2020-04-20T00:00:00.000000000', '2020-04-27T00:00:00.000000000', '2020-05-04T00:00:00.000000000', '2020-05-11T00:00:00.000000000', '2020-05-18T00:00:00.000000000', '2020-05-25T00:00:00.000000000', '2020-06-01T00:00:00.000000000', '2020-06-08T00:00:00.000000000', '2020-06-15T00:00:00.000000000', '2020-06-22T00:00:00.000000000', '2020-06-29T00:00:00.000000000', '2020-07-06T00:00:00.000000000', '2020-07-13T00:00:00.000000000', '2020-07-20T00:00:00.000000000', '2020-07-27T00:00:00.000000000', '2020-08-03T00:00:00.000000000', '2020-08-10T00:00:00.000000000', '2020-08-17T00:00:00.000000000', '2020-08-24T00:00:00.000000000', '2020-08-31T00:00:00.000000000', '2020-09-07T00:00:00.000000000', '2020-09-14T00:00:00.000000000', '2020-09-21T00:00:00.000000000', '2020-09-28T00:00:00.000000000', '2020-10-05T00:00:00.000000000', '2020-10-12T00:00:00.000000000', '2020-10-19T00:00:00.000000000', '2020-10-26T00:00:00.000000000', '2020-11-02T00:00:00.000000000', '2020-11-09T00:00:00.000000000', '2020-11-16T00:00:00.000000000', '2020-11-23T00:00:00.000000000', '2020-11-30T00:00:00.000000000', '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]')
- intercept(chain, draw)float640.3241 0.3462 ... 0.3452 0.3423
array([[0.32406678, 0.34619647, 0.34946238, ..., 0.36017873, 0.36364648, 0.34211201], [0.34297333, 0.36458607, 0.36305035, ..., 0.33153195, 0.32648402, 0.34689344], [0.35538442, 0.34876222, 0.3400557 , ..., 0.34048732, 0.36433433, 0.34712521], [0.34653625, 0.34949441, 0.34821141, ..., 0.34792694, 0.34519334, 0.34231005]]) - gamma_control(chain, draw, control)float640.2444 0.2986 ... 0.2807 0.0006254
array([[[0.24442176, 0.29861242, 0.00072677], [0.29257094, 0.31640118, 0.00061519], [0.29728759, 0.33418332, 0.00067896], ..., [0.23872646, 0.33049203, 0.00061568], [0.24268897, 0.33045391, 0.00058077], [0.24983399, 0.33552453, 0.00055499]], [[0.22704413, 0.25684749, 0.00062875], [0.27251037, 0.29577431, 0.0005847 ], [0.26730817, 0.28312486, 0.00057571], ..., [0.24769467, 0.3111828 , 0.00059493], [0.25269611, 0.3182666 , 0.00063728], [0.25365855, 0.30168336, 0.00065024]], [[0.21227108, 0.2928598 , 0.00054851], [0.25580358, 0.30173479, 0.00062438], [0.22743417, 0.28359657, 0.00062732], ..., [0.21719658, 0.32878429, 0.00066653], [0.24974847, 0.32583108, 0.00063815], [0.21038605, 0.35550874, 0.00064522]], [[0.25045293, 0.32619178, 0.00060629], [0.2707071 , 0.31504205, 0.00067208], [0.26584232, 0.269338 , 0.00059683], ..., [0.2166309 , 0.27594761, 0.00064141], [0.20106656, 0.26520393, 0.00070353], [0.21866508, 0.28069877, 0.00062543]]]) - gamma_fourier(chain, draw, fourier_mode)float640.0007724 -0.06061 ... -0.003132
array([[[ 7.72378808e-04, -6.06081570e-02, 6.32651251e-02, -2.01114377e-03], [ 9.96871005e-04, -5.86696713e-02, 6.20015874e-02, -1.34957454e-03], [ 2.78543874e-03, -5.91531137e-02, 6.28186476e-02, 1.23215028e-03], ..., [ 1.09308961e-02, -5.52255837e-02, 5.53657488e-02, 4.06550058e-03], [ 1.01287922e-02, -5.45675206e-02, 5.54975548e-02, 4.80993995e-03], [-1.82057929e-03, -5.67813999e-02, 6.74055087e-02, -4.77966242e-04]], [[-7.51961183e-04, -5.86088163e-02, 6.99076644e-02, 5.51497132e-03], [ 6.89727412e-03, -5.43440801e-02, 5.83835597e-02, -4.96441715e-04], [ 4.72784938e-03, -5.10017479e-02, 5.88479576e-02, -2.03822960e-04], ... [ 2.45021147e-03, -6.18282104e-02, 6.03125031e-02, -2.61392124e-04], [ 5.13255670e-03, -5.59025608e-02, 6.18636645e-02, 1.62105766e-03], [ 2.93775206e-03, -5.63428785e-02, 6.09074908e-02, 6.94092174e-03]], [[ 4.04566016e-04, -5.24779710e-02, 5.68171569e-02, -1.14227587e-03], [ 3.00933140e-03, -5.86054466e-02, 6.97586385e-02, -9.87345554e-05], [ 3.80797985e-03, -5.87374919e-02, 6.48225474e-02, -3.92531564e-03], ..., [-3.01772993e-03, -5.50307089e-02, 6.47225183e-02, 2.47184808e-03], [ 4.25596483e-04, -5.84699367e-02, 6.60252484e-02, -5.38060536e-03], [-3.71017805e-03, -5.73044070e-02, 5.67166184e-02, -3.13215242e-03]]]) - adstock_alpha(chain, draw, channel)float640.4468 0.1246 ... 0.4151 0.2179
array([[[0.44678044, 0.12461885], [0.43940092, 0.11574963], [0.42688628, 0.07674649], ..., [0.412239 , 0.21451786], [0.40217029, 0.2023283 ], [0.37723098, 0.14994939]], [[0.3738777 , 0.18442894], [0.43561957, 0.22804777], [0.42895391, 0.25879418], ..., [0.39633751, 0.21297114], [0.40366376, 0.23518666], [0.4398461 , 0.20269349]], [[0.4015843 , 0.1868227 ], [0.40945581, 0.21108652], [0.4010663 , 0.20394772], ..., [0.44732677, 0.14938899], [0.39170829, 0.19147519], [0.41338947, 0.19456145]], [[0.41149561, 0.15391603], [0.45110995, 0.22269684], [0.46353293, 0.18878952], ..., [0.4713076 , 0.18355891], [0.4405482 , 0.18488228], [0.41509309, 0.21794455]]]) - saturation_lam(chain, draw, channel)float643.866 4.382 4.017 ... 3.655 3.112
array([[[3.8664679 , 4.3822459 ], [4.01697237, 5.003845 ], [3.46829185, 6.71698576], ..., [3.86860499, 1.9513025 ], [3.79728533, 2.23915015], [4.54663146, 3.26044198]], [[4.63015095, 2.41940406], [3.83650437, 3.08048179], [3.70979051, 2.65448979], ..., [4.65145926, 2.5143236 ], [4.79699316, 2.25997681], [3.63499734, 2.46720476]], [[4.01248188, 3.17819848], [4.02747406, 2.89137585], [4.4275353 , 3.29558325], ..., [3.57758012, 3.71414201], [3.59328546, 3.51946369], [4.17169924, 3.24657569]], [[3.38978669, 2.59500796], [3.17237872, 3.41789036], [3.18373805, 3.22026436], ..., [3.63722205, 2.49821975], [3.51596054, 2.71652159], [3.65516329, 3.11221716]]]) - saturation_beta(chain, draw, channel)float640.4163 0.208 ... 0.3982 0.2519
array([[[0.41626701, 0.20802294], [0.37481779, 0.21153649], [0.40060792, 0.20025627], ..., [0.34451547, 0.33184141], [0.34894712, 0.30627982], [0.36452861, 0.231014 ]], [[0.35516922, 0.26077286], [0.34654678, 0.242997 ], [0.36425293, 0.2645556 ], ..., [0.35922902, 0.27072243], [0.35925855, 0.30673295], [0.39677358, 0.2771929 ]], [[0.36482536, 0.23342183], [0.35803484, 0.26115968], [0.35628967, 0.23817916], ..., [0.40585395, 0.2264985 ], [0.36555962, 0.22381165], [0.35701154, 0.24064578]], [[0.41339001, 0.26849517], [0.41982109, 0.23371085], [0.42931902, 0.24232727], ..., [0.39779643, 0.26927112], [0.39489904, 0.2601883 ], [0.39819555, 0.2518974 ]]]) - y_sigma(chain, draw)float640.0307 0.02867 ... 0.02949 0.02912
array([[0.03069617, 0.02866503, 0.03113925, ..., 0.03104758, 0.03081779, 0.02892369], [0.03029061, 0.02866137, 0.02772262, ..., 0.02691624, 0.02858276, 0.0283407 ], [0.03098302, 0.02930196, 0.02883407, ..., 0.02824263, 0.03214303, 0.03270503], [0.03228296, 0.03013216, 0.030262 , ..., 0.02906735, 0.02948853, 0.02911568]]) - channel_contributions(chain, draw, date, channel)float640.1372 0.0 ... 0.2258 0.002755
array([[[[1.37212326e-01, 0.00000000e+00], [1.11199429e-01, 0.00000000e+00], [1.71007656e-01, 0.00000000e+00], ..., [1.16674015e-01, 4.25633383e-02], [1.68565397e-01, 5.37893130e-03], [2.41577564e-01, 6.70442138e-04]], [[1.29527877e-01, 0.00000000e+00], [1.04198269e-01, 0.00000000e+00], [1.60054784e-01, 0.00000000e+00], ..., [1.09283274e-01, 4.62727148e-02], [1.57729818e-01, 5.44281615e-03], [2.24870877e-01, 6.30127381e-04]], [[1.23279518e-01, 0.00000000e+00], [9.73487830e-02, 0.00000000e+00], [1.51440025e-01, 0.00000000e+00], ..., ... ..., [1.04048343e-01, 4.33930862e-02], [1.50041016e-01, 8.03284839e-03], [2.16606305e-01, 1.47460029e-03]], [[1.20372275e-01, 0.00000000e+00], [9.66280534e-02, 0.00000000e+00], [1.49697234e-01, 0.00000000e+00], ..., [1.01409036e-01, 4.57700468e-02], [1.47464482e-01, 8.54793624e-03], [2.13772945e-01, 1.58055202e-03]], [[1.31108520e-01, 0.00000000e+00], [1.02230037e-01, 0.00000000e+00], [1.59026691e-01, 0.00000000e+00], ..., [1.07379983e-01, 5.70321112e-02], [1.56524203e-01, 1.26383894e-02], [2.25810950e-01, 2.75524666e-03]]]]) - control_contributions(chain, draw, date, control)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.1113
array([[[[0. , 0. , 0. ], [0. , 0. , 0.00072677], [0. , 0. , 0.00145355], ..., [0. , 0. , 0.12791198], [0. , 0. , 0.12863876], [0. , 0. , 0.12936553]], [[0. , 0. , 0. ], [0. , 0. , 0.00061519], [0. , 0. , 0.00123037], ..., [0. , 0. , 0.10827294], [0. , 0. , 0.10888813], [0. , 0. , 0.10950331]], [[0. , 0. , 0. ], [0. , 0. , 0.00067896], [0. , 0. , 0.00135793], ..., ... ..., [0. , 0. , 0.11288826], [0. , 0. , 0.11352967], [0. , 0. , 0.11417108]], [[0. , 0. , 0. ], [0. , 0. , 0.00070353], [0. , 0. , 0.00140706], ..., [0. , 0. , 0.12382172], [0. , 0. , 0.12452525], [0. , 0. , 0.12522878]], [[0. , 0. , 0. ], [0. , 0. , 0.00062543], [0. , 0. , 0.00125085], ..., [0. , 0. , 0.11007508], [0. , 0. , 0.1107005 ], [0. , 0. , 0.11132593]]]]) - fourier_contributions(chain, draw, date, fourier_mode)float640.0007723 0.001433 ... 0.001424
array([[[[ 7.72324792e-04, 1.43346072e-03, -7.48203040e-04, 2.01058119e-03], [ 7.65634814e-04, 1.58438498e-02, -8.34204809e-03, 1.94120954e-03], [ 7.47856359e-04, 2.93397136e-02, -1.58150776e-02, 1.75978906e-03], ..., [-5.43505476e-04, -6.06053195e-02, -4.49511149e-02, -1.94605543e-05], [-6.05493903e-04, -5.89960896e-02, -3.92777950e-02, 4.60762299e-04], [-6.58712951e-04, -5.39815478e-02, -3.30356440e-02, 9.14388000e-04]], [[ 9.96801288e-04, 1.38761305e-03, -7.33259852e-04, 1.34919702e-03], [ 9.88166867e-04, 1.53371015e-02, -8.17543984e-03, 1.30264530e-03], [ 9.65221097e-04, 2.84013149e-02, -1.54992172e-02, 1.18090340e-03], ... [-2.99482607e-04, -5.84671993e-02, -4.69122368e-02, -5.20646830e-05], [-3.33639495e-04, -5.69147421e-02, -4.09914019e-02, 1.23272147e-03], [-3.62964277e-04, -5.20771104e-02, -3.44769192e-02, 2.44634971e-03]], [[-3.70991858e-03, 1.35532279e-03, -6.70757329e-04, 3.13127626e-03], [-3.67778279e-03, 1.49802017e-02, -7.47857145e-03, 3.02323696e-03], [-3.59238268e-03, 2.77404061e-02, -1.41780755e-02, 2.74069296e-03], ..., [ 2.61076828e-03, -5.73017242e-02, -4.02982722e-02, -3.03078393e-05], [ 2.90853422e-03, -5.57802134e-02, -3.52121916e-02, 7.17590544e-04], [ 3.16417580e-03, -5.10390142e-02, -2.96161592e-02, 1.42406656e-03]]]]) - yearly_seasonality_contribution(chain, draw, date)float640.003468 0.01021 ... -0.07607
array([[[ 3.46816366e-03, 1.02086460e-02, 1.60322815e-02, ..., -1.06119400e-01, -9.84186161e-02, -8.67615168e-02], [ 3.00035151e-03, 9.45247386e-03, 1.50482222e-02, ..., -1.03434806e-01, -9.60747861e-02, -8.48674293e-02], [ 2.20956262e-03, 8.75211767e-03, 1.45507253e-02, ..., -1.05732356e-01, -9.90462408e-02, -8.84238300e-02], ..., [ 7.51714298e-03, 1.40476434e-02, 1.99201458e-02, ..., -1.02213936e-01, -9.76307195e-02, -8.92689368e-02], [ 5.95374117e-03, 1.23445833e-02, 1.81405997e-02, ..., -1.01077928e-01, -9.66137487e-02, -8.84060530e-02], [-7.96835577e-04, 4.61214973e-03, 9.29258202e-03, ..., -1.03395205e-01, -9.55827280e-02, -8.40008815e-02]], [[-5.70592429e-03, 3.46766874e-05, 5.34247787e-03, ..., -1.07694339e-01, -1.01125723e-01, -9.05711768e-02], [ 7.98793051e-03, 1.38241871e-02, 1.88252536e-02, ..., -1.00682462e-01, -9.44389982e-02, -8.45454900e-02], [ 5.44157795e-03, 1.04562923e-02, 1.47345841e-02, ..., -9.61408435e-02, -8.98402396e-02, -8.00939682e-02], ... [ 3.46039172e-03, 1.08911899e-02, 1.74544914e-02, ..., -1.06405222e-01, -9.94892856e-02, -8.85328421e-02], [ 4.10213217e-03, 9.97953922e-03, 1.51481950e-02, ..., -1.03451271e-01, -9.72183366e-02, -8.72085353e-02], [-3.38917268e-03, 2.91020899e-03, 8.82026944e-03, ..., -1.01616277e-01, -9.65515313e-02, -8.76483412e-02]], [[ 2.11571910e-03, 7.73026178e-03, 1.25920101e-02, ..., -9.31409579e-02, -8.64122146e-02, -7.62346169e-02], [ 3.66892356e-03, 9.20039566e-03, 1.39320741e-02, ..., -1.10286140e-01, -1.02692400e-01, -9.11457943e-02], [ 8.35452639e-03, 1.43709731e-02, 1.93515478e-02, ..., -1.07510008e-01, -9.95057891e-02, -8.76272059e-02], ..., [-4.95256745e-03, 4.74331851e-04, 5.37550347e-03, ..., -9.88673272e-02, -9.19502119e-02, -8.13607954e-02], [ 6.40671047e-03, 1.21942781e-02, 1.69197860e-02, ..., -1.05730983e-01, -9.70070621e-02, -8.44706442e-02], [ 1.05923143e-04, 6.84708440e-03, 1.27106409e-02, ..., -9.50195359e-02, -8.73662803e-02, -7.60669311e-02]]]) - mu(chain, draw, date)float640.4647 0.4462 ... 0.5348 0.6061
array([[[0.46474727, 0.44620163, 0.51256026, ..., 0.50509671, 0.52823125, 0.6089188 ], [0.4787247 , 0.4604624 , 0.52252985, ..., 0.50659059, 0.52218244, 0.59633336], [0.47495146, 0.45624224, 0.51681106, ..., 0.50621588, 0.52285358, 0.59858872], ..., [0.487753 , 0.46830311, 0.52626435, ..., 0.5115629 , 0.52435921, 0.58698488], [0.49100426, 0.46989264, 0.52829058, ..., 0.5106196 , 0.52258915, 0.58585843], [0.49592587, 0.46355153, 0.53227731, ..., 0.50038475, 0.52804129, 0.60461137]], [[0.49103563, 0.45893585, 0.52770221, ..., 0.5086166 , 0.53617477, 0.60942857], [0.48806945, 0.47138003, 0.52707625, ..., 0.51993382, 0.52705826, 0.58844434], [0.4874414 , 0.46840611, 0.52498356, ..., 0.52482575, 0.53406601, 0.59649896], ... [0.46828274, 0.45268407, 0.51479321, ..., 0.50279644, 0.51916815, 0.59336936], [0.49124997, 0.46798815, 0.52670338, ..., 0.52324639, 0.53378362, 0.60012157], [0.4767618 , 0.4546553 , 0.51748189, ..., 0.52053944, 0.53291674, 0.59989125]], [[0.4762611 , 0.45373693, 0.51500661, ..., 0.50313277, 0.52567964, 0.60063911], [0.46725959, 0.45190743, 0.50857547, ..., 0.51346739, 0.52082854, 0.58854668], [0.47116508, 0.45748746, 0.5149135 , ..., 0.49603376, 0.50829492, 0.57970088], ..., [0.46179461, 0.44792396, 0.50655411, ..., 0.5093893 , 0.52758026, 0.59881813], [0.47197232, 0.4547192 , 0.51321743, ..., 0.51046316, 0.52872395, 0.60130498], [0.47352449, 0.4520126 , 0.51529823, ..., 0.52177768, 0.53480686, 0.60613524]]])
- chainPandasIndex
PandasIndex(Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 990, 991, 992, 993, 994, 995, 996, 997, 998, 999], dtype='int64', name='draw', length=1000)) - controlPandasIndex
PandasIndex(Index(['event_1', 'event_2', 't'], dtype='object', name='control'))
- fourier_modePandasIndex
PandasIndex(Index(['sin_1', 'sin_2', 'cos_1', 'cos_2'], dtype='object', name='fourier_mode'))
- channelPandasIndex
PandasIndex(Index(['x1', 'x2'], dtype='object', name='channel'))
- datePandasIndex
PandasIndex(DatetimeIndex(['2018-04-02', '2018-04-09', '2018-04-16', '2018-04-23', '2018-04-30', '2018-05-07', '2018-05-14', '2018-05-21', '2018-05-28', '2018-06-04', ... '2021-06-28', '2021-07-05', '2021-07-12', '2021-07-19', '2021-07-26', '2021-08-02', '2021-08-09', '2021-08-16', '2021-08-23', '2021-08-30'], dtype='datetime64[ns]', name='date', length=179, freq=None))
- created_at :
- 2024-11-14T13:56:50.170234
- arviz_version :
- 0.17.1
<xarray.Dataset> Size: 63MB Dimensions: (chain: 4, draw: 1000, control: 3, fourier_mode: 4, channel: 2, date: 179) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 ... 997 998 999 * control (control) <U7 84B 'event_1' 'event_2' 't' * fourier_mode (fourier_mode) <U5 80B 'sin_1' ... 'cos_2' * channel (channel) <U2 16B 'x1' 'x2' * date (date) datetime64[ns] 1kB 2018-04-02 ...... Data variables: intercept (chain, draw) float64 32kB 0.3241 ... 0.... gamma_control (chain, draw, control) float64 96kB 0.24... gamma_fourier (chain, draw, fourier_mode) float64 128kB ... adstock_alpha (chain, draw, channel) float64 64kB 0.44... saturation_lam (chain, draw, channel) float64 64kB 3.86... saturation_beta (chain, draw, channel) float64 64kB 0.41... y_sigma (chain, draw) float64 32kB 0.0307 ... 0.... channel_contributions (chain, draw, date, channel) float64 11MB ... control_contributions (chain, draw, date, control) float64 17MB ... fourier_contributions (chain, draw, date, fourier_mode) float64 23MB ... yearly_seasonality_contribution (chain, draw, date) float64 6MB 0.003468... mu (chain, draw, date) float64 6MB 0.4647 .... Attributes: created_at: 2024-11-14T13:56:50.170234 arviz_version: 0.17.1xarray.Dataset -
- chain: 4
- draw: 1000
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 5 ... 995 996 997 998 999
array([ 0, 1, 2, ..., 997, 998, 999])
- acceptance_rate(chain, draw)float640.9682 0.9951 ... 0.9999 0.9654
array([[0.96817757, 0.99508228, 0.99666656, ..., 0.87885314, 0.97430639, 0.99512293], [0.88237998, 0.98283383, 0.99986125, ..., 0.99166592, 0.99996833, 0.99909432], [0.86197359, 0.995431 , 0.99321992, ..., 0.95921727, 0.90199914, 0.78631235], [0.91222462, 0.99675826, 0.71182102, ..., 0.96484441, 0.99989372, 0.96540128]]) - step_size(chain, draw)float640.00572 0.00572 ... 0.005936
array([[0.00572014, 0.00572014, 0.00572014, ..., 0.00572014, 0.00572014, 0.00572014], [0.00515522, 0.00515522, 0.00515522, ..., 0.00515522, 0.00515522, 0.00515522], [0.00693266, 0.00693266, 0.00693266, ..., 0.00693266, 0.00693266, 0.00693266], [0.00593638, 0.00593638, 0.00593638, ..., 0.00593638, 0.00593638, 0.00593638]]) - diverging(chain, draw)boolFalse False False ... False False
array([[False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False]]) - energy(chain, draw)float64-337.8 -349.0 ... -340.3 -345.5
array([[-337.84405072, -349.03892588, -347.52658904, ..., -334.57220422, -345.02966482, -347.66356081], [-337.56831667, -343.17815709, -341.18420695, ..., -350.03646254, -349.74645907, -348.88517697], [-341.76236676, -350.07737547, -348.83769446, ..., -346.80225259, -346.4906293 , -346.77305053], [-341.98272981, -342.11445535, -338.95220358, ..., -341.58235877, -340.33901742, -345.51640744]]) - n_steps(chain, draw)int641023 511 511 511 ... 1023 511 511
array([[1023, 511, 511, ..., 511, 511, 511], [ 511, 511, 511, ..., 511, 511, 1023], [ 511, 511, 511, ..., 511, 511, 511], [ 511, 511, 511, ..., 1023, 511, 511]]) - tree_depth(chain, draw)int6410 9 9 9 9 9 9 ... 10 10 9 9 10 9 9
array([[10, 9, 9, ..., 9, 9, 9], [ 9, 9, 9, ..., 9, 9, 10], [ 9, 9, 9, ..., 9, 9, 9], [ 9, 9, 9, ..., 10, 9, 9]]) - lp(chain, draw)float64-352.0 -355.9 ... -352.2 -352.1
array([[-352.03686551, -355.85803022, -352.43212434, ..., -351.2449381 , -352.55989494, -353.89315019], [-348.92446089, -352.02017042, -349.94597102, ..., -355.4467677 , -355.47706339, -353.72276215], [-355.3382039 , -355.90952294, -354.74608244, ..., -355.53130143, -356.30140898, -354.52648169], [-347.39494536, -350.24373127, -349.82371935, ..., -350.55418291, -352.17001019, -352.06965338]])
- chainPandasIndex
PandasIndex(Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 990, 991, 992, 993, 994, 995, 996, 997, 998, 999], dtype='int64', name='draw', length=1000))
- created_at :
- 2024-11-14T13:56:50.174899
- arviz_version :
- 0.17.1
<xarray.Dataset> Size: 204kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 ... 994 995 996 997 998 999 Data variables: acceptance_rate (chain, draw) float64 32kB 0.9682 0.9951 ... 0.9999 0.9654 step_size (chain, draw) float64 32kB 0.00572 0.00572 ... 0.005936 diverging (chain, draw) bool 4kB False False False ... False False energy (chain, draw) float64 32kB -337.8 -349.0 ... -340.3 -345.5 n_steps (chain, draw) int64 32kB 1023 511 511 511 ... 1023 511 511 tree_depth (chain, draw) int64 32kB 10 9 9 9 9 9 9 ... 10 9 9 10 9 9 lp (chain, draw) float64 32kB -352.0 -355.9 ... -352.2 -352.1 Attributes: created_at: 2024-11-14T13:56:50.174899 arviz_version: 0.17.1xarray.Dataset -
- date: 179
- date(date)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', '2019-01-07T00:00:00.000000000', '2019-01-14T00:00:00.000000000', '2019-01-21T00:00:00.000000000', '2019-01-28T00:00:00.000000000', '2019-02-04T00:00:00.000000000', '2019-02-11T00:00:00.000000000', '2019-02-18T00:00:00.000000000', '2019-02-25T00:00:00.000000000', '2019-03-04T00:00:00.000000000', '2019-03-11T00:00:00.000000000', '2019-03-18T00:00:00.000000000', '2019-03-25T00:00:00.000000000', '2019-04-01T00:00:00.000000000', '2019-04-08T00:00:00.000000000', '2019-04-15T00:00:00.000000000', '2019-04-22T00:00:00.000000000', '2019-04-29T00:00:00.000000000', '2019-05-06T00:00:00.000000000', '2019-05-13T00:00:00.000000000', '2019-05-20T00:00:00.000000000', '2019-05-27T00:00:00.000000000', '2019-06-03T00:00:00.000000000', '2019-06-10T00:00:00.000000000', '2019-06-17T00:00:00.000000000', '2019-06-24T00:00:00.000000000', '2019-07-01T00:00:00.000000000', '2019-07-08T00:00:00.000000000', '2019-07-15T00:00:00.000000000', '2019-07-22T00:00:00.000000000', '2019-07-29T00:00:00.000000000', '2019-08-05T00:00:00.000000000', '2019-08-12T00:00:00.000000000', '2019-08-19T00:00:00.000000000', '2019-08-26T00:00:00.000000000', '2019-09-02T00:00:00.000000000', '2019-09-09T00:00:00.000000000', '2019-09-16T00:00:00.000000000', '2019-09-23T00:00:00.000000000', '2019-09-30T00:00:00.000000000', '2019-10-07T00:00:00.000000000', '2019-10-14T00:00:00.000000000', '2019-10-21T00:00:00.000000000', '2019-10-28T00:00:00.000000000', '2019-11-04T00:00:00.000000000', '2019-11-11T00:00:00.000000000', '2019-11-18T00:00:00.000000000', '2019-11-25T00:00:00.000000000', '2019-12-02T00:00:00.000000000', '2019-12-09T00:00:00.000000000', '2019-12-16T00:00:00.000000000', '2019-12-23T00:00:00.000000000', '2019-12-30T00:00:00.000000000', '2020-01-06T00:00:00.000000000', '2020-01-13T00:00:00.000000000', '2020-01-20T00:00:00.000000000', '2020-01-27T00:00:00.000000000', '2020-02-03T00:00:00.000000000', '2020-02-10T00:00:00.000000000', '2020-02-17T00:00:00.000000000', '2020-02-24T00:00:00.000000000', '2020-03-02T00:00:00.000000000', '2020-03-09T00:00:00.000000000', '2020-03-16T00:00:00.000000000', '2020-03-23T00:00:00.000000000', '2020-03-30T00:00:00.000000000', '2020-04-06T00:00:00.000000000', '2020-04-13T00:00:00.000000000', '2020-04-20T00:00:00.000000000', '2020-04-27T00:00:00.000000000', '2020-05-04T00:00:00.000000000', '2020-05-11T00:00:00.000000000', '2020-05-18T00:00:00.000000000', '2020-05-25T00:00:00.000000000', '2020-06-01T00:00:00.000000000', '2020-06-08T00:00:00.000000000', '2020-06-15T00:00:00.000000000', '2020-06-22T00:00:00.000000000', '2020-06-29T00:00:00.000000000', '2020-07-06T00:00:00.000000000', '2020-07-13T00:00:00.000000000', '2020-07-20T00:00:00.000000000', '2020-07-27T00:00:00.000000000', '2020-08-03T00:00:00.000000000', '2020-08-10T00:00:00.000000000', '2020-08-17T00:00:00.000000000', '2020-08-24T00:00:00.000000000', '2020-08-31T00:00:00.000000000', '2020-09-07T00:00:00.000000000', '2020-09-14T00:00:00.000000000', '2020-09-21T00:00:00.000000000', '2020-09-28T00:00:00.000000000', '2020-10-05T00:00:00.000000000', '2020-10-12T00:00:00.000000000', '2020-10-19T00:00:00.000000000', '2020-10-26T00:00:00.000000000', '2020-11-02T00:00:00.000000000', '2020-11-09T00:00:00.000000000', '2020-11-16T00:00:00.000000000', '2020-11-23T00:00:00.000000000', '2020-11-30T00:00:00.000000000', '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]')
- y(date)float640.4794 0.4527 ... 0.5388 0.5625
array([0.47936319, 0.45268134, 0.53738551, 0.46487367, 0.5343368 , 0.44239849, 0.60963642, 0.73132832, 0.59600126, 0.70565315, 0.61313561, 0.60049297, 0.56404656, 0.78633605, 0.60523784, 0.5580442 , 0.50641716, 0.586594 , 0.46992062, 0.42705583, 0.48426812, 0.38777049, 0.49079078, 0.50002789, 0.44113299, 0.46359002, 0.42484345, 0.42573496, 0.5126282 , 0.55393305, 0.7801562 , 0.61244259, 0.7820166 , 0.7741081 , 0.87677312, 0.63147717, 0.51546283, 0.71272935, 0.93485537, 0.79408756, 0.72228448, 0.68098843, 0.70650313, 0.73308506, 0.4805125 , 0.57954561, 0.93776656, 0.77561424, 0.66655529, 0.59547518, 0.76751515, 0.57312122, 0.50621332, 0.5308715 , 0.52295261, 0.79720566, 0.62933004, 0.46812934, 0.81995741, 0.60723799, 0.63667661, 0.63023046, 0.60081393, 0.54905189, 0.54151156, 0.67785878, 0.580275 , 0.48759392, 0.54008438, 0.7454827 , 0.4601459 , 0.47552149, 0.71676648, 0.72228072, 0.54215422, 0.85509146, 0.684061 , 0.56992491, 0.84343218, 0.58108193, 0.57400488, 0.7216718 , 0.70124307, 0.70769822, 0.89872242, 0.8115083 , 0.72059583, 0.57222288, 1. , 0.8366832 , 0.99252741, 0.70215306, 0.69084327, 0.71206105, 0.64219547, 0.81993542, 0.6896944 , 0.59591584, 0.6458122 , 0.50792736, 0.55944542, 0.63420523, 0.70343723, 0.7740387 , 0.70204359, 0.65253863, 0.81871625, 0.81911895, 0.68380948, 0.71220965, 0.54236837, 0.58017503, 0.6352586 , 0.62739849, 0.92329765, 0.85928619, 0.62316379, 0.56392299, 0.55616857, 0.4257328 , 0.43070972, 0.52466263, 0.54561821, 0.5264453 , 0.41628475, 0.49557027, 0.53537871, 0.53003824, 0.78154262, 0.53440301, 0.63876159, 0.59727845, 0.57348504, 0.72266752, 0.88323619, 0.67509495, 0.68280629, 0.76882837, 0.66983526, 0.70381398, 0.73990877, 0.6594292 , 0.83865735, 0.73595323, 0.56852858, 0.62116609, 0.52960021, 0.67721404, 0.65454618, 0.57113219, 0.55954835, 0.68309668, 0.64092662, 0.61267177, 0.58478466, 0.63905178, 0.56741971, 0.58706316, 0.63111636, 0.84924442, 0.89647751, 0.84943539, 0.68420327, 0.82623974, 0.70912897, 0.66280698, 0.60631287, 0.61775646, 0.54565334, 0.52431821, 0.77688667, 0.53243718, 0.45656482, 0.38411009, 0.42749903, 0.66954245, 0.49776812, 0.53883804, 0.56252938])
- datePandasIndex
PandasIndex(DatetimeIndex(['2018-04-02', '2018-04-09', '2018-04-16', '2018-04-23', '2018-04-30', '2018-05-07', '2018-05-14', '2018-05-21', '2018-05-28', '2018-06-04', ... '2021-06-28', '2021-07-05', '2021-07-12', '2021-07-19', '2021-07-26', '2021-08-02', '2021-08-09', '2021-08-16', '2021-08-23', '2021-08-30'], dtype='datetime64[ns]', name='date', length=179, freq=None))
- created_at :
- 2024-11-14T13:56:50.176001
- arviz_version :
- 0.17.1
- inference_library :
- numpyro
- inference_library_version :
- 0.15.2
- sampling_time :
- 14.669591
<xarray.Dataset> Size: 3kB Dimensions: (date: 179) Coordinates: * date (date) datetime64[ns] 1kB 2018-04-02 2018-04-09 ... 2021-08-30 Data variables: y (date) float64 1kB 0.4794 0.4527 0.5374 ... 0.4978 0.5388 0.5625 Attributes: created_at: 2024-11-14T13:56:50.176001 arviz_version: 0.17.1 inference_library: numpyro inference_library_version: 0.15.2 sampling_time: 14.669591xarray.Dataset -
- date: 179
- channel: 2
- control: 3
- date(date)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', '2019-01-07T00:00:00.000000000', '2019-01-14T00:00:00.000000000', '2019-01-21T00:00:00.000000000', '2019-01-28T00:00:00.000000000', '2019-02-04T00:00:00.000000000', '2019-02-11T00:00:00.000000000', '2019-02-18T00:00:00.000000000', '2019-02-25T00:00:00.000000000', '2019-03-04T00:00:00.000000000', '2019-03-11T00:00:00.000000000', '2019-03-18T00:00:00.000000000', '2019-03-25T00:00:00.000000000', '2019-04-01T00:00:00.000000000', '2019-04-08T00:00:00.000000000', '2019-04-15T00:00:00.000000000', '2019-04-22T00:00:00.000000000', '2019-04-29T00:00:00.000000000', '2019-05-06T00:00:00.000000000', '2019-05-13T00:00:00.000000000', '2019-05-20T00:00:00.000000000', '2019-05-27T00:00:00.000000000', '2019-06-03T00:00:00.000000000', '2019-06-10T00:00:00.000000000', '2019-06-17T00:00:00.000000000', '2019-06-24T00:00:00.000000000', '2019-07-01T00:00:00.000000000', '2019-07-08T00:00:00.000000000', '2019-07-15T00:00:00.000000000', '2019-07-22T00:00:00.000000000', '2019-07-29T00:00:00.000000000', '2019-08-05T00:00:00.000000000', '2019-08-12T00:00:00.000000000', '2019-08-19T00:00:00.000000000', '2019-08-26T00:00:00.000000000', '2019-09-02T00:00:00.000000000', '2019-09-09T00:00:00.000000000', '2019-09-16T00:00:00.000000000', '2019-09-23T00:00:00.000000000', '2019-09-30T00:00:00.000000000', '2019-10-07T00:00:00.000000000', '2019-10-14T00:00:00.000000000', '2019-10-21T00:00:00.000000000', '2019-10-28T00:00:00.000000000', '2019-11-04T00:00:00.000000000', '2019-11-11T00:00:00.000000000', '2019-11-18T00:00:00.000000000', '2019-11-25T00:00:00.000000000', '2019-12-02T00:00:00.000000000', '2019-12-09T00:00:00.000000000', '2019-12-16T00:00:00.000000000', '2019-12-23T00:00:00.000000000', '2019-12-30T00:00:00.000000000', '2020-01-06T00:00:00.000000000', '2020-01-13T00:00:00.000000000', '2020-01-20T00:00:00.000000000', '2020-01-27T00:00:00.000000000', '2020-02-03T00:00:00.000000000', '2020-02-10T00:00:00.000000000', '2020-02-17T00:00:00.000000000', '2020-02-24T00:00:00.000000000', '2020-03-02T00:00:00.000000000', '2020-03-09T00:00:00.000000000', '2020-03-16T00:00:00.000000000', '2020-03-23T00:00:00.000000000', '2020-03-30T00:00:00.000000000', '2020-04-06T00:00:00.000000000', '2020-04-13T00:00:00.000000000', '2020-04-20T00:00:00.000000000', '2020-04-27T00:00:00.000000000', '2020-05-04T00:00:00.000000000', '2020-05-11T00:00:00.000000000', '2020-05-18T00:00:00.000000000', '2020-05-25T00:00:00.000000000', '2020-06-01T00:00:00.000000000', '2020-06-08T00:00:00.000000000', '2020-06-15T00:00:00.000000000', '2020-06-22T00:00:00.000000000', '2020-06-29T00:00:00.000000000', '2020-07-06T00:00:00.000000000', '2020-07-13T00:00:00.000000000', '2020-07-20T00:00:00.000000000', '2020-07-27T00:00:00.000000000', '2020-08-03T00:00:00.000000000', '2020-08-10T00:00:00.000000000', '2020-08-17T00:00:00.000000000', '2020-08-24T00:00:00.000000000', '2020-08-31T00:00:00.000000000', '2020-09-07T00:00:00.000000000', '2020-09-14T00:00:00.000000000', '2020-09-21T00:00:00.000000000', '2020-09-28T00:00:00.000000000', '2020-10-05T00:00:00.000000000', '2020-10-12T00:00:00.000000000', '2020-10-19T00:00:00.000000000', '2020-10-26T00:00:00.000000000', '2020-11-02T00:00:00.000000000', '2020-11-09T00:00:00.000000000', '2020-11-16T00:00:00.000000000', '2020-11-23T00:00:00.000000000', '2020-11-30T00:00:00.000000000', '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]') - channel(channel)<U2'x1' 'x2'
array(['x1', 'x2'], dtype='<U2')
- control(control)<U7'event_1' 'event_2' 't'
array(['event_1', 'event_2', 't'], dtype='<U7')
- channel_data(date, channel)float640.3196 0.0 0.1128 ... 0.4403 0.0
array([[3.19648241e-01, 0.00000000e+00], [1.12765324e-01, 0.00000000e+00], [2.93380707e-01, 0.00000000e+00], [7.16379574e-02, 0.00000000e+00], [3.88041940e-01, 0.00000000e+00], [4.73291540e-02, 0.00000000e+00], [4.25671645e-01, 0.00000000e+00], [3.35039834e-01, 8.84759215e-01], [2.53918849e-01, 0.00000000e+00], [9.41199784e-01, 0.00000000e+00], [4.26630818e-01, 0.00000000e+00], [3.64360623e-01, 0.00000000e+00], [4.42975062e-01, 0.00000000e+00], [4.24530352e-01, 9.69641782e-01], [3.29493374e-01, 0.00000000e+00], [9.25031639e-01, 0.00000000e+00], [3.09048312e-01, 0.00000000e+00], [9.12534800e-01, 0.00000000e+00], [2.51539259e-01, 0.00000000e+00], [2.37266186e-01, 0.00000000e+00], ... [1.70332079e-01, 9.38381372e-01], [4.29038699e-01, 9.20516422e-01], [9.13487319e-01, 0.00000000e+00], [1.42944657e-01, 0.00000000e+00], [1.86838303e-01, 8.55514629e-01], [3.14421972e-01, 0.00000000e+00], [4.00678428e-01, 0.00000000e+00], [1.45069138e-01, 0.00000000e+00], [1.48471239e-01, 0.00000000e+00], [7.00777532e-02, 0.00000000e+00], [1.99103276e-01, 0.00000000e+00], [3.62700587e-01, 9.14000224e-01], [2.41143360e-01, 0.00000000e+00], [4.05094103e-02, 0.00000000e+00], [6.76832332e-02, 0.00000000e+00], [3.31349195e-02, 0.00000000e+00], [1.66170470e-01, 8.68233263e-01], [1.72458556e-01, 0.00000000e+00], [2.81197012e-01, 0.00000000e+00], [4.40328682e-01, 0.00000000e+00]]) - control_data(date, control)float640.0 0.0 0.0 0.0 ... 0.0 0.0 178.0
array([[ 0., 0., 0.], [ 0., 0., 1.], [ 0., 0., 2.], [ 0., 0., 3.], [ 0., 0., 4.], [ 0., 0., 5.], [ 0., 0., 6.], [ 0., 0., 7.], [ 0., 0., 8.], [ 0., 0., 9.], [ 0., 0., 10.], [ 0., 0., 11.], [ 0., 0., 12.], [ 0., 0., 13.], [ 0., 0., 14.], [ 0., 0., 15.], [ 0., 0., 16.], [ 0., 0., 17.], [ 0., 0., 18.], [ 0., 0., 19.], ... [ 0., 0., 159.], [ 0., 0., 160.], [ 0., 0., 161.], [ 0., 0., 162.], [ 0., 0., 163.], [ 0., 0., 164.], [ 0., 0., 165.], [ 0., 0., 166.], [ 0., 0., 167.], [ 0., 0., 168.], [ 0., 0., 169.], [ 0., 0., 170.], [ 0., 0., 171.], [ 0., 0., 172.], [ 0., 0., 173.], [ 0., 0., 174.], [ 0., 0., 175.], [ 0., 0., 176.], [ 0., 0., 177.], [ 0., 0., 178.]]) - dayofyear(date)int3292 99 106 113 ... 221 228 235 242
array([ 92, 99, 106, 113, 120, 127, 134, 141, 148, 155, 162, 169, 176, 183, 190, 197, 204, 211, 218, 225, 232, 239, 246, 253, 260, 267, 274, 281, 288, 295, 302, 309, 316, 323, 330, 337, 344, 351, 358, 365, 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84, 91, 98, 105, 112, 119, 126, 133, 140, 147, 154, 161, 168, 175, 182, 189, 196, 203, 210, 217, 224, 231, 238, 245, 252, 259, 266, 273, 280, 287, 294, 301, 308, 315, 322, 329, 336, 343, 350, 357, 364, 6, 13, 20, 27, 34, 41, 48, 55, 62, 69, 76, 83, 90, 97, 104, 111, 118, 125, 132, 139, 146, 153, 160, 167, 174, 181, 188, 195, 202, 209, 216, 223, 230, 237, 244, 251, 258, 265, 272, 279, 286, 293, 300, 307, 314, 321, 328, 335, 342, 349, 356, 363, 4, 11, 18, 25, 32, 39, 46, 53, 60, 67, 74, 81, 88, 95, 102, 109, 116, 123, 130, 137, 144, 151, 158, 165, 172, 179, 186, 193, 200, 207, 214, 221, 228, 235, 242], dtype=int32)
- datePandasIndex
PandasIndex(DatetimeIndex(['2018-04-02', '2018-04-09', '2018-04-16', '2018-04-23', '2018-04-30', '2018-05-07', '2018-05-14', '2018-05-21', '2018-05-28', '2018-06-04', ... '2021-06-28', '2021-07-05', '2021-07-12', '2021-07-19', '2021-07-26', '2021-08-02', '2021-08-09', '2021-08-16', '2021-08-23', '2021-08-30'], dtype='datetime64[ns]', name='date', length=179, freq=None)) - channelPandasIndex
PandasIndex(Index(['x1', 'x2'], dtype='object', name='channel'))
- controlPandasIndex
PandasIndex(Index(['event_1', 'event_2', 't'], dtype='object', name='control'))
- created_at :
- 2024-11-14T13:56:50.177660
- arviz_version :
- 0.17.1
- inference_library :
- numpyro
- inference_library_version :
- 0.15.2
- sampling_time :
- 14.669591
<xarray.Dataset> Size: 9kB Dimensions: (date: 179, channel: 2, control: 3) Coordinates: * date (date) datetime64[ns] 1kB 2018-04-02 2018-04-09 ... 2021-08-30 * channel (channel) <U2 16B 'x1' 'x2' * control (control) <U7 84B 'event_1' 'event_2' 't' Data variables: channel_data (date, channel) float64 3kB 0.3196 0.0 0.1128 ... 0.4403 0.0 control_data (date, control) float64 4kB 0.0 0.0 0.0 0.0 ... 0.0 0.0 178.0 dayofyear (date) int32 716B 92 99 106 113 120 ... 214 221 228 235 242 Attributes: created_at: 2024-11-14T13:56:50.177660 arviz_version: 0.17.1 inference_library: numpyro inference_library_version: 0.15.2 sampling_time: 14.669591xarray.Dataset -
- index: 179
- index(index)int640 1 2 3 4 5 ... 174 175 176 177 178
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178])
- date_week(index)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', ... '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]') - x1(index)float640.3186 0.1124 ... 0.2803 0.4389
array([3.18580018e-01, 1.12388476e-01, 2.92400266e-01, 7.13985526e-02, 3.86745154e-01, 4.71709861e-02, 4.24249105e-01, 3.33920175e-01, 2.53070285e-01, 9.38054416e-01, 4.25205073e-01, 3.63142977e-01, 4.41494696e-01, 4.23111626e-01, 3.28392249e-01, 9.21940303e-01, 3.08015512e-01, 9.09485226e-01, 2.50698647e-01, 2.36473273e-01, 4.03137932e-01, 1.47177719e-01, 3.63041014e-01, 1.47066490e-01, 9.46704311e-02, 2.59245305e-01, 5.74838249e-02, 2.06465328e-02, 1.65636049e-01, 2.14007141e-01, 3.60517692e-01, 1.22368556e-01, 9.58683953e-01, 3.21972344e-01, 2.53234055e-01, 6.40119796e-02, 2.36553200e-02, 1.83164569e-01, 9.25302245e-01, 9.96658129e-01, 4.01689634e-01, 1.73745461e-01, 9.55372645e-01, 3.55889419e-01, 9.29181335e-04, 4.37815667e-01, 9.73976316e-01, 9.77903945e-01, 2.48141704e-01, 4.05620409e-01, 2.49040963e-01, 5.30524844e-02, 6.63217207e-02, 9.19314691e-02, 2.84652565e-01, 3.73845327e-01, 3.11033721e-01, 1.08200596e-02, 3.25854693e-01, 4.30160827e-01, 4.42189999e-01, 2.68919050e-01, 3.84406892e-01, 3.03780772e-01, 2.22092463e-01, 9.84087017e-01, 1.78161753e-01, 1.52862615e-01, 4.32812209e-01, 3.80735892e-01, 1.33810881e-01, 2.18715931e-01, 3.24034681e-01, 3.66676692e-01, 1.50298760e-01, 9.31123777e-01, 2.99199062e-01, 1.59348190e-01, 4.49282836e-01, 9.18307179e-03, ... 2.83962083e-01, 4.29271667e-01, 1.55574946e-01, 1.07068213e-01, 4.46958034e-01, 3.53012159e-01, 4.05501510e-01, 9.95101996e-01, 1.95552073e-01, 4.21105629e-01, 3.89127721e-02, 2.74762370e-01, 3.88551689e-01, 3.98177912e-01, 9.30166751e-01, 2.59848823e-01, 1.94820914e-01, 2.58231310e-01, 3.02189662e-01, 1.03497234e-01, 8.01700983e-02, 4.15976836e-01, 3.96173495e-01, 4.43288434e-01, 6.38882192e-02, 2.56961240e-01, 4.16716500e-01, 1.89344301e-01, 1.21168779e-02, 3.07204390e-01, 2.79346139e-01, 1.55859670e-01, 2.51259804e-01, 4.15636348e-01, 1.50413447e-01, 4.18457229e-02, 2.92710243e-01, 3.91623929e-01, 9.89705226e-02, 2.68473040e-01, 3.63484578e-01, 1.85363200e-01, 6.59774982e-02, 3.54568453e-01, 1.59422721e-01, 1.81976239e-01, 1.16747054e-01, 3.23780216e-01, 4.34122877e-01, 1.08988007e-01, 1.61353829e-01, 9.42322052e-01, 8.52032642e-02, 3.25819647e-01, 1.67913280e-01, 3.39621958e-01, 2.52901858e-01, 8.64855399e-02, 3.37226955e-01, 1.69762852e-01, 4.27604907e-01, 9.10434562e-01, 1.42466955e-01, 1.86213914e-01, 3.13371214e-01, 3.99339412e-01, 1.44584335e-01, 1.47975068e-01, 6.98435624e-02, 1.98437898e-01, 3.61488489e-01, 2.40337490e-01, 4.03740331e-02, 6.74570446e-02, 3.30241869e-02, 1.65615150e-01, 1.71882222e-01, 2.80257288e-01, 4.38857161e-01]) - x2(index)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0
array([0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.87978184, 0. , 0. , 0. , 0. , 0. , 0.96418688, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.80062317, 0. , 0. , 0. , 0.8535269 , 0. , 0. , 0.98859712, 0.87047511, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.9748662 , 0. , 0. , 0. , 0.90257287, 0. , 0. , 0. , 0. , 0.99437431, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.95798229, 0. , 0. , 0.88604706, 0.84193305, 0. , 0.91253659, 0. , 0. , 0.99123254, 0. , 0. , 0.95581799, 0.91704461, 0. , 0.80904352, 0. , 0. , 0. , 0.86960149, 0. , 0.9208528 , 0. , 0. , 0. , 0. , 0.99390622, 0. , 0. , 0. , 0. , 0. , 0. , 0.93665676, 0.9093652 , 0. , 0. , 0.80688306, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.89397651, 0.86774976, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.83998152, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.96018382, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.93310233, 0.91533788, 0. , 0. , 0.85070177, 0. , 0. , 0. , 0. , 0. , 0. , 0.90885834, 0. , 0. , 0. , 0. , 0.86334885, 0. , 0. , 0. ]) - event_1(index)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) - event_2(index)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) - dayofyear(index)int6492 99 106 113 ... 221 228 235 242
array([ 92, 99, 106, 113, 120, 127, 134, 141, 148, 155, 162, 169, 176, 183, 190, 197, 204, 211, 218, 225, 232, 239, 246, 253, 260, 267, 274, 281, 288, 295, 302, 309, 316, 323, 330, 337, 344, 351, 358, 365, 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84, 91, 98, 105, 112, 119, 126, 133, 140, 147, 154, 161, 168, 175, 182, 189, 196, 203, 210, 217, 224, 231, 238, 245, 252, 259, 266, 273, 280, 287, 294, 301, 308, 315, 322, 329, 336, 343, 350, 357, 364, 6, 13, 20, 27, 34, 41, 48, 55, 62, 69, 76, 83, 90, 97, 104, 111, 118, 125, 132, 139, 146, 153, 160, 167, 174, 181, 188, 195, 202, 209, 216, 223, 230, 237, 244, 251, 258, 265, 272, 279, 286, 293, 300, 307, 314, 321, 328, 335, 342, 349, 356, 363, 4, 11, 18, 25, 32, 39, 46, 53, 60, 67, 74, 81, 88, 95, 102, 109, 116, 123, 130, 137, 144, 151, 158, 165, 172, 179, 186, 193, 200, 207, 214, 221, 228, 235, 242]) - t(index)int640 1 2 3 4 5 ... 174 175 176 177 178
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178]) - y(index)float643.985e+03 3.763e+03 ... 4.676e+03
array([3984.66223734, 3762.87179412, 4466.96738844, 3864.21937266, 4441.62527775, 3677.39655018, 5067.54633687, 6079.09904219, 4954.20536859, 5865.67657627, 5096.63305051, 4991.54228314, 4688.5848447 , 6536.34574052, 5030.98358508, 4638.69083472, 4209.54579837, 4876.00838907, 3906.171689 , 3549.86212243, 4025.43395537, 3223.30633321, 4079.65295872, 4156.43557336, 3666.8772267 , 3853.54920598, 3531.47191787, 3538.8824745 , 4261.17449177, 4604.51723377, 6484.97624603, 5090.8724376 , 6500.44070675, 6434.7020032 , 7288.09549867, 5249.09562308, 4284.73710406, 5924.4967947 , 7770.89886433, 6600.77946045, 6003.92292284, 5660.65332884, 5872.74193171, 6093.70178134, 3994.21575864, 4817.41932661, 7795.0978095 , 6447.22166693, 5540.6792271 , 4949.83235925, 6379.8986888 , 4764.01718599, 4207.85140173, 4412.82026656, 4346.99520328, 6626.69831268, 5231.24779003, 3891.28186583, 6815.82014683, 5047.60961099, 5292.31541818, 5238.73239384, 4994.21021861, 4563.9431011 , 4501.26480448, 5634.63844969, 4823.48226687, 4053.07938257, 4489.40147834, 6196.75603817, 3824.9202315 , 3952.72844853, 5958.05509279, 6003.89166699, 4506.60683165, 7107.8687139 , 5686.19380778, 4737.44808553, 7010.95204787, 4830.18985388, ... 4650.33832006, 5271.77236249, 5847.25691642, 6434.12509649, 5835.67243843, 5424.16703016, 6805.503155 , 6808.85054468, 5684.10310247, 5920.17689413, 4508.38691899, 4822.65128872, 5280.52839424, 5215.19196501, 7674.82634251, 7142.73704187, 5179.99140594, 4687.55775271, 4623.09983189, 3538.8645019 , 3580.23476566, 4361.20963926, 4535.40095043, 4376.02791122, 3460.32851473, 4119.38208881, 4450.28600415, 4405.89387854, 6496.50077682, 4442.17560168, 5309.6466714 , 4964.82187487, 4767.04140224, 6007.10694272, 7341.81915474, 5611.66436779, 5675.76416319, 6390.81472343, 5567.94366983, 5850.38866634, 6150.42324303, 5481.44428281, 6971.26166534, 6117.54314155, 4725.84123847, 5163.38572629, 4402.2528145 , 5629.27905386, 5440.85463743, 4747.48354262, 4651.19391143, 5678.17799695, 5327.64323813, 5092.77743153, 4860.96843213, 5312.05880983, 4716.62387739, 4879.90820541, 5246.0963942 , 7059.26575537, 7451.88641636, 7060.8531078 , 5687.37638691, 6868.04144218, 5894.56896391, 5509.52170002, 5039.91969411, 5135.04343508, 4535.6929473 , 4358.34664039, 6457.79858878, 4425.83485865, 3795.15282441, 3192.87959337, 3553.54614781, 5565.50968216, 4137.65148493, 4479.04135141, 4675.97343867])
- indexPandasIndex
PandasIndex(RangeIndex(start=0, stop=179, step=1, name='index'))
<xarray.Dataset> Size: 13kB Dimensions: (index: 179) Coordinates: * index (index) int64 1kB 0 1 2 3 4 5 6 7 ... 172 173 174 175 176 177 178 Data variables: date_week (index) datetime64[ns] 1kB 2018-04-02 2018-04-09 ... 2021-08-30 x1 (index) float64 1kB 0.3186 0.1124 0.2924 ... 0.1719 0.2803 0.4389 x2 (index) float64 1kB 0.0 0.0 0.0 0.0 0.0 ... 0.8633 0.0 0.0 0.0 event_1 (index) float64 1kB 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 event_2 (index) float64 1kB 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 dayofyear (index) int64 1kB 92 99 106 113 120 127 ... 214 221 228 235 242 t (index) int64 1kB 0 1 2 3 4 5 6 7 ... 172 173 174 175 176 177 178 y (index) float64 1kB 3.985e+03 3.763e+03 ... 4.479e+03 4.676e+03xarray.Dataset
El método fit() construye automáticamente el modelo utilizando los priors de model_config, y asigna el modelo creado a nuestra instancia. Puedes acceder a él como un atributo normal.
type(mmm.model)
pymc.model.core.Model
mmm.graphviz()

el rastro posterior se puede acceder a través del atributo fit_result
mmm.fit_result
<xarray.Dataset> Size: 63MB
Dimensions: (chain: 4, draw: 1000, control: 3,
fourier_mode: 4, channel: 2, date: 179)
Coordinates:
* chain (chain) int64 32B 0 1 2 3
* draw (draw) int64 8kB 0 1 2 3 ... 997 998 999
* control (control) <U7 84B 'event_1' 'event_2' 't'
* fourier_mode (fourier_mode) <U5 80B 'sin_1' ... 'cos_2'
* channel (channel) <U2 16B 'x1' 'x2'
* date (date) datetime64[ns] 1kB 2018-04-02 ......
Data variables:
intercept (chain, draw) float64 32kB 0.3241 ... 0....
gamma_control (chain, draw, control) float64 96kB 0.24...
gamma_fourier (chain, draw, fourier_mode) float64 128kB ...
adstock_alpha (chain, draw, channel) float64 64kB 0.44...
saturation_lam (chain, draw, channel) float64 64kB 3.86...
saturation_beta (chain, draw, channel) float64 64kB 0.41...
y_sigma (chain, draw) float64 32kB 0.0307 ... 0....
channel_contributions (chain, draw, date, channel) float64 11MB ...
control_contributions (chain, draw, date, control) float64 17MB ...
fourier_contributions (chain, draw, date, fourier_mode) float64 23MB ...
yearly_seasonality_contribution (chain, draw, date) float64 6MB 0.003468...
mu (chain, draw, date) float64 6MB 0.4647 ....
Attributes:
created_at: 2024-11-14T13:56:50.170234
arviz_version: 0.17.1- chain: 4
- draw: 1000
- control: 3
- fourier_mode: 4
- channel: 2
- date: 179
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 5 ... 995 996 997 998 999
array([ 0, 1, 2, ..., 997, 998, 999])
- control(control)<U7'event_1' 'event_2' 't'
array(['event_1', 'event_2', 't'], dtype='<U7')
- fourier_mode(fourier_mode)<U5'sin_1' 'sin_2' 'cos_1' 'cos_2'
array(['sin_1', 'sin_2', 'cos_1', 'cos_2'], dtype='<U5')
- channel(channel)<U2'x1' 'x2'
array(['x1', 'x2'], dtype='<U2')
- date(date)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', '2019-01-07T00:00:00.000000000', '2019-01-14T00:00:00.000000000', '2019-01-21T00:00:00.000000000', '2019-01-28T00:00:00.000000000', '2019-02-04T00:00:00.000000000', '2019-02-11T00:00:00.000000000', '2019-02-18T00:00:00.000000000', '2019-02-25T00:00:00.000000000', '2019-03-04T00:00:00.000000000', '2019-03-11T00:00:00.000000000', '2019-03-18T00:00:00.000000000', '2019-03-25T00:00:00.000000000', '2019-04-01T00:00:00.000000000', '2019-04-08T00:00:00.000000000', '2019-04-15T00:00:00.000000000', '2019-04-22T00:00:00.000000000', '2019-04-29T00:00:00.000000000', '2019-05-06T00:00:00.000000000', '2019-05-13T00:00:00.000000000', '2019-05-20T00:00:00.000000000', '2019-05-27T00:00:00.000000000', '2019-06-03T00:00:00.000000000', '2019-06-10T00:00:00.000000000', '2019-06-17T00:00:00.000000000', '2019-06-24T00:00:00.000000000', '2019-07-01T00:00:00.000000000', '2019-07-08T00:00:00.000000000', '2019-07-15T00:00:00.000000000', '2019-07-22T00:00:00.000000000', '2019-07-29T00:00:00.000000000', '2019-08-05T00:00:00.000000000', '2019-08-12T00:00:00.000000000', '2019-08-19T00:00:00.000000000', '2019-08-26T00:00:00.000000000', '2019-09-02T00:00:00.000000000', '2019-09-09T00:00:00.000000000', '2019-09-16T00:00:00.000000000', '2019-09-23T00:00:00.000000000', '2019-09-30T00:00:00.000000000', '2019-10-07T00:00:00.000000000', '2019-10-14T00:00:00.000000000', '2019-10-21T00:00:00.000000000', '2019-10-28T00:00:00.000000000', '2019-11-04T00:00:00.000000000', '2019-11-11T00:00:00.000000000', '2019-11-18T00:00:00.000000000', '2019-11-25T00:00:00.000000000', '2019-12-02T00:00:00.000000000', '2019-12-09T00:00:00.000000000', '2019-12-16T00:00:00.000000000', '2019-12-23T00:00:00.000000000', '2019-12-30T00:00:00.000000000', '2020-01-06T00:00:00.000000000', '2020-01-13T00:00:00.000000000', '2020-01-20T00:00:00.000000000', '2020-01-27T00:00:00.000000000', '2020-02-03T00:00:00.000000000', '2020-02-10T00:00:00.000000000', '2020-02-17T00:00:00.000000000', '2020-02-24T00:00:00.000000000', '2020-03-02T00:00:00.000000000', '2020-03-09T00:00:00.000000000', '2020-03-16T00:00:00.000000000', '2020-03-23T00:00:00.000000000', '2020-03-30T00:00:00.000000000', '2020-04-06T00:00:00.000000000', '2020-04-13T00:00:00.000000000', '2020-04-20T00:00:00.000000000', '2020-04-27T00:00:00.000000000', '2020-05-04T00:00:00.000000000', '2020-05-11T00:00:00.000000000', '2020-05-18T00:00:00.000000000', '2020-05-25T00:00:00.000000000', '2020-06-01T00:00:00.000000000', '2020-06-08T00:00:00.000000000', '2020-06-15T00:00:00.000000000', '2020-06-22T00:00:00.000000000', '2020-06-29T00:00:00.000000000', '2020-07-06T00:00:00.000000000', '2020-07-13T00:00:00.000000000', '2020-07-20T00:00:00.000000000', '2020-07-27T00:00:00.000000000', '2020-08-03T00:00:00.000000000', '2020-08-10T00:00:00.000000000', '2020-08-17T00:00:00.000000000', '2020-08-24T00:00:00.000000000', '2020-08-31T00:00:00.000000000', '2020-09-07T00:00:00.000000000', '2020-09-14T00:00:00.000000000', '2020-09-21T00:00:00.000000000', '2020-09-28T00:00:00.000000000', '2020-10-05T00:00:00.000000000', '2020-10-12T00:00:00.000000000', '2020-10-19T00:00:00.000000000', '2020-10-26T00:00:00.000000000', '2020-11-02T00:00:00.000000000', '2020-11-09T00:00:00.000000000', '2020-11-16T00:00:00.000000000', '2020-11-23T00:00:00.000000000', '2020-11-30T00:00:00.000000000', '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]')
- intercept(chain, draw)float640.3241 0.3462 ... 0.3452 0.3423
array([[0.32406678, 0.34619647, 0.34946238, ..., 0.36017873, 0.36364648, 0.34211201], [0.34297333, 0.36458607, 0.36305035, ..., 0.33153195, 0.32648402, 0.34689344], [0.35538442, 0.34876222, 0.3400557 , ..., 0.34048732, 0.36433433, 0.34712521], [0.34653625, 0.34949441, 0.34821141, ..., 0.34792694, 0.34519334, 0.34231005]]) - gamma_control(chain, draw, control)float640.2444 0.2986 ... 0.2807 0.0006254
array([[[0.24442176, 0.29861242, 0.00072677], [0.29257094, 0.31640118, 0.00061519], [0.29728759, 0.33418332, 0.00067896], ..., [0.23872646, 0.33049203, 0.00061568], [0.24268897, 0.33045391, 0.00058077], [0.24983399, 0.33552453, 0.00055499]], [[0.22704413, 0.25684749, 0.00062875], [0.27251037, 0.29577431, 0.0005847 ], [0.26730817, 0.28312486, 0.00057571], ..., [0.24769467, 0.3111828 , 0.00059493], [0.25269611, 0.3182666 , 0.00063728], [0.25365855, 0.30168336, 0.00065024]], [[0.21227108, 0.2928598 , 0.00054851], [0.25580358, 0.30173479, 0.00062438], [0.22743417, 0.28359657, 0.00062732], ..., [0.21719658, 0.32878429, 0.00066653], [0.24974847, 0.32583108, 0.00063815], [0.21038605, 0.35550874, 0.00064522]], [[0.25045293, 0.32619178, 0.00060629], [0.2707071 , 0.31504205, 0.00067208], [0.26584232, 0.269338 , 0.00059683], ..., [0.2166309 , 0.27594761, 0.00064141], [0.20106656, 0.26520393, 0.00070353], [0.21866508, 0.28069877, 0.00062543]]]) - gamma_fourier(chain, draw, fourier_mode)float640.0007724 -0.06061 ... -0.003132
array([[[ 7.72378808e-04, -6.06081570e-02, 6.32651251e-02, -2.01114377e-03], [ 9.96871005e-04, -5.86696713e-02, 6.20015874e-02, -1.34957454e-03], [ 2.78543874e-03, -5.91531137e-02, 6.28186476e-02, 1.23215028e-03], ..., [ 1.09308961e-02, -5.52255837e-02, 5.53657488e-02, 4.06550058e-03], [ 1.01287922e-02, -5.45675206e-02, 5.54975548e-02, 4.80993995e-03], [-1.82057929e-03, -5.67813999e-02, 6.74055087e-02, -4.77966242e-04]], [[-7.51961183e-04, -5.86088163e-02, 6.99076644e-02, 5.51497132e-03], [ 6.89727412e-03, -5.43440801e-02, 5.83835597e-02, -4.96441715e-04], [ 4.72784938e-03, -5.10017479e-02, 5.88479576e-02, -2.03822960e-04], ... [ 2.45021147e-03, -6.18282104e-02, 6.03125031e-02, -2.61392124e-04], [ 5.13255670e-03, -5.59025608e-02, 6.18636645e-02, 1.62105766e-03], [ 2.93775206e-03, -5.63428785e-02, 6.09074908e-02, 6.94092174e-03]], [[ 4.04566016e-04, -5.24779710e-02, 5.68171569e-02, -1.14227587e-03], [ 3.00933140e-03, -5.86054466e-02, 6.97586385e-02, -9.87345554e-05], [ 3.80797985e-03, -5.87374919e-02, 6.48225474e-02, -3.92531564e-03], ..., [-3.01772993e-03, -5.50307089e-02, 6.47225183e-02, 2.47184808e-03], [ 4.25596483e-04, -5.84699367e-02, 6.60252484e-02, -5.38060536e-03], [-3.71017805e-03, -5.73044070e-02, 5.67166184e-02, -3.13215242e-03]]]) - adstock_alpha(chain, draw, channel)float640.4468 0.1246 ... 0.4151 0.2179
array([[[0.44678044, 0.12461885], [0.43940092, 0.11574963], [0.42688628, 0.07674649], ..., [0.412239 , 0.21451786], [0.40217029, 0.2023283 ], [0.37723098, 0.14994939]], [[0.3738777 , 0.18442894], [0.43561957, 0.22804777], [0.42895391, 0.25879418], ..., [0.39633751, 0.21297114], [0.40366376, 0.23518666], [0.4398461 , 0.20269349]], [[0.4015843 , 0.1868227 ], [0.40945581, 0.21108652], [0.4010663 , 0.20394772], ..., [0.44732677, 0.14938899], [0.39170829, 0.19147519], [0.41338947, 0.19456145]], [[0.41149561, 0.15391603], [0.45110995, 0.22269684], [0.46353293, 0.18878952], ..., [0.4713076 , 0.18355891], [0.4405482 , 0.18488228], [0.41509309, 0.21794455]]]) - saturation_lam(chain, draw, channel)float643.866 4.382 4.017 ... 3.655 3.112
array([[[3.8664679 , 4.3822459 ], [4.01697237, 5.003845 ], [3.46829185, 6.71698576], ..., [3.86860499, 1.9513025 ], [3.79728533, 2.23915015], [4.54663146, 3.26044198]], [[4.63015095, 2.41940406], [3.83650437, 3.08048179], [3.70979051, 2.65448979], ..., [4.65145926, 2.5143236 ], [4.79699316, 2.25997681], [3.63499734, 2.46720476]], [[4.01248188, 3.17819848], [4.02747406, 2.89137585], [4.4275353 , 3.29558325], ..., [3.57758012, 3.71414201], [3.59328546, 3.51946369], [4.17169924, 3.24657569]], [[3.38978669, 2.59500796], [3.17237872, 3.41789036], [3.18373805, 3.22026436], ..., [3.63722205, 2.49821975], [3.51596054, 2.71652159], [3.65516329, 3.11221716]]]) - saturation_beta(chain, draw, channel)float640.4163 0.208 ... 0.3982 0.2519
array([[[0.41626701, 0.20802294], [0.37481779, 0.21153649], [0.40060792, 0.20025627], ..., [0.34451547, 0.33184141], [0.34894712, 0.30627982], [0.36452861, 0.231014 ]], [[0.35516922, 0.26077286], [0.34654678, 0.242997 ], [0.36425293, 0.2645556 ], ..., [0.35922902, 0.27072243], [0.35925855, 0.30673295], [0.39677358, 0.2771929 ]], [[0.36482536, 0.23342183], [0.35803484, 0.26115968], [0.35628967, 0.23817916], ..., [0.40585395, 0.2264985 ], [0.36555962, 0.22381165], [0.35701154, 0.24064578]], [[0.41339001, 0.26849517], [0.41982109, 0.23371085], [0.42931902, 0.24232727], ..., [0.39779643, 0.26927112], [0.39489904, 0.2601883 ], [0.39819555, 0.2518974 ]]]) - y_sigma(chain, draw)float640.0307 0.02867 ... 0.02949 0.02912
array([[0.03069617, 0.02866503, 0.03113925, ..., 0.03104758, 0.03081779, 0.02892369], [0.03029061, 0.02866137, 0.02772262, ..., 0.02691624, 0.02858276, 0.0283407 ], [0.03098302, 0.02930196, 0.02883407, ..., 0.02824263, 0.03214303, 0.03270503], [0.03228296, 0.03013216, 0.030262 , ..., 0.02906735, 0.02948853, 0.02911568]]) - channel_contributions(chain, draw, date, channel)float640.1372 0.0 ... 0.2258 0.002755
array([[[[1.37212326e-01, 0.00000000e+00], [1.11199429e-01, 0.00000000e+00], [1.71007656e-01, 0.00000000e+00], ..., [1.16674015e-01, 4.25633383e-02], [1.68565397e-01, 5.37893130e-03], [2.41577564e-01, 6.70442138e-04]], [[1.29527877e-01, 0.00000000e+00], [1.04198269e-01, 0.00000000e+00], [1.60054784e-01, 0.00000000e+00], ..., [1.09283274e-01, 4.62727148e-02], [1.57729818e-01, 5.44281615e-03], [2.24870877e-01, 6.30127381e-04]], [[1.23279518e-01, 0.00000000e+00], [9.73487830e-02, 0.00000000e+00], [1.51440025e-01, 0.00000000e+00], ..., ... ..., [1.04048343e-01, 4.33930862e-02], [1.50041016e-01, 8.03284839e-03], [2.16606305e-01, 1.47460029e-03]], [[1.20372275e-01, 0.00000000e+00], [9.66280534e-02, 0.00000000e+00], [1.49697234e-01, 0.00000000e+00], ..., [1.01409036e-01, 4.57700468e-02], [1.47464482e-01, 8.54793624e-03], [2.13772945e-01, 1.58055202e-03]], [[1.31108520e-01, 0.00000000e+00], [1.02230037e-01, 0.00000000e+00], [1.59026691e-01, 0.00000000e+00], ..., [1.07379983e-01, 5.70321112e-02], [1.56524203e-01, 1.26383894e-02], [2.25810950e-01, 2.75524666e-03]]]]) - control_contributions(chain, draw, date, control)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.1113
array([[[[0. , 0. , 0. ], [0. , 0. , 0.00072677], [0. , 0. , 0.00145355], ..., [0. , 0. , 0.12791198], [0. , 0. , 0.12863876], [0. , 0. , 0.12936553]], [[0. , 0. , 0. ], [0. , 0. , 0.00061519], [0. , 0. , 0.00123037], ..., [0. , 0. , 0.10827294], [0. , 0. , 0.10888813], [0. , 0. , 0.10950331]], [[0. , 0. , 0. ], [0. , 0. , 0.00067896], [0. , 0. , 0.00135793], ..., ... ..., [0. , 0. , 0.11288826], [0. , 0. , 0.11352967], [0. , 0. , 0.11417108]], [[0. , 0. , 0. ], [0. , 0. , 0.00070353], [0. , 0. , 0.00140706], ..., [0. , 0. , 0.12382172], [0. , 0. , 0.12452525], [0. , 0. , 0.12522878]], [[0. , 0. , 0. ], [0. , 0. , 0.00062543], [0. , 0. , 0.00125085], ..., [0. , 0. , 0.11007508], [0. , 0. , 0.1107005 ], [0. , 0. , 0.11132593]]]]) - fourier_contributions(chain, draw, date, fourier_mode)float640.0007723 0.001433 ... 0.001424
array([[[[ 7.72324792e-04, 1.43346072e-03, -7.48203040e-04, 2.01058119e-03], [ 7.65634814e-04, 1.58438498e-02, -8.34204809e-03, 1.94120954e-03], [ 7.47856359e-04, 2.93397136e-02, -1.58150776e-02, 1.75978906e-03], ..., [-5.43505476e-04, -6.06053195e-02, -4.49511149e-02, -1.94605543e-05], [-6.05493903e-04, -5.89960896e-02, -3.92777950e-02, 4.60762299e-04], [-6.58712951e-04, -5.39815478e-02, -3.30356440e-02, 9.14388000e-04]], [[ 9.96801288e-04, 1.38761305e-03, -7.33259852e-04, 1.34919702e-03], [ 9.88166867e-04, 1.53371015e-02, -8.17543984e-03, 1.30264530e-03], [ 9.65221097e-04, 2.84013149e-02, -1.54992172e-02, 1.18090340e-03], ... [-2.99482607e-04, -5.84671993e-02, -4.69122368e-02, -5.20646830e-05], [-3.33639495e-04, -5.69147421e-02, -4.09914019e-02, 1.23272147e-03], [-3.62964277e-04, -5.20771104e-02, -3.44769192e-02, 2.44634971e-03]], [[-3.70991858e-03, 1.35532279e-03, -6.70757329e-04, 3.13127626e-03], [-3.67778279e-03, 1.49802017e-02, -7.47857145e-03, 3.02323696e-03], [-3.59238268e-03, 2.77404061e-02, -1.41780755e-02, 2.74069296e-03], ..., [ 2.61076828e-03, -5.73017242e-02, -4.02982722e-02, -3.03078393e-05], [ 2.90853422e-03, -5.57802134e-02, -3.52121916e-02, 7.17590544e-04], [ 3.16417580e-03, -5.10390142e-02, -2.96161592e-02, 1.42406656e-03]]]]) - yearly_seasonality_contribution(chain, draw, date)float640.003468 0.01021 ... -0.07607
array([[[ 3.46816366e-03, 1.02086460e-02, 1.60322815e-02, ..., -1.06119400e-01, -9.84186161e-02, -8.67615168e-02], [ 3.00035151e-03, 9.45247386e-03, 1.50482222e-02, ..., -1.03434806e-01, -9.60747861e-02, -8.48674293e-02], [ 2.20956262e-03, 8.75211767e-03, 1.45507253e-02, ..., -1.05732356e-01, -9.90462408e-02, -8.84238300e-02], ..., [ 7.51714298e-03, 1.40476434e-02, 1.99201458e-02, ..., -1.02213936e-01, -9.76307195e-02, -8.92689368e-02], [ 5.95374117e-03, 1.23445833e-02, 1.81405997e-02, ..., -1.01077928e-01, -9.66137487e-02, -8.84060530e-02], [-7.96835577e-04, 4.61214973e-03, 9.29258202e-03, ..., -1.03395205e-01, -9.55827280e-02, -8.40008815e-02]], [[-5.70592429e-03, 3.46766874e-05, 5.34247787e-03, ..., -1.07694339e-01, -1.01125723e-01, -9.05711768e-02], [ 7.98793051e-03, 1.38241871e-02, 1.88252536e-02, ..., -1.00682462e-01, -9.44389982e-02, -8.45454900e-02], [ 5.44157795e-03, 1.04562923e-02, 1.47345841e-02, ..., -9.61408435e-02, -8.98402396e-02, -8.00939682e-02], ... [ 3.46039172e-03, 1.08911899e-02, 1.74544914e-02, ..., -1.06405222e-01, -9.94892856e-02, -8.85328421e-02], [ 4.10213217e-03, 9.97953922e-03, 1.51481950e-02, ..., -1.03451271e-01, -9.72183366e-02, -8.72085353e-02], [-3.38917268e-03, 2.91020899e-03, 8.82026944e-03, ..., -1.01616277e-01, -9.65515313e-02, -8.76483412e-02]], [[ 2.11571910e-03, 7.73026178e-03, 1.25920101e-02, ..., -9.31409579e-02, -8.64122146e-02, -7.62346169e-02], [ 3.66892356e-03, 9.20039566e-03, 1.39320741e-02, ..., -1.10286140e-01, -1.02692400e-01, -9.11457943e-02], [ 8.35452639e-03, 1.43709731e-02, 1.93515478e-02, ..., -1.07510008e-01, -9.95057891e-02, -8.76272059e-02], ..., [-4.95256745e-03, 4.74331851e-04, 5.37550347e-03, ..., -9.88673272e-02, -9.19502119e-02, -8.13607954e-02], [ 6.40671047e-03, 1.21942781e-02, 1.69197860e-02, ..., -1.05730983e-01, -9.70070621e-02, -8.44706442e-02], [ 1.05923143e-04, 6.84708440e-03, 1.27106409e-02, ..., -9.50195359e-02, -8.73662803e-02, -7.60669311e-02]]]) - mu(chain, draw, date)float640.4647 0.4462 ... 0.5348 0.6061
array([[[0.46474727, 0.44620163, 0.51256026, ..., 0.50509671, 0.52823125, 0.6089188 ], [0.4787247 , 0.4604624 , 0.52252985, ..., 0.50659059, 0.52218244, 0.59633336], [0.47495146, 0.45624224, 0.51681106, ..., 0.50621588, 0.52285358, 0.59858872], ..., [0.487753 , 0.46830311, 0.52626435, ..., 0.5115629 , 0.52435921, 0.58698488], [0.49100426, 0.46989264, 0.52829058, ..., 0.5106196 , 0.52258915, 0.58585843], [0.49592587, 0.46355153, 0.53227731, ..., 0.50038475, 0.52804129, 0.60461137]], [[0.49103563, 0.45893585, 0.52770221, ..., 0.5086166 , 0.53617477, 0.60942857], [0.48806945, 0.47138003, 0.52707625, ..., 0.51993382, 0.52705826, 0.58844434], [0.4874414 , 0.46840611, 0.52498356, ..., 0.52482575, 0.53406601, 0.59649896], ... [0.46828274, 0.45268407, 0.51479321, ..., 0.50279644, 0.51916815, 0.59336936], [0.49124997, 0.46798815, 0.52670338, ..., 0.52324639, 0.53378362, 0.60012157], [0.4767618 , 0.4546553 , 0.51748189, ..., 0.52053944, 0.53291674, 0.59989125]], [[0.4762611 , 0.45373693, 0.51500661, ..., 0.50313277, 0.52567964, 0.60063911], [0.46725959, 0.45190743, 0.50857547, ..., 0.51346739, 0.52082854, 0.58854668], [0.47116508, 0.45748746, 0.5149135 , ..., 0.49603376, 0.50829492, 0.57970088], ..., [0.46179461, 0.44792396, 0.50655411, ..., 0.5093893 , 0.52758026, 0.59881813], [0.47197232, 0.4547192 , 0.51321743, ..., 0.51046316, 0.52872395, 0.60130498], [0.47352449, 0.4520126 , 0.51529823, ..., 0.52177768, 0.53480686, 0.60613524]]])
- chainPandasIndex
PandasIndex(Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 990, 991, 992, 993, 994, 995, 996, 997, 998, 999], dtype='int64', name='draw', length=1000)) - controlPandasIndex
PandasIndex(Index(['event_1', 'event_2', 't'], dtype='object', name='control'))
- fourier_modePandasIndex
PandasIndex(Index(['sin_1', 'sin_2', 'cos_1', 'cos_2'], dtype='object', name='fourier_mode'))
- channelPandasIndex
PandasIndex(Index(['x1', 'x2'], dtype='object', name='channel'))
- datePandasIndex
PandasIndex(DatetimeIndex(['2018-04-02', '2018-04-09', '2018-04-16', '2018-04-23', '2018-04-30', '2018-05-07', '2018-05-14', '2018-05-21', '2018-05-28', '2018-06-04', ... '2021-06-28', '2021-07-05', '2021-07-12', '2021-07-19', '2021-07-26', '2021-08-02', '2021-08-09', '2021-08-16', '2021-08-23', '2021-08-30'], dtype='datetime64[ns]', name='date', length=179, freq=None))
- created_at :
- 2024-11-14T13:56:50.170234
- arviz_version :
- 0.17.1
Si deseas inspeccionar todos los datos de inferencia, utiliza el atributo idata. Dentro de idata, puedes encontrar todo el conjunto de datos pasado al modelo bajo fit_data.
mmm.idata
-
- chain: 4
- draw: 1000
- control: 3
- fourier_mode: 4
- channel: 2
- date: 179
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 5 ... 995 996 997 998 999
array([ 0, 1, 2, ..., 997, 998, 999])
- control(control)<U7'event_1' 'event_2' 't'
array(['event_1', 'event_2', 't'], dtype='<U7')
- fourier_mode(fourier_mode)<U5'sin_1' 'sin_2' 'cos_1' 'cos_2'
array(['sin_1', 'sin_2', 'cos_1', 'cos_2'], dtype='<U5')
- channel(channel)<U2'x1' 'x2'
array(['x1', 'x2'], dtype='<U2')
- date(date)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', '2019-01-07T00:00:00.000000000', '2019-01-14T00:00:00.000000000', '2019-01-21T00:00:00.000000000', '2019-01-28T00:00:00.000000000', '2019-02-04T00:00:00.000000000', '2019-02-11T00:00:00.000000000', '2019-02-18T00:00:00.000000000', '2019-02-25T00:00:00.000000000', '2019-03-04T00:00:00.000000000', '2019-03-11T00:00:00.000000000', '2019-03-18T00:00:00.000000000', '2019-03-25T00:00:00.000000000', '2019-04-01T00:00:00.000000000', '2019-04-08T00:00:00.000000000', '2019-04-15T00:00:00.000000000', '2019-04-22T00:00:00.000000000', '2019-04-29T00:00:00.000000000', '2019-05-06T00:00:00.000000000', '2019-05-13T00:00:00.000000000', '2019-05-20T00:00:00.000000000', '2019-05-27T00:00:00.000000000', '2019-06-03T00:00:00.000000000', '2019-06-10T00:00:00.000000000', '2019-06-17T00:00:00.000000000', '2019-06-24T00:00:00.000000000', '2019-07-01T00:00:00.000000000', '2019-07-08T00:00:00.000000000', '2019-07-15T00:00:00.000000000', '2019-07-22T00:00:00.000000000', '2019-07-29T00:00:00.000000000', '2019-08-05T00:00:00.000000000', '2019-08-12T00:00:00.000000000', '2019-08-19T00:00:00.000000000', '2019-08-26T00:00:00.000000000', '2019-09-02T00:00:00.000000000', '2019-09-09T00:00:00.000000000', '2019-09-16T00:00:00.000000000', '2019-09-23T00:00:00.000000000', '2019-09-30T00:00:00.000000000', '2019-10-07T00:00:00.000000000', '2019-10-14T00:00:00.000000000', '2019-10-21T00:00:00.000000000', '2019-10-28T00:00:00.000000000', '2019-11-04T00:00:00.000000000', '2019-11-11T00:00:00.000000000', '2019-11-18T00:00:00.000000000', '2019-11-25T00:00:00.000000000', '2019-12-02T00:00:00.000000000', '2019-12-09T00:00:00.000000000', '2019-12-16T00:00:00.000000000', '2019-12-23T00:00:00.000000000', '2019-12-30T00:00:00.000000000', '2020-01-06T00:00:00.000000000', '2020-01-13T00:00:00.000000000', '2020-01-20T00:00:00.000000000', '2020-01-27T00:00:00.000000000', '2020-02-03T00:00:00.000000000', '2020-02-10T00:00:00.000000000', '2020-02-17T00:00:00.000000000', '2020-02-24T00:00:00.000000000', '2020-03-02T00:00:00.000000000', '2020-03-09T00:00:00.000000000', '2020-03-16T00:00:00.000000000', '2020-03-23T00:00:00.000000000', '2020-03-30T00:00:00.000000000', '2020-04-06T00:00:00.000000000', '2020-04-13T00:00:00.000000000', '2020-04-20T00:00:00.000000000', '2020-04-27T00:00:00.000000000', '2020-05-04T00:00:00.000000000', '2020-05-11T00:00:00.000000000', '2020-05-18T00:00:00.000000000', '2020-05-25T00:00:00.000000000', '2020-06-01T00:00:00.000000000', '2020-06-08T00:00:00.000000000', '2020-06-15T00:00:00.000000000', '2020-06-22T00:00:00.000000000', '2020-06-29T00:00:00.000000000', '2020-07-06T00:00:00.000000000', '2020-07-13T00:00:00.000000000', '2020-07-20T00:00:00.000000000', '2020-07-27T00:00:00.000000000', '2020-08-03T00:00:00.000000000', '2020-08-10T00:00:00.000000000', '2020-08-17T00:00:00.000000000', '2020-08-24T00:00:00.000000000', '2020-08-31T00:00:00.000000000', '2020-09-07T00:00:00.000000000', '2020-09-14T00:00:00.000000000', '2020-09-21T00:00:00.000000000', '2020-09-28T00:00:00.000000000', '2020-10-05T00:00:00.000000000', '2020-10-12T00:00:00.000000000', '2020-10-19T00:00:00.000000000', '2020-10-26T00:00:00.000000000', '2020-11-02T00:00:00.000000000', '2020-11-09T00:00:00.000000000', '2020-11-16T00:00:00.000000000', '2020-11-23T00:00:00.000000000', '2020-11-30T00:00:00.000000000', '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]')
- intercept(chain, draw)float640.3241 0.3462 ... 0.3452 0.3423
array([[0.32406678, 0.34619647, 0.34946238, ..., 0.36017873, 0.36364648, 0.34211201], [0.34297333, 0.36458607, 0.36305035, ..., 0.33153195, 0.32648402, 0.34689344], [0.35538442, 0.34876222, 0.3400557 , ..., 0.34048732, 0.36433433, 0.34712521], [0.34653625, 0.34949441, 0.34821141, ..., 0.34792694, 0.34519334, 0.34231005]]) - gamma_control(chain, draw, control)float640.2444 0.2986 ... 0.2807 0.0006254
array([[[0.24442176, 0.29861242, 0.00072677], [0.29257094, 0.31640118, 0.00061519], [0.29728759, 0.33418332, 0.00067896], ..., [0.23872646, 0.33049203, 0.00061568], [0.24268897, 0.33045391, 0.00058077], [0.24983399, 0.33552453, 0.00055499]], [[0.22704413, 0.25684749, 0.00062875], [0.27251037, 0.29577431, 0.0005847 ], [0.26730817, 0.28312486, 0.00057571], ..., [0.24769467, 0.3111828 , 0.00059493], [0.25269611, 0.3182666 , 0.00063728], [0.25365855, 0.30168336, 0.00065024]], [[0.21227108, 0.2928598 , 0.00054851], [0.25580358, 0.30173479, 0.00062438], [0.22743417, 0.28359657, 0.00062732], ..., [0.21719658, 0.32878429, 0.00066653], [0.24974847, 0.32583108, 0.00063815], [0.21038605, 0.35550874, 0.00064522]], [[0.25045293, 0.32619178, 0.00060629], [0.2707071 , 0.31504205, 0.00067208], [0.26584232, 0.269338 , 0.00059683], ..., [0.2166309 , 0.27594761, 0.00064141], [0.20106656, 0.26520393, 0.00070353], [0.21866508, 0.28069877, 0.00062543]]]) - gamma_fourier(chain, draw, fourier_mode)float640.0007724 -0.06061 ... -0.003132
array([[[ 7.72378808e-04, -6.06081570e-02, 6.32651251e-02, -2.01114377e-03], [ 9.96871005e-04, -5.86696713e-02, 6.20015874e-02, -1.34957454e-03], [ 2.78543874e-03, -5.91531137e-02, 6.28186476e-02, 1.23215028e-03], ..., [ 1.09308961e-02, -5.52255837e-02, 5.53657488e-02, 4.06550058e-03], [ 1.01287922e-02, -5.45675206e-02, 5.54975548e-02, 4.80993995e-03], [-1.82057929e-03, -5.67813999e-02, 6.74055087e-02, -4.77966242e-04]], [[-7.51961183e-04, -5.86088163e-02, 6.99076644e-02, 5.51497132e-03], [ 6.89727412e-03, -5.43440801e-02, 5.83835597e-02, -4.96441715e-04], [ 4.72784938e-03, -5.10017479e-02, 5.88479576e-02, -2.03822960e-04], ... [ 2.45021147e-03, -6.18282104e-02, 6.03125031e-02, -2.61392124e-04], [ 5.13255670e-03, -5.59025608e-02, 6.18636645e-02, 1.62105766e-03], [ 2.93775206e-03, -5.63428785e-02, 6.09074908e-02, 6.94092174e-03]], [[ 4.04566016e-04, -5.24779710e-02, 5.68171569e-02, -1.14227587e-03], [ 3.00933140e-03, -5.86054466e-02, 6.97586385e-02, -9.87345554e-05], [ 3.80797985e-03, -5.87374919e-02, 6.48225474e-02, -3.92531564e-03], ..., [-3.01772993e-03, -5.50307089e-02, 6.47225183e-02, 2.47184808e-03], [ 4.25596483e-04, -5.84699367e-02, 6.60252484e-02, -5.38060536e-03], [-3.71017805e-03, -5.73044070e-02, 5.67166184e-02, -3.13215242e-03]]]) - adstock_alpha(chain, draw, channel)float640.4468 0.1246 ... 0.4151 0.2179
array([[[0.44678044, 0.12461885], [0.43940092, 0.11574963], [0.42688628, 0.07674649], ..., [0.412239 , 0.21451786], [0.40217029, 0.2023283 ], [0.37723098, 0.14994939]], [[0.3738777 , 0.18442894], [0.43561957, 0.22804777], [0.42895391, 0.25879418], ..., [0.39633751, 0.21297114], [0.40366376, 0.23518666], [0.4398461 , 0.20269349]], [[0.4015843 , 0.1868227 ], [0.40945581, 0.21108652], [0.4010663 , 0.20394772], ..., [0.44732677, 0.14938899], [0.39170829, 0.19147519], [0.41338947, 0.19456145]], [[0.41149561, 0.15391603], [0.45110995, 0.22269684], [0.46353293, 0.18878952], ..., [0.4713076 , 0.18355891], [0.4405482 , 0.18488228], [0.41509309, 0.21794455]]]) - saturation_lam(chain, draw, channel)float643.866 4.382 4.017 ... 3.655 3.112
array([[[3.8664679 , 4.3822459 ], [4.01697237, 5.003845 ], [3.46829185, 6.71698576], ..., [3.86860499, 1.9513025 ], [3.79728533, 2.23915015], [4.54663146, 3.26044198]], [[4.63015095, 2.41940406], [3.83650437, 3.08048179], [3.70979051, 2.65448979], ..., [4.65145926, 2.5143236 ], [4.79699316, 2.25997681], [3.63499734, 2.46720476]], [[4.01248188, 3.17819848], [4.02747406, 2.89137585], [4.4275353 , 3.29558325], ..., [3.57758012, 3.71414201], [3.59328546, 3.51946369], [4.17169924, 3.24657569]], [[3.38978669, 2.59500796], [3.17237872, 3.41789036], [3.18373805, 3.22026436], ..., [3.63722205, 2.49821975], [3.51596054, 2.71652159], [3.65516329, 3.11221716]]]) - saturation_beta(chain, draw, channel)float640.4163 0.208 ... 0.3982 0.2519
array([[[0.41626701, 0.20802294], [0.37481779, 0.21153649], [0.40060792, 0.20025627], ..., [0.34451547, 0.33184141], [0.34894712, 0.30627982], [0.36452861, 0.231014 ]], [[0.35516922, 0.26077286], [0.34654678, 0.242997 ], [0.36425293, 0.2645556 ], ..., [0.35922902, 0.27072243], [0.35925855, 0.30673295], [0.39677358, 0.2771929 ]], [[0.36482536, 0.23342183], [0.35803484, 0.26115968], [0.35628967, 0.23817916], ..., [0.40585395, 0.2264985 ], [0.36555962, 0.22381165], [0.35701154, 0.24064578]], [[0.41339001, 0.26849517], [0.41982109, 0.23371085], [0.42931902, 0.24232727], ..., [0.39779643, 0.26927112], [0.39489904, 0.2601883 ], [0.39819555, 0.2518974 ]]]) - y_sigma(chain, draw)float640.0307 0.02867 ... 0.02949 0.02912
array([[0.03069617, 0.02866503, 0.03113925, ..., 0.03104758, 0.03081779, 0.02892369], [0.03029061, 0.02866137, 0.02772262, ..., 0.02691624, 0.02858276, 0.0283407 ], [0.03098302, 0.02930196, 0.02883407, ..., 0.02824263, 0.03214303, 0.03270503], [0.03228296, 0.03013216, 0.030262 , ..., 0.02906735, 0.02948853, 0.02911568]]) - channel_contributions(chain, draw, date, channel)float640.1372 0.0 ... 0.2258 0.002755
array([[[[1.37212326e-01, 0.00000000e+00], [1.11199429e-01, 0.00000000e+00], [1.71007656e-01, 0.00000000e+00], ..., [1.16674015e-01, 4.25633383e-02], [1.68565397e-01, 5.37893130e-03], [2.41577564e-01, 6.70442138e-04]], [[1.29527877e-01, 0.00000000e+00], [1.04198269e-01, 0.00000000e+00], [1.60054784e-01, 0.00000000e+00], ..., [1.09283274e-01, 4.62727148e-02], [1.57729818e-01, 5.44281615e-03], [2.24870877e-01, 6.30127381e-04]], [[1.23279518e-01, 0.00000000e+00], [9.73487830e-02, 0.00000000e+00], [1.51440025e-01, 0.00000000e+00], ..., ... ..., [1.04048343e-01, 4.33930862e-02], [1.50041016e-01, 8.03284839e-03], [2.16606305e-01, 1.47460029e-03]], [[1.20372275e-01, 0.00000000e+00], [9.66280534e-02, 0.00000000e+00], [1.49697234e-01, 0.00000000e+00], ..., [1.01409036e-01, 4.57700468e-02], [1.47464482e-01, 8.54793624e-03], [2.13772945e-01, 1.58055202e-03]], [[1.31108520e-01, 0.00000000e+00], [1.02230037e-01, 0.00000000e+00], [1.59026691e-01, 0.00000000e+00], ..., [1.07379983e-01, 5.70321112e-02], [1.56524203e-01, 1.26383894e-02], [2.25810950e-01, 2.75524666e-03]]]]) - control_contributions(chain, draw, date, control)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.1113
array([[[[0. , 0. , 0. ], [0. , 0. , 0.00072677], [0. , 0. , 0.00145355], ..., [0. , 0. , 0.12791198], [0. , 0. , 0.12863876], [0. , 0. , 0.12936553]], [[0. , 0. , 0. ], [0. , 0. , 0.00061519], [0. , 0. , 0.00123037], ..., [0. , 0. , 0.10827294], [0. , 0. , 0.10888813], [0. , 0. , 0.10950331]], [[0. , 0. , 0. ], [0. , 0. , 0.00067896], [0. , 0. , 0.00135793], ..., ... ..., [0. , 0. , 0.11288826], [0. , 0. , 0.11352967], [0. , 0. , 0.11417108]], [[0. , 0. , 0. ], [0. , 0. , 0.00070353], [0. , 0. , 0.00140706], ..., [0. , 0. , 0.12382172], [0. , 0. , 0.12452525], [0. , 0. , 0.12522878]], [[0. , 0. , 0. ], [0. , 0. , 0.00062543], [0. , 0. , 0.00125085], ..., [0. , 0. , 0.11007508], [0. , 0. , 0.1107005 ], [0. , 0. , 0.11132593]]]]) - fourier_contributions(chain, draw, date, fourier_mode)float640.0007723 0.001433 ... 0.001424
array([[[[ 7.72324792e-04, 1.43346072e-03, -7.48203040e-04, 2.01058119e-03], [ 7.65634814e-04, 1.58438498e-02, -8.34204809e-03, 1.94120954e-03], [ 7.47856359e-04, 2.93397136e-02, -1.58150776e-02, 1.75978906e-03], ..., [-5.43505476e-04, -6.06053195e-02, -4.49511149e-02, -1.94605543e-05], [-6.05493903e-04, -5.89960896e-02, -3.92777950e-02, 4.60762299e-04], [-6.58712951e-04, -5.39815478e-02, -3.30356440e-02, 9.14388000e-04]], [[ 9.96801288e-04, 1.38761305e-03, -7.33259852e-04, 1.34919702e-03], [ 9.88166867e-04, 1.53371015e-02, -8.17543984e-03, 1.30264530e-03], [ 9.65221097e-04, 2.84013149e-02, -1.54992172e-02, 1.18090340e-03], ... [-2.99482607e-04, -5.84671993e-02, -4.69122368e-02, -5.20646830e-05], [-3.33639495e-04, -5.69147421e-02, -4.09914019e-02, 1.23272147e-03], [-3.62964277e-04, -5.20771104e-02, -3.44769192e-02, 2.44634971e-03]], [[-3.70991858e-03, 1.35532279e-03, -6.70757329e-04, 3.13127626e-03], [-3.67778279e-03, 1.49802017e-02, -7.47857145e-03, 3.02323696e-03], [-3.59238268e-03, 2.77404061e-02, -1.41780755e-02, 2.74069296e-03], ..., [ 2.61076828e-03, -5.73017242e-02, -4.02982722e-02, -3.03078393e-05], [ 2.90853422e-03, -5.57802134e-02, -3.52121916e-02, 7.17590544e-04], [ 3.16417580e-03, -5.10390142e-02, -2.96161592e-02, 1.42406656e-03]]]]) - yearly_seasonality_contribution(chain, draw, date)float640.003468 0.01021 ... -0.07607
array([[[ 3.46816366e-03, 1.02086460e-02, 1.60322815e-02, ..., -1.06119400e-01, -9.84186161e-02, -8.67615168e-02], [ 3.00035151e-03, 9.45247386e-03, 1.50482222e-02, ..., -1.03434806e-01, -9.60747861e-02, -8.48674293e-02], [ 2.20956262e-03, 8.75211767e-03, 1.45507253e-02, ..., -1.05732356e-01, -9.90462408e-02, -8.84238300e-02], ..., [ 7.51714298e-03, 1.40476434e-02, 1.99201458e-02, ..., -1.02213936e-01, -9.76307195e-02, -8.92689368e-02], [ 5.95374117e-03, 1.23445833e-02, 1.81405997e-02, ..., -1.01077928e-01, -9.66137487e-02, -8.84060530e-02], [-7.96835577e-04, 4.61214973e-03, 9.29258202e-03, ..., -1.03395205e-01, -9.55827280e-02, -8.40008815e-02]], [[-5.70592429e-03, 3.46766874e-05, 5.34247787e-03, ..., -1.07694339e-01, -1.01125723e-01, -9.05711768e-02], [ 7.98793051e-03, 1.38241871e-02, 1.88252536e-02, ..., -1.00682462e-01, -9.44389982e-02, -8.45454900e-02], [ 5.44157795e-03, 1.04562923e-02, 1.47345841e-02, ..., -9.61408435e-02, -8.98402396e-02, -8.00939682e-02], ... [ 3.46039172e-03, 1.08911899e-02, 1.74544914e-02, ..., -1.06405222e-01, -9.94892856e-02, -8.85328421e-02], [ 4.10213217e-03, 9.97953922e-03, 1.51481950e-02, ..., -1.03451271e-01, -9.72183366e-02, -8.72085353e-02], [-3.38917268e-03, 2.91020899e-03, 8.82026944e-03, ..., -1.01616277e-01, -9.65515313e-02, -8.76483412e-02]], [[ 2.11571910e-03, 7.73026178e-03, 1.25920101e-02, ..., -9.31409579e-02, -8.64122146e-02, -7.62346169e-02], [ 3.66892356e-03, 9.20039566e-03, 1.39320741e-02, ..., -1.10286140e-01, -1.02692400e-01, -9.11457943e-02], [ 8.35452639e-03, 1.43709731e-02, 1.93515478e-02, ..., -1.07510008e-01, -9.95057891e-02, -8.76272059e-02], ..., [-4.95256745e-03, 4.74331851e-04, 5.37550347e-03, ..., -9.88673272e-02, -9.19502119e-02, -8.13607954e-02], [ 6.40671047e-03, 1.21942781e-02, 1.69197860e-02, ..., -1.05730983e-01, -9.70070621e-02, -8.44706442e-02], [ 1.05923143e-04, 6.84708440e-03, 1.27106409e-02, ..., -9.50195359e-02, -8.73662803e-02, -7.60669311e-02]]]) - mu(chain, draw, date)float640.4647 0.4462 ... 0.5348 0.6061
array([[[0.46474727, 0.44620163, 0.51256026, ..., 0.50509671, 0.52823125, 0.6089188 ], [0.4787247 , 0.4604624 , 0.52252985, ..., 0.50659059, 0.52218244, 0.59633336], [0.47495146, 0.45624224, 0.51681106, ..., 0.50621588, 0.52285358, 0.59858872], ..., [0.487753 , 0.46830311, 0.52626435, ..., 0.5115629 , 0.52435921, 0.58698488], [0.49100426, 0.46989264, 0.52829058, ..., 0.5106196 , 0.52258915, 0.58585843], [0.49592587, 0.46355153, 0.53227731, ..., 0.50038475, 0.52804129, 0.60461137]], [[0.49103563, 0.45893585, 0.52770221, ..., 0.5086166 , 0.53617477, 0.60942857], [0.48806945, 0.47138003, 0.52707625, ..., 0.51993382, 0.52705826, 0.58844434], [0.4874414 , 0.46840611, 0.52498356, ..., 0.52482575, 0.53406601, 0.59649896], ... [0.46828274, 0.45268407, 0.51479321, ..., 0.50279644, 0.51916815, 0.59336936], [0.49124997, 0.46798815, 0.52670338, ..., 0.52324639, 0.53378362, 0.60012157], [0.4767618 , 0.4546553 , 0.51748189, ..., 0.52053944, 0.53291674, 0.59989125]], [[0.4762611 , 0.45373693, 0.51500661, ..., 0.50313277, 0.52567964, 0.60063911], [0.46725959, 0.45190743, 0.50857547, ..., 0.51346739, 0.52082854, 0.58854668], [0.47116508, 0.45748746, 0.5149135 , ..., 0.49603376, 0.50829492, 0.57970088], ..., [0.46179461, 0.44792396, 0.50655411, ..., 0.5093893 , 0.52758026, 0.59881813], [0.47197232, 0.4547192 , 0.51321743, ..., 0.51046316, 0.52872395, 0.60130498], [0.47352449, 0.4520126 , 0.51529823, ..., 0.52177768, 0.53480686, 0.60613524]]])
- chainPandasIndex
PandasIndex(Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 990, 991, 992, 993, 994, 995, 996, 997, 998, 999], dtype='int64', name='draw', length=1000)) - controlPandasIndex
PandasIndex(Index(['event_1', 'event_2', 't'], dtype='object', name='control'))
- fourier_modePandasIndex
PandasIndex(Index(['sin_1', 'sin_2', 'cos_1', 'cos_2'], dtype='object', name='fourier_mode'))
- channelPandasIndex
PandasIndex(Index(['x1', 'x2'], dtype='object', name='channel'))
- datePandasIndex
PandasIndex(DatetimeIndex(['2018-04-02', '2018-04-09', '2018-04-16', '2018-04-23', '2018-04-30', '2018-05-07', '2018-05-14', '2018-05-21', '2018-05-28', '2018-06-04', ... '2021-06-28', '2021-07-05', '2021-07-12', '2021-07-19', '2021-07-26', '2021-08-02', '2021-08-09', '2021-08-16', '2021-08-23', '2021-08-30'], dtype='datetime64[ns]', name='date', length=179, freq=None))
- created_at :
- 2024-11-14T13:56:50.170234
- arviz_version :
- 0.17.1
<xarray.Dataset> Size: 63MB Dimensions: (chain: 4, draw: 1000, control: 3, fourier_mode: 4, channel: 2, date: 179) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 ... 997 998 999 * control (control) <U7 84B 'event_1' 'event_2' 't' * fourier_mode (fourier_mode) <U5 80B 'sin_1' ... 'cos_2' * channel (channel) <U2 16B 'x1' 'x2' * date (date) datetime64[ns] 1kB 2018-04-02 ...... Data variables: intercept (chain, draw) float64 32kB 0.3241 ... 0.... gamma_control (chain, draw, control) float64 96kB 0.24... gamma_fourier (chain, draw, fourier_mode) float64 128kB ... adstock_alpha (chain, draw, channel) float64 64kB 0.44... saturation_lam (chain, draw, channel) float64 64kB 3.86... saturation_beta (chain, draw, channel) float64 64kB 0.41... y_sigma (chain, draw) float64 32kB 0.0307 ... 0.... channel_contributions (chain, draw, date, channel) float64 11MB ... control_contributions (chain, draw, date, control) float64 17MB ... fourier_contributions (chain, draw, date, fourier_mode) float64 23MB ... yearly_seasonality_contribution (chain, draw, date) float64 6MB 0.003468... mu (chain, draw, date) float64 6MB 0.4647 .... Attributes: created_at: 2024-11-14T13:56:50.170234 arviz_version: 0.17.1xarray.Dataset -
- chain: 4
- draw: 1000
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 5 ... 995 996 997 998 999
array([ 0, 1, 2, ..., 997, 998, 999])
- acceptance_rate(chain, draw)float640.9682 0.9951 ... 0.9999 0.9654
array([[0.96817757, 0.99508228, 0.99666656, ..., 0.87885314, 0.97430639, 0.99512293], [0.88237998, 0.98283383, 0.99986125, ..., 0.99166592, 0.99996833, 0.99909432], [0.86197359, 0.995431 , 0.99321992, ..., 0.95921727, 0.90199914, 0.78631235], [0.91222462, 0.99675826, 0.71182102, ..., 0.96484441, 0.99989372, 0.96540128]]) - step_size(chain, draw)float640.00572 0.00572 ... 0.005936
array([[0.00572014, 0.00572014, 0.00572014, ..., 0.00572014, 0.00572014, 0.00572014], [0.00515522, 0.00515522, 0.00515522, ..., 0.00515522, 0.00515522, 0.00515522], [0.00693266, 0.00693266, 0.00693266, ..., 0.00693266, 0.00693266, 0.00693266], [0.00593638, 0.00593638, 0.00593638, ..., 0.00593638, 0.00593638, 0.00593638]]) - diverging(chain, draw)boolFalse False False ... False False
array([[False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False]]) - energy(chain, draw)float64-337.8 -349.0 ... -340.3 -345.5
array([[-337.84405072, -349.03892588, -347.52658904, ..., -334.57220422, -345.02966482, -347.66356081], [-337.56831667, -343.17815709, -341.18420695, ..., -350.03646254, -349.74645907, -348.88517697], [-341.76236676, -350.07737547, -348.83769446, ..., -346.80225259, -346.4906293 , -346.77305053], [-341.98272981, -342.11445535, -338.95220358, ..., -341.58235877, -340.33901742, -345.51640744]]) - n_steps(chain, draw)int641023 511 511 511 ... 1023 511 511
array([[1023, 511, 511, ..., 511, 511, 511], [ 511, 511, 511, ..., 511, 511, 1023], [ 511, 511, 511, ..., 511, 511, 511], [ 511, 511, 511, ..., 1023, 511, 511]]) - tree_depth(chain, draw)int6410 9 9 9 9 9 9 ... 10 10 9 9 10 9 9
array([[10, 9, 9, ..., 9, 9, 9], [ 9, 9, 9, ..., 9, 9, 10], [ 9, 9, 9, ..., 9, 9, 9], [ 9, 9, 9, ..., 10, 9, 9]]) - lp(chain, draw)float64-352.0 -355.9 ... -352.2 -352.1
array([[-352.03686551, -355.85803022, -352.43212434, ..., -351.2449381 , -352.55989494, -353.89315019], [-348.92446089, -352.02017042, -349.94597102, ..., -355.4467677 , -355.47706339, -353.72276215], [-355.3382039 , -355.90952294, -354.74608244, ..., -355.53130143, -356.30140898, -354.52648169], [-347.39494536, -350.24373127, -349.82371935, ..., -350.55418291, -352.17001019, -352.06965338]])
- chainPandasIndex
PandasIndex(Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 990, 991, 992, 993, 994, 995, 996, 997, 998, 999], dtype='int64', name='draw', length=1000))
- created_at :
- 2024-11-14T13:56:50.174899
- arviz_version :
- 0.17.1
<xarray.Dataset> Size: 204kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 ... 994 995 996 997 998 999 Data variables: acceptance_rate (chain, draw) float64 32kB 0.9682 0.9951 ... 0.9999 0.9654 step_size (chain, draw) float64 32kB 0.00572 0.00572 ... 0.005936 diverging (chain, draw) bool 4kB False False False ... False False energy (chain, draw) float64 32kB -337.8 -349.0 ... -340.3 -345.5 n_steps (chain, draw) int64 32kB 1023 511 511 511 ... 1023 511 511 tree_depth (chain, draw) int64 32kB 10 9 9 9 9 9 9 ... 10 9 9 10 9 9 lp (chain, draw) float64 32kB -352.0 -355.9 ... -352.2 -352.1 Attributes: created_at: 2024-11-14T13:56:50.174899 arviz_version: 0.17.1xarray.Dataset -
- date: 179
- date(date)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', '2019-01-07T00:00:00.000000000', '2019-01-14T00:00:00.000000000', '2019-01-21T00:00:00.000000000', '2019-01-28T00:00:00.000000000', '2019-02-04T00:00:00.000000000', '2019-02-11T00:00:00.000000000', '2019-02-18T00:00:00.000000000', '2019-02-25T00:00:00.000000000', '2019-03-04T00:00:00.000000000', '2019-03-11T00:00:00.000000000', '2019-03-18T00:00:00.000000000', '2019-03-25T00:00:00.000000000', '2019-04-01T00:00:00.000000000', '2019-04-08T00:00:00.000000000', '2019-04-15T00:00:00.000000000', '2019-04-22T00:00:00.000000000', '2019-04-29T00:00:00.000000000', '2019-05-06T00:00:00.000000000', '2019-05-13T00:00:00.000000000', '2019-05-20T00:00:00.000000000', '2019-05-27T00:00:00.000000000', '2019-06-03T00:00:00.000000000', '2019-06-10T00:00:00.000000000', '2019-06-17T00:00:00.000000000', '2019-06-24T00:00:00.000000000', '2019-07-01T00:00:00.000000000', '2019-07-08T00:00:00.000000000', '2019-07-15T00:00:00.000000000', '2019-07-22T00:00:00.000000000', '2019-07-29T00:00:00.000000000', '2019-08-05T00:00:00.000000000', '2019-08-12T00:00:00.000000000', '2019-08-19T00:00:00.000000000', '2019-08-26T00:00:00.000000000', '2019-09-02T00:00:00.000000000', '2019-09-09T00:00:00.000000000', '2019-09-16T00:00:00.000000000', '2019-09-23T00:00:00.000000000', '2019-09-30T00:00:00.000000000', '2019-10-07T00:00:00.000000000', '2019-10-14T00:00:00.000000000', '2019-10-21T00:00:00.000000000', '2019-10-28T00:00:00.000000000', '2019-11-04T00:00:00.000000000', '2019-11-11T00:00:00.000000000', '2019-11-18T00:00:00.000000000', '2019-11-25T00:00:00.000000000', '2019-12-02T00:00:00.000000000', '2019-12-09T00:00:00.000000000', '2019-12-16T00:00:00.000000000', '2019-12-23T00:00:00.000000000', '2019-12-30T00:00:00.000000000', '2020-01-06T00:00:00.000000000', '2020-01-13T00:00:00.000000000', '2020-01-20T00:00:00.000000000', '2020-01-27T00:00:00.000000000', '2020-02-03T00:00:00.000000000', '2020-02-10T00:00:00.000000000', '2020-02-17T00:00:00.000000000', '2020-02-24T00:00:00.000000000', '2020-03-02T00:00:00.000000000', '2020-03-09T00:00:00.000000000', '2020-03-16T00:00:00.000000000', '2020-03-23T00:00:00.000000000', '2020-03-30T00:00:00.000000000', '2020-04-06T00:00:00.000000000', '2020-04-13T00:00:00.000000000', '2020-04-20T00:00:00.000000000', '2020-04-27T00:00:00.000000000', '2020-05-04T00:00:00.000000000', '2020-05-11T00:00:00.000000000', '2020-05-18T00:00:00.000000000', '2020-05-25T00:00:00.000000000', '2020-06-01T00:00:00.000000000', '2020-06-08T00:00:00.000000000', '2020-06-15T00:00:00.000000000', '2020-06-22T00:00:00.000000000', '2020-06-29T00:00:00.000000000', '2020-07-06T00:00:00.000000000', '2020-07-13T00:00:00.000000000', '2020-07-20T00:00:00.000000000', '2020-07-27T00:00:00.000000000', '2020-08-03T00:00:00.000000000', '2020-08-10T00:00:00.000000000', '2020-08-17T00:00:00.000000000', '2020-08-24T00:00:00.000000000', '2020-08-31T00:00:00.000000000', '2020-09-07T00:00:00.000000000', '2020-09-14T00:00:00.000000000', '2020-09-21T00:00:00.000000000', '2020-09-28T00:00:00.000000000', '2020-10-05T00:00:00.000000000', '2020-10-12T00:00:00.000000000', '2020-10-19T00:00:00.000000000', '2020-10-26T00:00:00.000000000', '2020-11-02T00:00:00.000000000', '2020-11-09T00:00:00.000000000', '2020-11-16T00:00:00.000000000', '2020-11-23T00:00:00.000000000', '2020-11-30T00:00:00.000000000', '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]')
- y(date)float640.4794 0.4527 ... 0.5388 0.5625
array([0.47936319, 0.45268134, 0.53738551, 0.46487367, 0.5343368 , 0.44239849, 0.60963642, 0.73132832, 0.59600126, 0.70565315, 0.61313561, 0.60049297, 0.56404656, 0.78633605, 0.60523784, 0.5580442 , 0.50641716, 0.586594 , 0.46992062, 0.42705583, 0.48426812, 0.38777049, 0.49079078, 0.50002789, 0.44113299, 0.46359002, 0.42484345, 0.42573496, 0.5126282 , 0.55393305, 0.7801562 , 0.61244259, 0.7820166 , 0.7741081 , 0.87677312, 0.63147717, 0.51546283, 0.71272935, 0.93485537, 0.79408756, 0.72228448, 0.68098843, 0.70650313, 0.73308506, 0.4805125 , 0.57954561, 0.93776656, 0.77561424, 0.66655529, 0.59547518, 0.76751515, 0.57312122, 0.50621332, 0.5308715 , 0.52295261, 0.79720566, 0.62933004, 0.46812934, 0.81995741, 0.60723799, 0.63667661, 0.63023046, 0.60081393, 0.54905189, 0.54151156, 0.67785878, 0.580275 , 0.48759392, 0.54008438, 0.7454827 , 0.4601459 , 0.47552149, 0.71676648, 0.72228072, 0.54215422, 0.85509146, 0.684061 , 0.56992491, 0.84343218, 0.58108193, 0.57400488, 0.7216718 , 0.70124307, 0.70769822, 0.89872242, 0.8115083 , 0.72059583, 0.57222288, 1. , 0.8366832 , 0.99252741, 0.70215306, 0.69084327, 0.71206105, 0.64219547, 0.81993542, 0.6896944 , 0.59591584, 0.6458122 , 0.50792736, 0.55944542, 0.63420523, 0.70343723, 0.7740387 , 0.70204359, 0.65253863, 0.81871625, 0.81911895, 0.68380948, 0.71220965, 0.54236837, 0.58017503, 0.6352586 , 0.62739849, 0.92329765, 0.85928619, 0.62316379, 0.56392299, 0.55616857, 0.4257328 , 0.43070972, 0.52466263, 0.54561821, 0.5264453 , 0.41628475, 0.49557027, 0.53537871, 0.53003824, 0.78154262, 0.53440301, 0.63876159, 0.59727845, 0.57348504, 0.72266752, 0.88323619, 0.67509495, 0.68280629, 0.76882837, 0.66983526, 0.70381398, 0.73990877, 0.6594292 , 0.83865735, 0.73595323, 0.56852858, 0.62116609, 0.52960021, 0.67721404, 0.65454618, 0.57113219, 0.55954835, 0.68309668, 0.64092662, 0.61267177, 0.58478466, 0.63905178, 0.56741971, 0.58706316, 0.63111636, 0.84924442, 0.89647751, 0.84943539, 0.68420327, 0.82623974, 0.70912897, 0.66280698, 0.60631287, 0.61775646, 0.54565334, 0.52431821, 0.77688667, 0.53243718, 0.45656482, 0.38411009, 0.42749903, 0.66954245, 0.49776812, 0.53883804, 0.56252938])
- datePandasIndex
PandasIndex(DatetimeIndex(['2018-04-02', '2018-04-09', '2018-04-16', '2018-04-23', '2018-04-30', '2018-05-07', '2018-05-14', '2018-05-21', '2018-05-28', '2018-06-04', ... '2021-06-28', '2021-07-05', '2021-07-12', '2021-07-19', '2021-07-26', '2021-08-02', '2021-08-09', '2021-08-16', '2021-08-23', '2021-08-30'], dtype='datetime64[ns]', name='date', length=179, freq=None))
- created_at :
- 2024-11-14T13:56:50.176001
- arviz_version :
- 0.17.1
- inference_library :
- numpyro
- inference_library_version :
- 0.15.2
- sampling_time :
- 14.669591
<xarray.Dataset> Size: 3kB Dimensions: (date: 179) Coordinates: * date (date) datetime64[ns] 1kB 2018-04-02 2018-04-09 ... 2021-08-30 Data variables: y (date) float64 1kB 0.4794 0.4527 0.5374 ... 0.4978 0.5388 0.5625 Attributes: created_at: 2024-11-14T13:56:50.176001 arviz_version: 0.17.1 inference_library: numpyro inference_library_version: 0.15.2 sampling_time: 14.669591xarray.Dataset -
- date: 179
- channel: 2
- control: 3
- date(date)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', '2019-01-07T00:00:00.000000000', '2019-01-14T00:00:00.000000000', '2019-01-21T00:00:00.000000000', '2019-01-28T00:00:00.000000000', '2019-02-04T00:00:00.000000000', '2019-02-11T00:00:00.000000000', '2019-02-18T00:00:00.000000000', '2019-02-25T00:00:00.000000000', '2019-03-04T00:00:00.000000000', '2019-03-11T00:00:00.000000000', '2019-03-18T00:00:00.000000000', '2019-03-25T00:00:00.000000000', '2019-04-01T00:00:00.000000000', '2019-04-08T00:00:00.000000000', '2019-04-15T00:00:00.000000000', '2019-04-22T00:00:00.000000000', '2019-04-29T00:00:00.000000000', '2019-05-06T00:00:00.000000000', '2019-05-13T00:00:00.000000000', '2019-05-20T00:00:00.000000000', '2019-05-27T00:00:00.000000000', '2019-06-03T00:00:00.000000000', '2019-06-10T00:00:00.000000000', '2019-06-17T00:00:00.000000000', '2019-06-24T00:00:00.000000000', '2019-07-01T00:00:00.000000000', '2019-07-08T00:00:00.000000000', '2019-07-15T00:00:00.000000000', '2019-07-22T00:00:00.000000000', '2019-07-29T00:00:00.000000000', '2019-08-05T00:00:00.000000000', '2019-08-12T00:00:00.000000000', '2019-08-19T00:00:00.000000000', '2019-08-26T00:00:00.000000000', '2019-09-02T00:00:00.000000000', '2019-09-09T00:00:00.000000000', '2019-09-16T00:00:00.000000000', '2019-09-23T00:00:00.000000000', '2019-09-30T00:00:00.000000000', '2019-10-07T00:00:00.000000000', '2019-10-14T00:00:00.000000000', '2019-10-21T00:00:00.000000000', '2019-10-28T00:00:00.000000000', '2019-11-04T00:00:00.000000000', '2019-11-11T00:00:00.000000000', '2019-11-18T00:00:00.000000000', '2019-11-25T00:00:00.000000000', '2019-12-02T00:00:00.000000000', '2019-12-09T00:00:00.000000000', '2019-12-16T00:00:00.000000000', '2019-12-23T00:00:00.000000000', '2019-12-30T00:00:00.000000000', '2020-01-06T00:00:00.000000000', '2020-01-13T00:00:00.000000000', '2020-01-20T00:00:00.000000000', '2020-01-27T00:00:00.000000000', '2020-02-03T00:00:00.000000000', '2020-02-10T00:00:00.000000000', '2020-02-17T00:00:00.000000000', '2020-02-24T00:00:00.000000000', '2020-03-02T00:00:00.000000000', '2020-03-09T00:00:00.000000000', '2020-03-16T00:00:00.000000000', '2020-03-23T00:00:00.000000000', '2020-03-30T00:00:00.000000000', '2020-04-06T00:00:00.000000000', '2020-04-13T00:00:00.000000000', '2020-04-20T00:00:00.000000000', '2020-04-27T00:00:00.000000000', '2020-05-04T00:00:00.000000000', '2020-05-11T00:00:00.000000000', '2020-05-18T00:00:00.000000000', '2020-05-25T00:00:00.000000000', '2020-06-01T00:00:00.000000000', '2020-06-08T00:00:00.000000000', '2020-06-15T00:00:00.000000000', '2020-06-22T00:00:00.000000000', '2020-06-29T00:00:00.000000000', '2020-07-06T00:00:00.000000000', '2020-07-13T00:00:00.000000000', '2020-07-20T00:00:00.000000000', '2020-07-27T00:00:00.000000000', '2020-08-03T00:00:00.000000000', '2020-08-10T00:00:00.000000000', '2020-08-17T00:00:00.000000000', '2020-08-24T00:00:00.000000000', '2020-08-31T00:00:00.000000000', '2020-09-07T00:00:00.000000000', '2020-09-14T00:00:00.000000000', '2020-09-21T00:00:00.000000000', '2020-09-28T00:00:00.000000000', '2020-10-05T00:00:00.000000000', '2020-10-12T00:00:00.000000000', '2020-10-19T00:00:00.000000000', '2020-10-26T00:00:00.000000000', '2020-11-02T00:00:00.000000000', '2020-11-09T00:00:00.000000000', '2020-11-16T00:00:00.000000000', '2020-11-23T00:00:00.000000000', '2020-11-30T00:00:00.000000000', '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]') - channel(channel)<U2'x1' 'x2'
array(['x1', 'x2'], dtype='<U2')
- control(control)<U7'event_1' 'event_2' 't'
array(['event_1', 'event_2', 't'], dtype='<U7')
- channel_data(date, channel)float640.3196 0.0 0.1128 ... 0.4403 0.0
array([[3.19648241e-01, 0.00000000e+00], [1.12765324e-01, 0.00000000e+00], [2.93380707e-01, 0.00000000e+00], [7.16379574e-02, 0.00000000e+00], [3.88041940e-01, 0.00000000e+00], [4.73291540e-02, 0.00000000e+00], [4.25671645e-01, 0.00000000e+00], [3.35039834e-01, 8.84759215e-01], [2.53918849e-01, 0.00000000e+00], [9.41199784e-01, 0.00000000e+00], [4.26630818e-01, 0.00000000e+00], [3.64360623e-01, 0.00000000e+00], [4.42975062e-01, 0.00000000e+00], [4.24530352e-01, 9.69641782e-01], [3.29493374e-01, 0.00000000e+00], [9.25031639e-01, 0.00000000e+00], [3.09048312e-01, 0.00000000e+00], [9.12534800e-01, 0.00000000e+00], [2.51539259e-01, 0.00000000e+00], [2.37266186e-01, 0.00000000e+00], ... [1.70332079e-01, 9.38381372e-01], [4.29038699e-01, 9.20516422e-01], [9.13487319e-01, 0.00000000e+00], [1.42944657e-01, 0.00000000e+00], [1.86838303e-01, 8.55514629e-01], [3.14421972e-01, 0.00000000e+00], [4.00678428e-01, 0.00000000e+00], [1.45069138e-01, 0.00000000e+00], [1.48471239e-01, 0.00000000e+00], [7.00777532e-02, 0.00000000e+00], [1.99103276e-01, 0.00000000e+00], [3.62700587e-01, 9.14000224e-01], [2.41143360e-01, 0.00000000e+00], [4.05094103e-02, 0.00000000e+00], [6.76832332e-02, 0.00000000e+00], [3.31349195e-02, 0.00000000e+00], [1.66170470e-01, 8.68233263e-01], [1.72458556e-01, 0.00000000e+00], [2.81197012e-01, 0.00000000e+00], [4.40328682e-01, 0.00000000e+00]]) - control_data(date, control)float640.0 0.0 0.0 0.0 ... 0.0 0.0 178.0
array([[ 0., 0., 0.], [ 0., 0., 1.], [ 0., 0., 2.], [ 0., 0., 3.], [ 0., 0., 4.], [ 0., 0., 5.], [ 0., 0., 6.], [ 0., 0., 7.], [ 0., 0., 8.], [ 0., 0., 9.], [ 0., 0., 10.], [ 0., 0., 11.], [ 0., 0., 12.], [ 0., 0., 13.], [ 0., 0., 14.], [ 0., 0., 15.], [ 0., 0., 16.], [ 0., 0., 17.], [ 0., 0., 18.], [ 0., 0., 19.], ... [ 0., 0., 159.], [ 0., 0., 160.], [ 0., 0., 161.], [ 0., 0., 162.], [ 0., 0., 163.], [ 0., 0., 164.], [ 0., 0., 165.], [ 0., 0., 166.], [ 0., 0., 167.], [ 0., 0., 168.], [ 0., 0., 169.], [ 0., 0., 170.], [ 0., 0., 171.], [ 0., 0., 172.], [ 0., 0., 173.], [ 0., 0., 174.], [ 0., 0., 175.], [ 0., 0., 176.], [ 0., 0., 177.], [ 0., 0., 178.]]) - dayofyear(date)int3292 99 106 113 ... 221 228 235 242
array([ 92, 99, 106, 113, 120, 127, 134, 141, 148, 155, 162, 169, 176, 183, 190, 197, 204, 211, 218, 225, 232, 239, 246, 253, 260, 267, 274, 281, 288, 295, 302, 309, 316, 323, 330, 337, 344, 351, 358, 365, 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84, 91, 98, 105, 112, 119, 126, 133, 140, 147, 154, 161, 168, 175, 182, 189, 196, 203, 210, 217, 224, 231, 238, 245, 252, 259, 266, 273, 280, 287, 294, 301, 308, 315, 322, 329, 336, 343, 350, 357, 364, 6, 13, 20, 27, 34, 41, 48, 55, 62, 69, 76, 83, 90, 97, 104, 111, 118, 125, 132, 139, 146, 153, 160, 167, 174, 181, 188, 195, 202, 209, 216, 223, 230, 237, 244, 251, 258, 265, 272, 279, 286, 293, 300, 307, 314, 321, 328, 335, 342, 349, 356, 363, 4, 11, 18, 25, 32, 39, 46, 53, 60, 67, 74, 81, 88, 95, 102, 109, 116, 123, 130, 137, 144, 151, 158, 165, 172, 179, 186, 193, 200, 207, 214, 221, 228, 235, 242], dtype=int32)
- datePandasIndex
PandasIndex(DatetimeIndex(['2018-04-02', '2018-04-09', '2018-04-16', '2018-04-23', '2018-04-30', '2018-05-07', '2018-05-14', '2018-05-21', '2018-05-28', '2018-06-04', ... '2021-06-28', '2021-07-05', '2021-07-12', '2021-07-19', '2021-07-26', '2021-08-02', '2021-08-09', '2021-08-16', '2021-08-23', '2021-08-30'], dtype='datetime64[ns]', name='date', length=179, freq=None)) - channelPandasIndex
PandasIndex(Index(['x1', 'x2'], dtype='object', name='channel'))
- controlPandasIndex
PandasIndex(Index(['event_1', 'event_2', 't'], dtype='object', name='control'))
- created_at :
- 2024-11-14T13:56:50.177660
- arviz_version :
- 0.17.1
- inference_library :
- numpyro
- inference_library_version :
- 0.15.2
- sampling_time :
- 14.669591
<xarray.Dataset> Size: 9kB Dimensions: (date: 179, channel: 2, control: 3) Coordinates: * date (date) datetime64[ns] 1kB 2018-04-02 2018-04-09 ... 2021-08-30 * channel (channel) <U2 16B 'x1' 'x2' * control (control) <U7 84B 'event_1' 'event_2' 't' Data variables: channel_data (date, channel) float64 3kB 0.3196 0.0 0.1128 ... 0.4403 0.0 control_data (date, control) float64 4kB 0.0 0.0 0.0 0.0 ... 0.0 0.0 178.0 dayofyear (date) int32 716B 92 99 106 113 120 ... 214 221 228 235 242 Attributes: created_at: 2024-11-14T13:56:50.177660 arviz_version: 0.17.1 inference_library: numpyro inference_library_version: 0.15.2 sampling_time: 14.669591xarray.Dataset -
- index: 179
- index(index)int640 1 2 3 4 5 ... 174 175 176 177 178
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178])
- date_week(index)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', ... '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]') - x1(index)float640.3186 0.1124 ... 0.2803 0.4389
array([3.18580018e-01, 1.12388476e-01, 2.92400266e-01, 7.13985526e-02, 3.86745154e-01, 4.71709861e-02, 4.24249105e-01, 3.33920175e-01, 2.53070285e-01, 9.38054416e-01, 4.25205073e-01, 3.63142977e-01, 4.41494696e-01, 4.23111626e-01, 3.28392249e-01, 9.21940303e-01, 3.08015512e-01, 9.09485226e-01, 2.50698647e-01, 2.36473273e-01, 4.03137932e-01, 1.47177719e-01, 3.63041014e-01, 1.47066490e-01, 9.46704311e-02, 2.59245305e-01, 5.74838249e-02, 2.06465328e-02, 1.65636049e-01, 2.14007141e-01, 3.60517692e-01, 1.22368556e-01, 9.58683953e-01, 3.21972344e-01, 2.53234055e-01, 6.40119796e-02, 2.36553200e-02, 1.83164569e-01, 9.25302245e-01, 9.96658129e-01, 4.01689634e-01, 1.73745461e-01, 9.55372645e-01, 3.55889419e-01, 9.29181335e-04, 4.37815667e-01, 9.73976316e-01, 9.77903945e-01, 2.48141704e-01, 4.05620409e-01, 2.49040963e-01, 5.30524844e-02, 6.63217207e-02, 9.19314691e-02, 2.84652565e-01, 3.73845327e-01, 3.11033721e-01, 1.08200596e-02, 3.25854693e-01, 4.30160827e-01, 4.42189999e-01, 2.68919050e-01, 3.84406892e-01, 3.03780772e-01, 2.22092463e-01, 9.84087017e-01, 1.78161753e-01, 1.52862615e-01, 4.32812209e-01, 3.80735892e-01, 1.33810881e-01, 2.18715931e-01, 3.24034681e-01, 3.66676692e-01, 1.50298760e-01, 9.31123777e-01, 2.99199062e-01, 1.59348190e-01, 4.49282836e-01, 9.18307179e-03, ... 2.83962083e-01, 4.29271667e-01, 1.55574946e-01, 1.07068213e-01, 4.46958034e-01, 3.53012159e-01, 4.05501510e-01, 9.95101996e-01, 1.95552073e-01, 4.21105629e-01, 3.89127721e-02, 2.74762370e-01, 3.88551689e-01, 3.98177912e-01, 9.30166751e-01, 2.59848823e-01, 1.94820914e-01, 2.58231310e-01, 3.02189662e-01, 1.03497234e-01, 8.01700983e-02, 4.15976836e-01, 3.96173495e-01, 4.43288434e-01, 6.38882192e-02, 2.56961240e-01, 4.16716500e-01, 1.89344301e-01, 1.21168779e-02, 3.07204390e-01, 2.79346139e-01, 1.55859670e-01, 2.51259804e-01, 4.15636348e-01, 1.50413447e-01, 4.18457229e-02, 2.92710243e-01, 3.91623929e-01, 9.89705226e-02, 2.68473040e-01, 3.63484578e-01, 1.85363200e-01, 6.59774982e-02, 3.54568453e-01, 1.59422721e-01, 1.81976239e-01, 1.16747054e-01, 3.23780216e-01, 4.34122877e-01, 1.08988007e-01, 1.61353829e-01, 9.42322052e-01, 8.52032642e-02, 3.25819647e-01, 1.67913280e-01, 3.39621958e-01, 2.52901858e-01, 8.64855399e-02, 3.37226955e-01, 1.69762852e-01, 4.27604907e-01, 9.10434562e-01, 1.42466955e-01, 1.86213914e-01, 3.13371214e-01, 3.99339412e-01, 1.44584335e-01, 1.47975068e-01, 6.98435624e-02, 1.98437898e-01, 3.61488489e-01, 2.40337490e-01, 4.03740331e-02, 6.74570446e-02, 3.30241869e-02, 1.65615150e-01, 1.71882222e-01, 2.80257288e-01, 4.38857161e-01]) - x2(index)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0
array([0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.87978184, 0. , 0. , 0. , 0. , 0. , 0.96418688, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.80062317, 0. , 0. , 0. , 0.8535269 , 0. , 0. , 0.98859712, 0.87047511, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.9748662 , 0. , 0. , 0. , 0.90257287, 0. , 0. , 0. , 0. , 0.99437431, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.95798229, 0. , 0. , 0.88604706, 0.84193305, 0. , 0.91253659, 0. , 0. , 0.99123254, 0. , 0. , 0.95581799, 0.91704461, 0. , 0.80904352, 0. , 0. , 0. , 0.86960149, 0. , 0.9208528 , 0. , 0. , 0. , 0. , 0.99390622, 0. , 0. , 0. , 0. , 0. , 0. , 0.93665676, 0.9093652 , 0. , 0. , 0.80688306, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.89397651, 0.86774976, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.83998152, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.96018382, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.93310233, 0.91533788, 0. , 0. , 0.85070177, 0. , 0. , 0. , 0. , 0. , 0. , 0.90885834, 0. , 0. , 0. , 0. , 0.86334885, 0. , 0. , 0. ]) - event_1(index)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) - event_2(index)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) - dayofyear(index)int6492 99 106 113 ... 221 228 235 242
array([ 92, 99, 106, 113, 120, 127, 134, 141, 148, 155, 162, 169, 176, 183, 190, 197, 204, 211, 218, 225, 232, 239, 246, 253, 260, 267, 274, 281, 288, 295, 302, 309, 316, 323, 330, 337, 344, 351, 358, 365, 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84, 91, 98, 105, 112, 119, 126, 133, 140, 147, 154, 161, 168, 175, 182, 189, 196, 203, 210, 217, 224, 231, 238, 245, 252, 259, 266, 273, 280, 287, 294, 301, 308, 315, 322, 329, 336, 343, 350, 357, 364, 6, 13, 20, 27, 34, 41, 48, 55, 62, 69, 76, 83, 90, 97, 104, 111, 118, 125, 132, 139, 146, 153, 160, 167, 174, 181, 188, 195, 202, 209, 216, 223, 230, 237, 244, 251, 258, 265, 272, 279, 286, 293, 300, 307, 314, 321, 328, 335, 342, 349, 356, 363, 4, 11, 18, 25, 32, 39, 46, 53, 60, 67, 74, 81, 88, 95, 102, 109, 116, 123, 130, 137, 144, 151, 158, 165, 172, 179, 186, 193, 200, 207, 214, 221, 228, 235, 242]) - t(index)int640 1 2 3 4 5 ... 174 175 176 177 178
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178]) - y(index)float643.985e+03 3.763e+03 ... 4.676e+03
array([3984.66223734, 3762.87179412, 4466.96738844, 3864.21937266, 4441.62527775, 3677.39655018, 5067.54633687, 6079.09904219, 4954.20536859, 5865.67657627, 5096.63305051, 4991.54228314, 4688.5848447 , 6536.34574052, 5030.98358508, 4638.69083472, 4209.54579837, 4876.00838907, 3906.171689 , 3549.86212243, 4025.43395537, 3223.30633321, 4079.65295872, 4156.43557336, 3666.8772267 , 3853.54920598, 3531.47191787, 3538.8824745 , 4261.17449177, 4604.51723377, 6484.97624603, 5090.8724376 , 6500.44070675, 6434.7020032 , 7288.09549867, 5249.09562308, 4284.73710406, 5924.4967947 , 7770.89886433, 6600.77946045, 6003.92292284, 5660.65332884, 5872.74193171, 6093.70178134, 3994.21575864, 4817.41932661, 7795.0978095 , 6447.22166693, 5540.6792271 , 4949.83235925, 6379.8986888 , 4764.01718599, 4207.85140173, 4412.82026656, 4346.99520328, 6626.69831268, 5231.24779003, 3891.28186583, 6815.82014683, 5047.60961099, 5292.31541818, 5238.73239384, 4994.21021861, 4563.9431011 , 4501.26480448, 5634.63844969, 4823.48226687, 4053.07938257, 4489.40147834, 6196.75603817, 3824.9202315 , 3952.72844853, 5958.05509279, 6003.89166699, 4506.60683165, 7107.8687139 , 5686.19380778, 4737.44808553, 7010.95204787, 4830.18985388, ... 4650.33832006, 5271.77236249, 5847.25691642, 6434.12509649, 5835.67243843, 5424.16703016, 6805.503155 , 6808.85054468, 5684.10310247, 5920.17689413, 4508.38691899, 4822.65128872, 5280.52839424, 5215.19196501, 7674.82634251, 7142.73704187, 5179.99140594, 4687.55775271, 4623.09983189, 3538.8645019 , 3580.23476566, 4361.20963926, 4535.40095043, 4376.02791122, 3460.32851473, 4119.38208881, 4450.28600415, 4405.89387854, 6496.50077682, 4442.17560168, 5309.6466714 , 4964.82187487, 4767.04140224, 6007.10694272, 7341.81915474, 5611.66436779, 5675.76416319, 6390.81472343, 5567.94366983, 5850.38866634, 6150.42324303, 5481.44428281, 6971.26166534, 6117.54314155, 4725.84123847, 5163.38572629, 4402.2528145 , 5629.27905386, 5440.85463743, 4747.48354262, 4651.19391143, 5678.17799695, 5327.64323813, 5092.77743153, 4860.96843213, 5312.05880983, 4716.62387739, 4879.90820541, 5246.0963942 , 7059.26575537, 7451.88641636, 7060.8531078 , 5687.37638691, 6868.04144218, 5894.56896391, 5509.52170002, 5039.91969411, 5135.04343508, 4535.6929473 , 4358.34664039, 6457.79858878, 4425.83485865, 3795.15282441, 3192.87959337, 3553.54614781, 5565.50968216, 4137.65148493, 4479.04135141, 4675.97343867])
- indexPandasIndex
PandasIndex(RangeIndex(start=0, stop=179, step=1, name='index'))
<xarray.Dataset> Size: 13kB Dimensions: (index: 179) Coordinates: * index (index) int64 1kB 0 1 2 3 4 5 6 7 ... 172 173 174 175 176 177 178 Data variables: date_week (index) datetime64[ns] 1kB 2018-04-02 2018-04-09 ... 2021-08-30 x1 (index) float64 1kB 0.3186 0.1124 0.2924 ... 0.1719 0.2803 0.4389 x2 (index) float64 1kB 0.0 0.0 0.0 0.0 0.0 ... 0.8633 0.0 0.0 0.0 event_1 (index) float64 1kB 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 event_2 (index) float64 1kB 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 dayofyear (index) int64 1kB 92 99 106 113 120 127 ... 214 221 228 235 242 t (index) int64 1kB 0 1 2 3 4 5 6 7 ... 172 173 174 175 176 177 178 y (index) float64 1kB 3.985e+03 3.763e+03 ... 4.479e+03 4.676e+03xarray.Dataset
Guardando y cargando un modelo ajustado#
Todos los datos pasados al modelo en la inicialización se almacenan en idata.attrs. Esto se utilizará más tarde en el método save() para convertir tanto estos datos como todos los datos de ajuste en el formato netCDF. Puedes leer más sobre este formato aquí.
El método save y el método load solo requieren una ruta para informar dónde se debe guardar y cargar el modelo.
mmm.save("my_saved_model.nc")
loaded_model = MMM.load("my_saved_model.nc")
loaded_model.model_config["saturation_beta"]
Prior("HalfNormal", sigma=[2.1775326 1.14026088], dims="channel")
loaded_model.idata.attrs
{'id': 'cbf06a279ecf0af6',
'model_type': 'MMM',
'version': '0.0.2',
'sampler_config': '{"tune": 1000, "draws": 1000, "chains": 4, "target_accept": 0.91, "nuts_sampler": "numpyro"}',
'model_config': '{"intercept": {"dist": "Normal", "kwargs": {"mu": 0, "sigma": 2}}, "likelihood": {"dist": "Normal", "kwargs": {"sigma": {"dist": "HalfNormal", "kwargs": {"sigma": 2}}}, "dims": ["date"]}, "gamma_control": {"dist": "Normal", "kwargs": {"mu": 0, "sigma": 2}, "dims": ["control"]}, "gamma_fourier": {"dist": "Laplace", "kwargs": {"mu": 0, "b": 1}, "dims": ["fourier_mode"]}, "adstock_alpha": {"dist": "Beta", "kwargs": {"alpha": 1, "beta": 3}, "dims": ["channel"]}, "saturation_lam": {"dist": "Gamma", "kwargs": {"alpha": 3, "beta": 1}, "dims": ["channel"]}, "saturation_beta": {"dist": "HalfNormal", "kwargs": {"sigma": [2.1775326025486734, 1.140260877391939]}, "dims": ["channel"]}}',
'date_column': '"date_week"',
'adstock': '{"lookup_name": "geometric", "prefix": "adstock", "priors": {"alpha": {"dist": "Beta", "kwargs": {"alpha": 1, "beta": 3}, "dims": ["channel"]}}, "l_max": 8, "normalize": true, "mode": "After"}',
'saturation': '{"lookup_name": "logistic", "prefix": "saturation", "priors": {"lam": {"dist": "Gamma", "kwargs": {"alpha": 3, "beta": 1}, "dims": ["channel"]}, "beta": {"dist": "HalfNormal", "kwargs": {"sigma": [2.1775326025486734, 1.140260877391939]}, "dims": ["channel"]}}}',
'adstock_first': 'true',
'control_columns': '["event_1", "event_2", "t"]',
'channel_columns': '["x1", "x2"]',
'validate_data': 'true',
'yearly_seasonality': '2',
'time_varying_intercept': 'false',
'time_varying_media': 'false'}
loaded_model.graphviz()
loaded_model.idata
-
- chain: 4
- draw: 1000
- control: 3
- fourier_mode: 4
- channel: 2
- date: 179
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 5 ... 995 996 997 998 999
array([ 0, 1, 2, ..., 997, 998, 999])
- control(control)<U7'event_1' 'event_2' 't'
array(['event_1', 'event_2', 't'], dtype='<U7')
- fourier_mode(fourier_mode)<U5'sin_1' 'sin_2' 'cos_1' 'cos_2'
array(['sin_1', 'sin_2', 'cos_1', 'cos_2'], dtype='<U5')
- channel(channel)<U2'x1' 'x2'
array(['x1', 'x2'], dtype='<U2')
- date(date)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', '2019-01-07T00:00:00.000000000', '2019-01-14T00:00:00.000000000', '2019-01-21T00:00:00.000000000', '2019-01-28T00:00:00.000000000', '2019-02-04T00:00:00.000000000', '2019-02-11T00:00:00.000000000', '2019-02-18T00:00:00.000000000', '2019-02-25T00:00:00.000000000', '2019-03-04T00:00:00.000000000', '2019-03-11T00:00:00.000000000', '2019-03-18T00:00:00.000000000', '2019-03-25T00:00:00.000000000', '2019-04-01T00:00:00.000000000', '2019-04-08T00:00:00.000000000', '2019-04-15T00:00:00.000000000', '2019-04-22T00:00:00.000000000', '2019-04-29T00:00:00.000000000', '2019-05-06T00:00:00.000000000', '2019-05-13T00:00:00.000000000', '2019-05-20T00:00:00.000000000', '2019-05-27T00:00:00.000000000', '2019-06-03T00:00:00.000000000', '2019-06-10T00:00:00.000000000', '2019-06-17T00:00:00.000000000', '2019-06-24T00:00:00.000000000', '2019-07-01T00:00:00.000000000', '2019-07-08T00:00:00.000000000', '2019-07-15T00:00:00.000000000', '2019-07-22T00:00:00.000000000', '2019-07-29T00:00:00.000000000', '2019-08-05T00:00:00.000000000', '2019-08-12T00:00:00.000000000', '2019-08-19T00:00:00.000000000', '2019-08-26T00:00:00.000000000', '2019-09-02T00:00:00.000000000', '2019-09-09T00:00:00.000000000', '2019-09-16T00:00:00.000000000', '2019-09-23T00:00:00.000000000', '2019-09-30T00:00:00.000000000', '2019-10-07T00:00:00.000000000', '2019-10-14T00:00:00.000000000', '2019-10-21T00:00:00.000000000', '2019-10-28T00:00:00.000000000', '2019-11-04T00:00:00.000000000', '2019-11-11T00:00:00.000000000', '2019-11-18T00:00:00.000000000', '2019-11-25T00:00:00.000000000', '2019-12-02T00:00:00.000000000', '2019-12-09T00:00:00.000000000', '2019-12-16T00:00:00.000000000', '2019-12-23T00:00:00.000000000', '2019-12-30T00:00:00.000000000', '2020-01-06T00:00:00.000000000', '2020-01-13T00:00:00.000000000', '2020-01-20T00:00:00.000000000', '2020-01-27T00:00:00.000000000', '2020-02-03T00:00:00.000000000', '2020-02-10T00:00:00.000000000', '2020-02-17T00:00:00.000000000', '2020-02-24T00:00:00.000000000', '2020-03-02T00:00:00.000000000', '2020-03-09T00:00:00.000000000', '2020-03-16T00:00:00.000000000', '2020-03-23T00:00:00.000000000', '2020-03-30T00:00:00.000000000', '2020-04-06T00:00:00.000000000', '2020-04-13T00:00:00.000000000', '2020-04-20T00:00:00.000000000', '2020-04-27T00:00:00.000000000', '2020-05-04T00:00:00.000000000', '2020-05-11T00:00:00.000000000', '2020-05-18T00:00:00.000000000', '2020-05-25T00:00:00.000000000', '2020-06-01T00:00:00.000000000', '2020-06-08T00:00:00.000000000', '2020-06-15T00:00:00.000000000', '2020-06-22T00:00:00.000000000', '2020-06-29T00:00:00.000000000', '2020-07-06T00:00:00.000000000', '2020-07-13T00:00:00.000000000', '2020-07-20T00:00:00.000000000', '2020-07-27T00:00:00.000000000', '2020-08-03T00:00:00.000000000', '2020-08-10T00:00:00.000000000', '2020-08-17T00:00:00.000000000', '2020-08-24T00:00:00.000000000', '2020-08-31T00:00:00.000000000', '2020-09-07T00:00:00.000000000', '2020-09-14T00:00:00.000000000', '2020-09-21T00:00:00.000000000', '2020-09-28T00:00:00.000000000', '2020-10-05T00:00:00.000000000', '2020-10-12T00:00:00.000000000', '2020-10-19T00:00:00.000000000', '2020-10-26T00:00:00.000000000', '2020-11-02T00:00:00.000000000', '2020-11-09T00:00:00.000000000', '2020-11-16T00:00:00.000000000', '2020-11-23T00:00:00.000000000', '2020-11-30T00:00:00.000000000', '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]')
- intercept(chain, draw)float64...
[4000 values with dtype=float64]
- gamma_control(chain, draw, control)float64...
[12000 values with dtype=float64]
- gamma_fourier(chain, draw, fourier_mode)float64...
[16000 values with dtype=float64]
- adstock_alpha(chain, draw, channel)float64...
[8000 values with dtype=float64]
- saturation_lam(chain, draw, channel)float64...
[8000 values with dtype=float64]
- saturation_beta(chain, draw, channel)float64...
[8000 values with dtype=float64]
- y_sigma(chain, draw)float64...
[4000 values with dtype=float64]
- channel_contributions(chain, draw, date, channel)float64...
[1432000 values with dtype=float64]
- control_contributions(chain, draw, date, control)float64...
[2148000 values with dtype=float64]
- fourier_contributions(chain, draw, date, fourier_mode)float64...
[2864000 values with dtype=float64]
- yearly_seasonality_contribution(chain, draw, date)float64...
[716000 values with dtype=float64]
- mu(chain, draw, date)float64...
[716000 values with dtype=float64]
- chainPandasIndex
PandasIndex(Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 990, 991, 992, 993, 994, 995, 996, 997, 998, 999], dtype='int64', name='draw', length=1000)) - controlPandasIndex
PandasIndex(Index(['event_1', 'event_2', 't'], dtype='object', name='control'))
- fourier_modePandasIndex
PandasIndex(Index(['sin_1', 'sin_2', 'cos_1', 'cos_2'], dtype='object', name='fourier_mode'))
- channelPandasIndex
PandasIndex(Index(['x1', 'x2'], dtype='object', name='channel'))
- datePandasIndex
PandasIndex(DatetimeIndex(['2018-04-02', '2018-04-09', '2018-04-16', '2018-04-23', '2018-04-30', '2018-05-07', '2018-05-14', '2018-05-21', '2018-05-28', '2018-06-04', ... '2021-06-28', '2021-07-05', '2021-07-12', '2021-07-19', '2021-07-26', '2021-08-02', '2021-08-09', '2021-08-16', '2021-08-23', '2021-08-30'], dtype='datetime64[ns]', name='date', length=179, freq=None))
- created_at :
- 2024-11-14T13:56:50.170234
- arviz_version :
- 0.17.1
<xarray.Dataset> Size: 63MB Dimensions: (chain: 4, draw: 1000, control: 3, fourier_mode: 4, channel: 2, date: 179) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 ... 997 998 999 * control (control) <U7 84B 'event_1' 'event_2' 't' * fourier_mode (fourier_mode) <U5 80B 'sin_1' ... 'cos_2' * channel (channel) <U2 16B 'x1' 'x2' * date (date) datetime64[ns] 1kB 2018-04-02 ...... Data variables: intercept (chain, draw) float64 32kB ... gamma_control (chain, draw, control) float64 96kB ... gamma_fourier (chain, draw, fourier_mode) float64 128kB ... adstock_alpha (chain, draw, channel) float64 64kB ... saturation_lam (chain, draw, channel) float64 64kB ... saturation_beta (chain, draw, channel) float64 64kB ... y_sigma (chain, draw) float64 32kB ... channel_contributions (chain, draw, date, channel) float64 11MB ... control_contributions (chain, draw, date, control) float64 17MB ... fourier_contributions (chain, draw, date, fourier_mode) float64 23MB ... yearly_seasonality_contribution (chain, draw, date) float64 6MB ... mu (chain, draw, date) float64 6MB ... Attributes: created_at: 2024-11-14T13:56:50.170234 arviz_version: 0.17.1xarray.Dataset -
- chain: 4
- draw: 1000
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 5 ... 995 996 997 998 999
array([ 0, 1, 2, ..., 997, 998, 999])
- acceptance_rate(chain, draw)float64...
[4000 values with dtype=float64]
- step_size(chain, draw)float64...
[4000 values with dtype=float64]
- diverging(chain, draw)bool...
[4000 values with dtype=bool]
- energy(chain, draw)float64...
[4000 values with dtype=float64]
- n_steps(chain, draw)int64...
[4000 values with dtype=int64]
- tree_depth(chain, draw)int64...
[4000 values with dtype=int64]
- lp(chain, draw)float64...
[4000 values with dtype=float64]
- chainPandasIndex
PandasIndex(Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 990, 991, 992, 993, 994, 995, 996, 997, 998, 999], dtype='int64', name='draw', length=1000))
- created_at :
- 2024-11-14T13:56:50.174899
- arviz_version :
- 0.17.1
<xarray.Dataset> Size: 204kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 ... 994 995 996 997 998 999 Data variables: acceptance_rate (chain, draw) float64 32kB ... step_size (chain, draw) float64 32kB ... diverging (chain, draw) bool 4kB ... energy (chain, draw) float64 32kB ... n_steps (chain, draw) int64 32kB ... tree_depth (chain, draw) int64 32kB ... lp (chain, draw) float64 32kB ... Attributes: created_at: 2024-11-14T13:56:50.174899 arviz_version: 0.17.1xarray.Dataset -
- date: 179
- date(date)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', '2019-01-07T00:00:00.000000000', '2019-01-14T00:00:00.000000000', '2019-01-21T00:00:00.000000000', '2019-01-28T00:00:00.000000000', '2019-02-04T00:00:00.000000000', '2019-02-11T00:00:00.000000000', '2019-02-18T00:00:00.000000000', '2019-02-25T00:00:00.000000000', '2019-03-04T00:00:00.000000000', '2019-03-11T00:00:00.000000000', '2019-03-18T00:00:00.000000000', '2019-03-25T00:00:00.000000000', '2019-04-01T00:00:00.000000000', '2019-04-08T00:00:00.000000000', '2019-04-15T00:00:00.000000000', '2019-04-22T00:00:00.000000000', '2019-04-29T00:00:00.000000000', '2019-05-06T00:00:00.000000000', '2019-05-13T00:00:00.000000000', '2019-05-20T00:00:00.000000000', '2019-05-27T00:00:00.000000000', '2019-06-03T00:00:00.000000000', '2019-06-10T00:00:00.000000000', '2019-06-17T00:00:00.000000000', '2019-06-24T00:00:00.000000000', '2019-07-01T00:00:00.000000000', '2019-07-08T00:00:00.000000000', '2019-07-15T00:00:00.000000000', '2019-07-22T00:00:00.000000000', '2019-07-29T00:00:00.000000000', '2019-08-05T00:00:00.000000000', '2019-08-12T00:00:00.000000000', '2019-08-19T00:00:00.000000000', '2019-08-26T00:00:00.000000000', '2019-09-02T00:00:00.000000000', '2019-09-09T00:00:00.000000000', '2019-09-16T00:00:00.000000000', '2019-09-23T00:00:00.000000000', '2019-09-30T00:00:00.000000000', '2019-10-07T00:00:00.000000000', '2019-10-14T00:00:00.000000000', '2019-10-21T00:00:00.000000000', '2019-10-28T00:00:00.000000000', '2019-11-04T00:00:00.000000000', '2019-11-11T00:00:00.000000000', '2019-11-18T00:00:00.000000000', '2019-11-25T00:00:00.000000000', '2019-12-02T00:00:00.000000000', '2019-12-09T00:00:00.000000000', '2019-12-16T00:00:00.000000000', '2019-12-23T00:00:00.000000000', '2019-12-30T00:00:00.000000000', '2020-01-06T00:00:00.000000000', '2020-01-13T00:00:00.000000000', '2020-01-20T00:00:00.000000000', '2020-01-27T00:00:00.000000000', '2020-02-03T00:00:00.000000000', '2020-02-10T00:00:00.000000000', '2020-02-17T00:00:00.000000000', '2020-02-24T00:00:00.000000000', '2020-03-02T00:00:00.000000000', '2020-03-09T00:00:00.000000000', '2020-03-16T00:00:00.000000000', '2020-03-23T00:00:00.000000000', '2020-03-30T00:00:00.000000000', '2020-04-06T00:00:00.000000000', '2020-04-13T00:00:00.000000000', '2020-04-20T00:00:00.000000000', '2020-04-27T00:00:00.000000000', '2020-05-04T00:00:00.000000000', '2020-05-11T00:00:00.000000000', '2020-05-18T00:00:00.000000000', '2020-05-25T00:00:00.000000000', '2020-06-01T00:00:00.000000000', '2020-06-08T00:00:00.000000000', '2020-06-15T00:00:00.000000000', '2020-06-22T00:00:00.000000000', '2020-06-29T00:00:00.000000000', '2020-07-06T00:00:00.000000000', '2020-07-13T00:00:00.000000000', '2020-07-20T00:00:00.000000000', '2020-07-27T00:00:00.000000000', '2020-08-03T00:00:00.000000000', '2020-08-10T00:00:00.000000000', '2020-08-17T00:00:00.000000000', '2020-08-24T00:00:00.000000000', '2020-08-31T00:00:00.000000000', '2020-09-07T00:00:00.000000000', '2020-09-14T00:00:00.000000000', '2020-09-21T00:00:00.000000000', '2020-09-28T00:00:00.000000000', '2020-10-05T00:00:00.000000000', '2020-10-12T00:00:00.000000000', '2020-10-19T00:00:00.000000000', '2020-10-26T00:00:00.000000000', '2020-11-02T00:00:00.000000000', '2020-11-09T00:00:00.000000000', '2020-11-16T00:00:00.000000000', '2020-11-23T00:00:00.000000000', '2020-11-30T00:00:00.000000000', '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]')
- y(date)float64...
[179 values with dtype=float64]
- datePandasIndex
PandasIndex(DatetimeIndex(['2018-04-02', '2018-04-09', '2018-04-16', '2018-04-23', '2018-04-30', '2018-05-07', '2018-05-14', '2018-05-21', '2018-05-28', '2018-06-04', ... '2021-06-28', '2021-07-05', '2021-07-12', '2021-07-19', '2021-07-26', '2021-08-02', '2021-08-09', '2021-08-16', '2021-08-23', '2021-08-30'], dtype='datetime64[ns]', name='date', length=179, freq=None))
- created_at :
- 2024-11-14T13:56:50.176001
- arviz_version :
- 0.17.1
- inference_library :
- numpyro
- inference_library_version :
- 0.15.2
- sampling_time :
- 14.669591
<xarray.Dataset> Size: 3kB Dimensions: (date: 179) Coordinates: * date (date) datetime64[ns] 1kB 2018-04-02 2018-04-09 ... 2021-08-30 Data variables: y (date) float64 1kB ... Attributes: created_at: 2024-11-14T13:56:50.176001 arviz_version: 0.17.1 inference_library: numpyro inference_library_version: 0.15.2 sampling_time: 14.669591xarray.Dataset -
- date: 179
- channel: 2
- control: 3
- date(date)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', '2019-01-07T00:00:00.000000000', '2019-01-14T00:00:00.000000000', '2019-01-21T00:00:00.000000000', '2019-01-28T00:00:00.000000000', '2019-02-04T00:00:00.000000000', '2019-02-11T00:00:00.000000000', '2019-02-18T00:00:00.000000000', '2019-02-25T00:00:00.000000000', '2019-03-04T00:00:00.000000000', '2019-03-11T00:00:00.000000000', '2019-03-18T00:00:00.000000000', '2019-03-25T00:00:00.000000000', '2019-04-01T00:00:00.000000000', '2019-04-08T00:00:00.000000000', '2019-04-15T00:00:00.000000000', '2019-04-22T00:00:00.000000000', '2019-04-29T00:00:00.000000000', '2019-05-06T00:00:00.000000000', '2019-05-13T00:00:00.000000000', '2019-05-20T00:00:00.000000000', '2019-05-27T00:00:00.000000000', '2019-06-03T00:00:00.000000000', '2019-06-10T00:00:00.000000000', '2019-06-17T00:00:00.000000000', '2019-06-24T00:00:00.000000000', '2019-07-01T00:00:00.000000000', '2019-07-08T00:00:00.000000000', '2019-07-15T00:00:00.000000000', '2019-07-22T00:00:00.000000000', '2019-07-29T00:00:00.000000000', '2019-08-05T00:00:00.000000000', '2019-08-12T00:00:00.000000000', '2019-08-19T00:00:00.000000000', '2019-08-26T00:00:00.000000000', '2019-09-02T00:00:00.000000000', '2019-09-09T00:00:00.000000000', '2019-09-16T00:00:00.000000000', '2019-09-23T00:00:00.000000000', '2019-09-30T00:00:00.000000000', '2019-10-07T00:00:00.000000000', '2019-10-14T00:00:00.000000000', '2019-10-21T00:00:00.000000000', '2019-10-28T00:00:00.000000000', '2019-11-04T00:00:00.000000000', '2019-11-11T00:00:00.000000000', '2019-11-18T00:00:00.000000000', '2019-11-25T00:00:00.000000000', '2019-12-02T00:00:00.000000000', '2019-12-09T00:00:00.000000000', '2019-12-16T00:00:00.000000000', '2019-12-23T00:00:00.000000000', '2019-12-30T00:00:00.000000000', '2020-01-06T00:00:00.000000000', '2020-01-13T00:00:00.000000000', '2020-01-20T00:00:00.000000000', '2020-01-27T00:00:00.000000000', '2020-02-03T00:00:00.000000000', '2020-02-10T00:00:00.000000000', '2020-02-17T00:00:00.000000000', '2020-02-24T00:00:00.000000000', '2020-03-02T00:00:00.000000000', '2020-03-09T00:00:00.000000000', '2020-03-16T00:00:00.000000000', '2020-03-23T00:00:00.000000000', '2020-03-30T00:00:00.000000000', '2020-04-06T00:00:00.000000000', '2020-04-13T00:00:00.000000000', '2020-04-20T00:00:00.000000000', '2020-04-27T00:00:00.000000000', '2020-05-04T00:00:00.000000000', '2020-05-11T00:00:00.000000000', '2020-05-18T00:00:00.000000000', '2020-05-25T00:00:00.000000000', '2020-06-01T00:00:00.000000000', '2020-06-08T00:00:00.000000000', '2020-06-15T00:00:00.000000000', '2020-06-22T00:00:00.000000000', '2020-06-29T00:00:00.000000000', '2020-07-06T00:00:00.000000000', '2020-07-13T00:00:00.000000000', '2020-07-20T00:00:00.000000000', '2020-07-27T00:00:00.000000000', '2020-08-03T00:00:00.000000000', '2020-08-10T00:00:00.000000000', '2020-08-17T00:00:00.000000000', '2020-08-24T00:00:00.000000000', '2020-08-31T00:00:00.000000000', '2020-09-07T00:00:00.000000000', '2020-09-14T00:00:00.000000000', '2020-09-21T00:00:00.000000000', '2020-09-28T00:00:00.000000000', '2020-10-05T00:00:00.000000000', '2020-10-12T00:00:00.000000000', '2020-10-19T00:00:00.000000000', '2020-10-26T00:00:00.000000000', '2020-11-02T00:00:00.000000000', '2020-11-09T00:00:00.000000000', '2020-11-16T00:00:00.000000000', '2020-11-23T00:00:00.000000000', '2020-11-30T00:00:00.000000000', '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]') - channel(channel)<U2'x1' 'x2'
array(['x1', 'x2'], dtype='<U2')
- control(control)<U7'event_1' 'event_2' 't'
array(['event_1', 'event_2', 't'], dtype='<U7')
- channel_data(date, channel)float64...
[358 values with dtype=float64]
- control_data(date, control)float64...
[537 values with dtype=float64]
- dayofyear(date)int32...
[179 values with dtype=int32]
- datePandasIndex
PandasIndex(DatetimeIndex(['2018-04-02', '2018-04-09', '2018-04-16', '2018-04-23', '2018-04-30', '2018-05-07', '2018-05-14', '2018-05-21', '2018-05-28', '2018-06-04', ... '2021-06-28', '2021-07-05', '2021-07-12', '2021-07-19', '2021-07-26', '2021-08-02', '2021-08-09', '2021-08-16', '2021-08-23', '2021-08-30'], dtype='datetime64[ns]', name='date', length=179, freq=None)) - channelPandasIndex
PandasIndex(Index(['x1', 'x2'], dtype='object', name='channel'))
- controlPandasIndex
PandasIndex(Index(['event_1', 'event_2', 't'], dtype='object', name='control'))
- created_at :
- 2024-11-14T13:56:50.177660
- arviz_version :
- 0.17.1
- inference_library :
- numpyro
- inference_library_version :
- 0.15.2
- sampling_time :
- 14.669591
<xarray.Dataset> Size: 9kB Dimensions: (date: 179, channel: 2, control: 3) Coordinates: * date (date) datetime64[ns] 1kB 2018-04-02 2018-04-09 ... 2021-08-30 * channel (channel) <U2 16B 'x1' 'x2' * control (control) <U7 84B 'event_1' 'event_2' 't' Data variables: channel_data (date, channel) float64 3kB ... control_data (date, control) float64 4kB ... dayofyear (date) int32 716B ... Attributes: created_at: 2024-11-14T13:56:50.177660 arviz_version: 0.17.1 inference_library: numpyro inference_library_version: 0.15.2 sampling_time: 14.669591xarray.Dataset -
- index: 179
- index(index)int640 1 2 3 4 5 ... 174 175 176 177 178
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178])
- date_week(index)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', '2019-01-07T00:00:00.000000000', '2019-01-14T00:00:00.000000000', '2019-01-21T00:00:00.000000000', '2019-01-28T00:00:00.000000000', '2019-02-04T00:00:00.000000000', '2019-02-11T00:00:00.000000000', '2019-02-18T00:00:00.000000000', '2019-02-25T00:00:00.000000000', '2019-03-04T00:00:00.000000000', '2019-03-11T00:00:00.000000000', '2019-03-18T00:00:00.000000000', '2019-03-25T00:00:00.000000000', '2019-04-01T00:00:00.000000000', '2019-04-08T00:00:00.000000000', '2019-04-15T00:00:00.000000000', '2019-04-22T00:00:00.000000000', '2019-04-29T00:00:00.000000000', '2019-05-06T00:00:00.000000000', '2019-05-13T00:00:00.000000000', '2019-05-20T00:00:00.000000000', '2019-05-27T00:00:00.000000000', '2019-06-03T00:00:00.000000000', '2019-06-10T00:00:00.000000000', '2019-06-17T00:00:00.000000000', '2019-06-24T00:00:00.000000000', '2019-07-01T00:00:00.000000000', '2019-07-08T00:00:00.000000000', '2019-07-15T00:00:00.000000000', '2019-07-22T00:00:00.000000000', '2019-07-29T00:00:00.000000000', '2019-08-05T00:00:00.000000000', '2019-08-12T00:00:00.000000000', '2019-08-19T00:00:00.000000000', '2019-08-26T00:00:00.000000000', '2019-09-02T00:00:00.000000000', '2019-09-09T00:00:00.000000000', '2019-09-16T00:00:00.000000000', '2019-09-23T00:00:00.000000000', '2019-09-30T00:00:00.000000000', '2019-10-07T00:00:00.000000000', '2019-10-14T00:00:00.000000000', '2019-10-21T00:00:00.000000000', '2019-10-28T00:00:00.000000000', '2019-11-04T00:00:00.000000000', '2019-11-11T00:00:00.000000000', '2019-11-18T00:00:00.000000000', '2019-11-25T00:00:00.000000000', '2019-12-02T00:00:00.000000000', '2019-12-09T00:00:00.000000000', '2019-12-16T00:00:00.000000000', '2019-12-23T00:00:00.000000000', '2019-12-30T00:00:00.000000000', '2020-01-06T00:00:00.000000000', '2020-01-13T00:00:00.000000000', '2020-01-20T00:00:00.000000000', '2020-01-27T00:00:00.000000000', '2020-02-03T00:00:00.000000000', '2020-02-10T00:00:00.000000000', '2020-02-17T00:00:00.000000000', '2020-02-24T00:00:00.000000000', '2020-03-02T00:00:00.000000000', '2020-03-09T00:00:00.000000000', '2020-03-16T00:00:00.000000000', '2020-03-23T00:00:00.000000000', '2020-03-30T00:00:00.000000000', '2020-04-06T00:00:00.000000000', '2020-04-13T00:00:00.000000000', '2020-04-20T00:00:00.000000000', '2020-04-27T00:00:00.000000000', '2020-05-04T00:00:00.000000000', '2020-05-11T00:00:00.000000000', '2020-05-18T00:00:00.000000000', '2020-05-25T00:00:00.000000000', '2020-06-01T00:00:00.000000000', '2020-06-08T00:00:00.000000000', '2020-06-15T00:00:00.000000000', '2020-06-22T00:00:00.000000000', '2020-06-29T00:00:00.000000000', '2020-07-06T00:00:00.000000000', '2020-07-13T00:00:00.000000000', '2020-07-20T00:00:00.000000000', '2020-07-27T00:00:00.000000000', '2020-08-03T00:00:00.000000000', '2020-08-10T00:00:00.000000000', '2020-08-17T00:00:00.000000000', '2020-08-24T00:00:00.000000000', '2020-08-31T00:00:00.000000000', '2020-09-07T00:00:00.000000000', '2020-09-14T00:00:00.000000000', '2020-09-21T00:00:00.000000000', '2020-09-28T00:00:00.000000000', '2020-10-05T00:00:00.000000000', '2020-10-12T00:00:00.000000000', '2020-10-19T00:00:00.000000000', '2020-10-26T00:00:00.000000000', '2020-11-02T00:00:00.000000000', '2020-11-09T00:00:00.000000000', '2020-11-16T00:00:00.000000000', '2020-11-23T00:00:00.000000000', '2020-11-30T00:00:00.000000000', '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]') - x1(index)float640.3186 0.1124 ... 0.2803 0.4389
array([3.185800e-01, 1.123885e-01, 2.924003e-01, 7.139855e-02, 3.867452e-01, 4.717099e-02, 4.242491e-01, 3.339202e-01, 2.530703e-01, 9.380544e-01, 4.252051e-01, 3.631430e-01, 4.414947e-01, 4.231116e-01, 3.283922e-01, 9.219403e-01, 3.080155e-01, 9.094852e-01, 2.506986e-01, 2.364733e-01, 4.031379e-01, 1.471777e-01, 3.630410e-01, 1.470665e-01, 9.467043e-02, 2.592453e-01, 5.748382e-02, 2.064653e-02, 1.656360e-01, 2.140071e-01, 3.605177e-01, 1.223686e-01, 9.586840e-01, 3.219723e-01, 2.532341e-01, 6.401198e-02, 2.365532e-02, 1.831646e-01, 9.253022e-01, 9.966581e-01, 4.016896e-01, 1.737455e-01, 9.553726e-01, 3.558894e-01, 9.291813e-04, 4.378157e-01, 9.739763e-01, 9.779039e-01, 2.481417e-01, 4.056204e-01, 2.490410e-01, 5.305248e-02, 6.632172e-02, 9.193147e-02, 2.846526e-01, 3.738453e-01, 3.110337e-01, 1.082006e-02, 3.258547e-01, 4.301608e-01, 4.421900e-01, 2.689191e-01, 3.844069e-01, 3.037808e-01, 2.220925e-01, 9.840870e-01, 1.781618e-01, 1.528626e-01, 4.328122e-01, 3.807359e-01, 1.338109e-01, 2.187159e-01, 3.240347e-01, 3.666767e-01, 1.502988e-01, 9.311238e-01, 2.991991e-01, 1.593482e-01, 4.492828e-01, 9.183072e-03, 2.406173e-01, 3.965522e-02, 6.828151e-02, 2.051752e-01, 4.046401e-01, 4.391195e-01, 2.083842e-01, 3.543588e-02, 9.664747e-01, 3.240292e-01, 4.006693e-01, 1.644249e-01, 2.552044e-01, 3.868456e-01, 4.340460e-01, 2.885776e-01, 3.196821e-01, 2.036868e-01, 3.595476e-01, 2.111223e-02, 2.839621e-01, 4.292717e-01, 1.555749e-01, 1.070682e-01, 4.469580e-01, 3.530122e-01, 4.055015e-01, 9.951020e-01, 1.955521e-01, 4.211056e-01, 3.891277e-02, 2.747624e-01, 3.885517e-01, 3.981779e-01, 9.301668e-01, 2.598488e-01, 1.948209e-01, 2.582313e-01, 3.021897e-01, 1.034972e-01, 8.017010e-02, 4.159768e-01, 3.961735e-01, 4.432884e-01, 6.388822e-02, 2.569612e-01, 4.167165e-01, 1.893443e-01, 1.211688e-02, 3.072044e-01, 2.793461e-01, 1.558597e-01, 2.512598e-01, 4.156363e-01, 1.504134e-01, 4.184572e-02, 2.927102e-01, 3.916239e-01, 9.897052e-02, 2.684730e-01, 3.634846e-01, 1.853632e-01, 6.597750e-02, 3.545685e-01, 1.594227e-01, 1.819762e-01, 1.167471e-01, 3.237802e-01, 4.341229e-01, 1.089880e-01, 1.613538e-01, 9.423221e-01, 8.520326e-02, 3.258196e-01, 1.679133e-01, 3.396220e-01, 2.529019e-01, 8.648554e-02, 3.372270e-01, 1.697629e-01, 4.276049e-01, 9.104346e-01, 1.424670e-01, 1.862139e-01, 3.133712e-01, 3.993394e-01, 1.445843e-01, 1.479751e-01, 6.984356e-02, 1.984379e-01, 3.614885e-01, 2.403375e-01, 4.037403e-02, 6.745704e-02, 3.302419e-02, 1.656152e-01, 1.718822e-01, 2.802573e-01, 4.388572e-01]) - x2(index)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0
array([0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.879782, 0. , 0. , 0. , 0. , 0. , 0.964187, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.800623, 0. , 0. , 0. , 0.853527, 0. , 0. , 0.988597, 0.870475, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.974866, 0. , 0. , 0. , 0.902573, 0. , 0. , 0. , 0. , 0.994374, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.957982, 0. , 0. , 0.886047, 0.841933, 0. , 0.912537, 0. , 0. , 0.991233, 0. , 0. , 0.955818, 0.917045, 0. , 0.809044, 0. , 0. , 0. , 0.869601, 0. , 0.920853, 0. , 0. , 0. , 0. , 0.993906, 0. , 0. , 0. , 0. , 0. , 0. , 0.936657, 0.909365, 0. , 0. , 0.806883, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.893977, 0.86775 , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.839982, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.960184, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.933102, 0.915338, 0. , 0. , 0.850702, 0. , 0. , 0. , 0. , 0. , 0. , 0.908858, 0. , 0. , 0. , 0. , 0.863349, 0. , 0. , 0. ]) - event_1(index)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) - event_2(index)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) - dayofyear(index)int6492 99 106 113 ... 221 228 235 242
array([ 92, 99, 106, 113, 120, 127, 134, 141, 148, 155, 162, 169, 176, 183, 190, 197, 204, 211, 218, 225, 232, 239, 246, 253, 260, 267, 274, 281, 288, 295, 302, 309, 316, 323, 330, 337, 344, 351, 358, 365, 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84, 91, 98, 105, 112, 119, 126, 133, 140, 147, 154, 161, 168, 175, 182, 189, 196, 203, 210, 217, 224, 231, 238, 245, 252, 259, 266, 273, 280, 287, 294, 301, 308, 315, 322, 329, 336, 343, 350, 357, 364, 6, 13, 20, 27, 34, 41, 48, 55, 62, 69, 76, 83, 90, 97, 104, 111, 118, 125, 132, 139, 146, 153, 160, 167, 174, 181, 188, 195, 202, 209, 216, 223, 230, 237, 244, 251, 258, 265, 272, 279, 286, 293, 300, 307, 314, 321, 328, 335, 342, 349, 356, 363, 4, 11, 18, 25, 32, 39, 46, 53, 60, 67, 74, 81, 88, 95, 102, 109, 116, 123, 130, 137, 144, 151, 158, 165, 172, 179, 186, 193, 200, 207, 214, 221, 228, 235, 242]) - t(index)int640 1 2 3 4 5 ... 174 175 176 177 178
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178]) - y(index)float643.985e+03 3.763e+03 ... 4.676e+03
array([3984.662237, 3762.871794, 4466.967388, 3864.219373, 4441.625278, 3677.39655 , 5067.546337, 6079.099042, 4954.205369, 5865.676576, 5096.633051, 4991.542283, 4688.584845, 6536.345741, 5030.983585, 4638.690835, 4209.545798, 4876.008389, 3906.171689, 3549.862122, 4025.433955, 3223.306333, 4079.652959, 4156.435573, 3666.877227, 3853.549206, 3531.471918, 3538.882474, 4261.174492, 4604.517234, 6484.976246, 5090.872438, 6500.440707, 6434.702003, 7288.095499, 5249.095623, 4284.737104, 5924.496795, 7770.898864, 6600.77946 , 6003.922923, 5660.653329, 5872.741932, 6093.701781, 3994.215759, 4817.419327, 7795.097809, 6447.221667, 5540.679227, 4949.832359, 6379.898689, 4764.017186, 4207.851402, 4412.820267, 4346.995203, 6626.698313, 5231.24779 , 3891.281866, 6815.820147, 5047.609611, 5292.315418, 5238.732394, 4994.210219, 4563.943101, 4501.264804, 5634.63845 , 4823.482267, 4053.079383, 4489.401478, 6196.756038, 3824.920232, 3952.728449, 5958.055093, 6003.891667, 4506.606832, 7107.868714, 5686.193808, 4737.448086, 7010.952048, 4830.189854, 4771.36246 , 5998.830148, 5829.018189, 5882.675999, 7470.547013, 6745.587701, 5989.886239, 4756.549762, 8312.407544, 6954.851763, 8250.292341, 5836.582431, 5742.57082 , 5918.941634, 5338.1905 , 6815.637385, 5733.020944, 4953.495336, 5368.254186, 4222.099205, 4650.33832 , 5271.772362, 5847.256916, 6434.125096, 5835.672438, 5424.16703 , 6805.503155, 6808.850545, 5684.103102, 5920.176894, 4508.386919, 4822.651289, 5280.528394, 5215.191965, 7674.826343, 7142.737042, 5179.991406, 4687.557753, 4623.099832, 3538.864502, 3580.234766, 4361.209639, 4535.40095 , 4376.027911, 3460.328515, 4119.382089, 4450.286004, 4405.893879, 6496.500777, 4442.175602, 5309.646671, 4964.821875, 4767.041402, 6007.106943, 7341.819155, 5611.664368, 5675.764163, 6390.814723, 5567.94367 , 5850.388666, 6150.423243, 5481.444283, 6971.261665, 6117.543142, 4725.841238, 5163.385726, 4402.252814, 5629.279054, 5440.854637, 4747.483543, 4651.193911, 5678.177997, 5327.643238, 5092.777432, 4860.968432, 5312.05881 , 4716.623877, 4879.908205, 5246.096394, 7059.265755, 7451.886416, 7060.853108, 5687.376387, 6868.041442, 5894.568964, 5509.5217 , 5039.919694, 5135.043435, 4535.692947, 4358.34664 , 6457.798589, 4425.834859, 3795.152824, 3192.879593, 3553.546148, 5565.509682, 4137.651485, 4479.041351, 4675.973439])
- indexPandasIndex
PandasIndex(Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 169, 170, 171, 172, 173, 174, 175, 176, 177, 178], dtype='int64', name='index', length=179))
<xarray.Dataset> Size: 13kB Dimensions: (index: 179) Coordinates: * index (index) int64 1kB 0 1 2 3 4 5 6 7 ... 172 173 174 175 176 177 178 Data variables: date_week (index) datetime64[ns] 1kB 2018-04-02 2018-04-09 ... 2021-08-30 x1 (index) float64 1kB 0.3186 0.1124 0.2924 ... 0.1719 0.2803 0.4389 x2 (index) float64 1kB 0.0 0.0 0.0 0.0 0.0 ... 0.8633 0.0 0.0 0.0 event_1 (index) float64 1kB 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 event_2 (index) float64 1kB 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 dayofyear (index) int64 1kB 92 99 106 113 120 127 ... 214 221 228 235 242 t (index) int64 1kB 0 1 2 3 4 5 6 7 ... 172 173 174 175 176 177 178 y (index) float64 1kB 3.985e+03 3.763e+03 ... 4.479e+03 4.676e+03xarray.Dataset
Un modelo cargado está listo para ser utilizado para muestreo y predicción, aprovechando los resultados de ajuste anteriores y los datos si es necesario.
loaded_model.sample_posterior_predictive(
X, extend_idata=True, combined=False, random_seed=rng
)
Sampling: [y]
<xarray.Dataset> Size: 6MB
Dimensions: (chain: 4, draw: 1000, date: 179)
Coordinates:
* chain (chain) int64 32B 0 1 2 3
* draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999
* date (date) datetime64[ns] 1kB 2018-04-02 2018-04-09 ... 2021-08-30
Data variables:
y (chain, draw, date) float64 6MB 3.945e+03 3.424e+03 ... 5.061e+03
Attributes:
created_at: 2024-11-14T13:56:53.715774
arviz_version: 0.17.1
inference_library: pymc
inference_library_version: 5.15.1- chain: 4
- draw: 1000
- date: 179
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 5 ... 995 996 997 998 999
array([ 0, 1, 2, ..., 997, 998, 999])
- date(date)datetime64[ns]2018-04-02 ... 2021-08-30
array(['2018-04-02T00:00:00.000000000', '2018-04-09T00:00:00.000000000', '2018-04-16T00:00:00.000000000', '2018-04-23T00:00:00.000000000', '2018-04-30T00:00:00.000000000', '2018-05-07T00:00:00.000000000', '2018-05-14T00:00:00.000000000', '2018-05-21T00:00:00.000000000', '2018-05-28T00:00:00.000000000', '2018-06-04T00:00:00.000000000', '2018-06-11T00:00:00.000000000', '2018-06-18T00:00:00.000000000', '2018-06-25T00:00:00.000000000', '2018-07-02T00:00:00.000000000', '2018-07-09T00:00:00.000000000', '2018-07-16T00:00:00.000000000', '2018-07-23T00:00:00.000000000', '2018-07-30T00:00:00.000000000', '2018-08-06T00:00:00.000000000', '2018-08-13T00:00:00.000000000', '2018-08-20T00:00:00.000000000', '2018-08-27T00:00:00.000000000', '2018-09-03T00:00:00.000000000', '2018-09-10T00:00:00.000000000', '2018-09-17T00:00:00.000000000', '2018-09-24T00:00:00.000000000', '2018-10-01T00:00:00.000000000', '2018-10-08T00:00:00.000000000', '2018-10-15T00:00:00.000000000', '2018-10-22T00:00:00.000000000', '2018-10-29T00:00:00.000000000', '2018-11-05T00:00:00.000000000', '2018-11-12T00:00:00.000000000', '2018-11-19T00:00:00.000000000', '2018-11-26T00:00:00.000000000', '2018-12-03T00:00:00.000000000', '2018-12-10T00:00:00.000000000', '2018-12-17T00:00:00.000000000', '2018-12-24T00:00:00.000000000', '2018-12-31T00:00:00.000000000', '2019-01-07T00:00:00.000000000', '2019-01-14T00:00:00.000000000', '2019-01-21T00:00:00.000000000', '2019-01-28T00:00:00.000000000', '2019-02-04T00:00:00.000000000', '2019-02-11T00:00:00.000000000', '2019-02-18T00:00:00.000000000', '2019-02-25T00:00:00.000000000', '2019-03-04T00:00:00.000000000', '2019-03-11T00:00:00.000000000', '2019-03-18T00:00:00.000000000', '2019-03-25T00:00:00.000000000', '2019-04-01T00:00:00.000000000', '2019-04-08T00:00:00.000000000', '2019-04-15T00:00:00.000000000', '2019-04-22T00:00:00.000000000', '2019-04-29T00:00:00.000000000', '2019-05-06T00:00:00.000000000', '2019-05-13T00:00:00.000000000', '2019-05-20T00:00:00.000000000', '2019-05-27T00:00:00.000000000', '2019-06-03T00:00:00.000000000', '2019-06-10T00:00:00.000000000', '2019-06-17T00:00:00.000000000', '2019-06-24T00:00:00.000000000', '2019-07-01T00:00:00.000000000', '2019-07-08T00:00:00.000000000', '2019-07-15T00:00:00.000000000', '2019-07-22T00:00:00.000000000', '2019-07-29T00:00:00.000000000', '2019-08-05T00:00:00.000000000', '2019-08-12T00:00:00.000000000', '2019-08-19T00:00:00.000000000', '2019-08-26T00:00:00.000000000', '2019-09-02T00:00:00.000000000', '2019-09-09T00:00:00.000000000', '2019-09-16T00:00:00.000000000', '2019-09-23T00:00:00.000000000', '2019-09-30T00:00:00.000000000', '2019-10-07T00:00:00.000000000', '2019-10-14T00:00:00.000000000', '2019-10-21T00:00:00.000000000', '2019-10-28T00:00:00.000000000', '2019-11-04T00:00:00.000000000', '2019-11-11T00:00:00.000000000', '2019-11-18T00:00:00.000000000', '2019-11-25T00:00:00.000000000', '2019-12-02T00:00:00.000000000', '2019-12-09T00:00:00.000000000', '2019-12-16T00:00:00.000000000', '2019-12-23T00:00:00.000000000', '2019-12-30T00:00:00.000000000', '2020-01-06T00:00:00.000000000', '2020-01-13T00:00:00.000000000', '2020-01-20T00:00:00.000000000', '2020-01-27T00:00:00.000000000', '2020-02-03T00:00:00.000000000', '2020-02-10T00:00:00.000000000', '2020-02-17T00:00:00.000000000', '2020-02-24T00:00:00.000000000', '2020-03-02T00:00:00.000000000', '2020-03-09T00:00:00.000000000', '2020-03-16T00:00:00.000000000', '2020-03-23T00:00:00.000000000', '2020-03-30T00:00:00.000000000', '2020-04-06T00:00:00.000000000', '2020-04-13T00:00:00.000000000', '2020-04-20T00:00:00.000000000', '2020-04-27T00:00:00.000000000', '2020-05-04T00:00:00.000000000', '2020-05-11T00:00:00.000000000', '2020-05-18T00:00:00.000000000', '2020-05-25T00:00:00.000000000', '2020-06-01T00:00:00.000000000', '2020-06-08T00:00:00.000000000', '2020-06-15T00:00:00.000000000', '2020-06-22T00:00:00.000000000', '2020-06-29T00:00:00.000000000', '2020-07-06T00:00:00.000000000', '2020-07-13T00:00:00.000000000', '2020-07-20T00:00:00.000000000', '2020-07-27T00:00:00.000000000', '2020-08-03T00:00:00.000000000', '2020-08-10T00:00:00.000000000', '2020-08-17T00:00:00.000000000', '2020-08-24T00:00:00.000000000', '2020-08-31T00:00:00.000000000', '2020-09-07T00:00:00.000000000', '2020-09-14T00:00:00.000000000', '2020-09-21T00:00:00.000000000', '2020-09-28T00:00:00.000000000', '2020-10-05T00:00:00.000000000', '2020-10-12T00:00:00.000000000', '2020-10-19T00:00:00.000000000', '2020-10-26T00:00:00.000000000', '2020-11-02T00:00:00.000000000', '2020-11-09T00:00:00.000000000', '2020-11-16T00:00:00.000000000', '2020-11-23T00:00:00.000000000', '2020-11-30T00:00:00.000000000', '2020-12-07T00:00:00.000000000', '2020-12-14T00:00:00.000000000', '2020-12-21T00:00:00.000000000', '2020-12-28T00:00:00.000000000', '2021-01-04T00:00:00.000000000', '2021-01-11T00:00:00.000000000', '2021-01-18T00:00:00.000000000', '2021-01-25T00:00:00.000000000', '2021-02-01T00:00:00.000000000', '2021-02-08T00:00:00.000000000', '2021-02-15T00:00:00.000000000', '2021-02-22T00:00:00.000000000', '2021-03-01T00:00:00.000000000', '2021-03-08T00:00:00.000000000', '2021-03-15T00:00:00.000000000', '2021-03-22T00:00:00.000000000', '2021-03-29T00:00:00.000000000', '2021-04-05T00:00:00.000000000', '2021-04-12T00:00:00.000000000', '2021-04-19T00:00:00.000000000', '2021-04-26T00:00:00.000000000', '2021-05-03T00:00:00.000000000', '2021-05-10T00:00:00.000000000', '2021-05-17T00:00:00.000000000', '2021-05-24T00:00:00.000000000', '2021-05-31T00:00:00.000000000', '2021-06-07T00:00:00.000000000', '2021-06-14T00:00:00.000000000', '2021-06-21T00:00:00.000000000', '2021-06-28T00:00:00.000000000', '2021-07-05T00:00:00.000000000', '2021-07-12T00:00:00.000000000', '2021-07-19T00:00:00.000000000', '2021-07-26T00:00:00.000000000', '2021-08-02T00:00:00.000000000', '2021-08-09T00:00:00.000000000', '2021-08-16T00:00:00.000000000', '2021-08-23T00:00:00.000000000', '2021-08-30T00:00:00.000000000'], dtype='datetime64[ns]')
- y(chain, draw, date)float643.945e+03 3.424e+03 ... 5.061e+03
array([[[3945.38879949, 3424.33075979, 4451.24811597, ..., 4758.00984728, 4225.07416404, 4627.6748209 ], [4008.29650058, 4014.16441649, 4428.57446308, ..., 4133.52824629, 4138.54308518, 5398.75118363], [3948.71746002, 3822.47841607, 4280.91524807, ..., 4036.22500809, 4054.96606418, 4803.59118209], ..., [3865.5169094 , 4476.87288143, 4303.4792671 , ..., 4237.5481343 , 4703.73450349, 4349.89763773], [3921.38808966, 4065.8219311 , 3922.78439836, ..., 4505.71820194, 4259.59813555, 4998.65121786], [3833.47654516, 3831.47197292, 4298.36980639, ..., 4051.62155198, 4246.83777267, 5427.1051059 ]], [[4073.87681669, 3959.05328927, 4642.74319208, ..., 4634.97495815, 4303.41147678, 5049.97690408], [4213.23503015, 3527.04719373, 3919.54832464, ..., 4490.72673863, 4426.35574948, 5017.94749667], [4105.15140755, 3837.07182129, 4599.46955235, ..., 3878.84438519, 4370.50283453, 5231.04208062], ... [4485.76917784, 3447.65722306, 4277.99043044, ..., 4286.71804339, 4487.10757443, 4859.53173563], [3827.31744637, 4240.78969232, 4087.67949389, ..., 3813.00658284, 4050.36359152, 4601.22651505], [3692.47908828, 4080.97656064, 4380.71257569, ..., 3782.07718002, 4311.19765894, 4749.65794008]], [[4247.42859443, 3787.90184437, 3983.82039391, ..., 3720.08539831, 4162.17322639, 5023.71579023], [3724.04927118, 4033.87245279, 4224.30527903, ..., 4462.60597283, 4087.92989004, 5352.92233401], [3490.99659899, 4175.90852993, 4142.88533469, ..., 4332.3359473 , 4322.91633626, 4923.73244052], ..., [3865.40264061, 3421.14242987, 4336.3322681 , ..., 4499.39111573, 4385.47628202, 5136.56348802], [3722.44856597, 3383.11206383, 4092.99617351, ..., 4563.74011015, 4183.52441594, 5088.78400749], [3872.08725139, 3835.83592627, 4389.59666171, ..., 3661.4373403 , 4383.9351516 , 5061.37571561]]])
- chainPandasIndex
PandasIndex(Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 990, 991, 992, 993, 994, 995, 996, 997, 998, 999], dtype='int64', name='draw', length=1000)) - datePandasIndex
PandasIndex(DatetimeIndex(['2018-04-02', '2018-04-09', '2018-04-16', '2018-04-23', '2018-04-30', '2018-05-07', '2018-05-14', '2018-05-21', '2018-05-28', '2018-06-04', ... '2021-06-28', '2021-07-05', '2021-07-12', '2021-07-19', '2021-07-26', '2021-08-02', '2021-08-09', '2021-08-16', '2021-08-23', '2021-08-30'], dtype='datetime64[ns]', name='date', length=179, freq=None))
- created_at :
- 2024-11-14T13:56:53.715774
- arviz_version :
- 0.17.1
- inference_library :
- pymc
- inference_library_version :
- 5.15.1
az.plot_ppc(loaded_model.idata);
/Users/juanitorduz/Documents/envs/pymc-marketing-env/lib/python3.12/site-packages/arviz/stats/density_utils.py:487: UserWarning: Your data appears to have a single value or no finite values
warnings.warn("Your data appears to have a single value or no finite values")
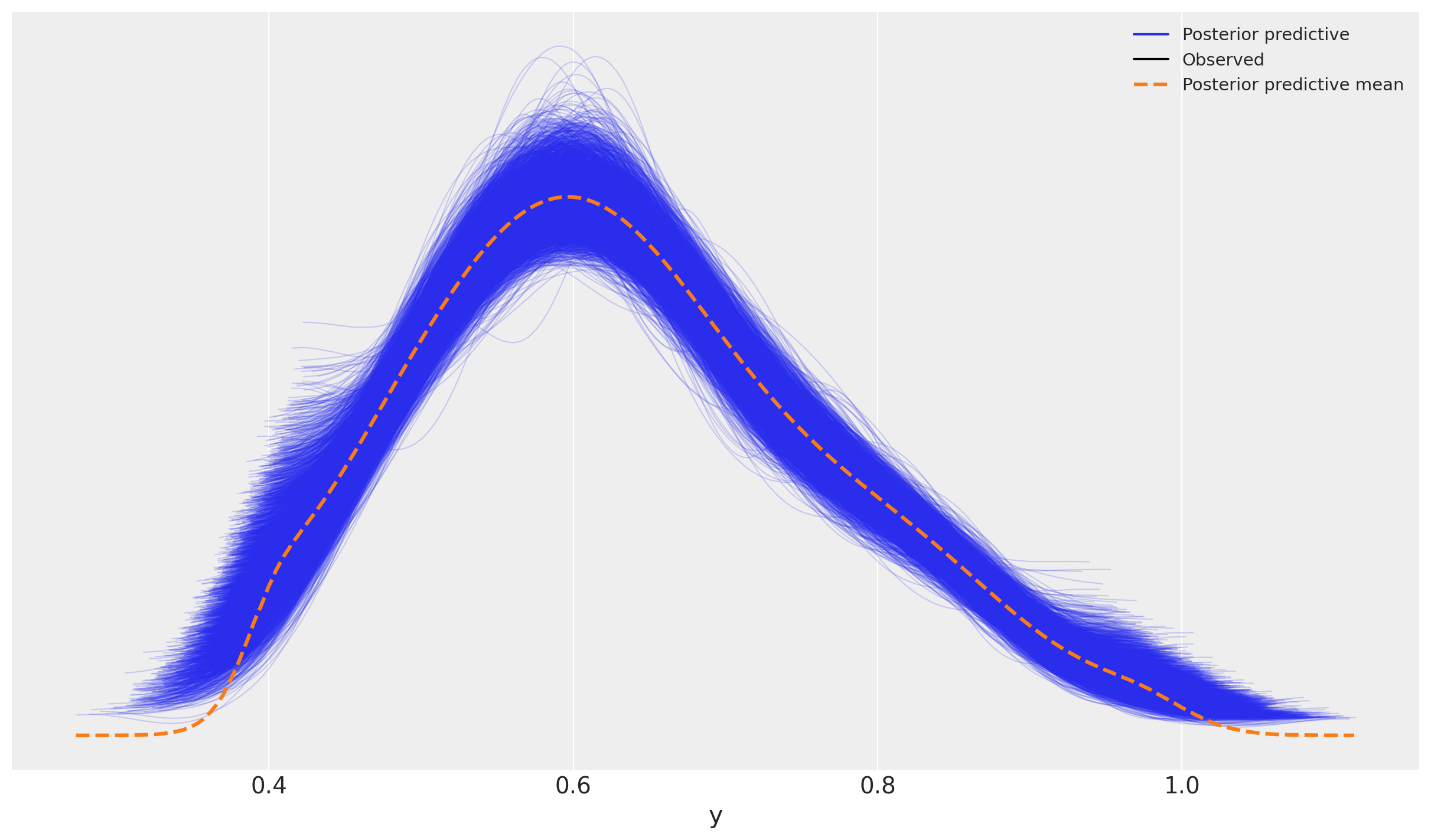
Otros modelos#
Aunque esta introducción está utilizando MMM, todos los demás modelos de PyMC-Marketing (MMM y CLV) también ofrecen estas funcionalidades.
Resumen#
Las funcionalidades de PyMC-Marketing descritas aquí están destinadas a facilitar el intercambio de modelos entre equipos de ciencia de datos sin exigir un amplio conocimiento técnico de modelado para todos los involucrados. ¡Todavía estamos iterando en nuestra API y nos encantaría recibir más comentarios de nuestros usuarios!
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Thu Nov 14 2024
Python implementation: CPython
Python version : 3.12.4
IPython version : 8.27.0
pytensor: 2.22.1
numpy : 1.26.4
matplotlib: 3.9.2
arviz : 0.17.1
pandas : 2.2.2
Watermark: 2.4.3